Pass Microsoft Certified: Azure Data Scientist Associate Certification Exam in First Attempt Guaranteed!
Get 100% Latest Exam Questions, Accurate & Verified Answers to Pass the Actual Exam!
30 Days Free Updates, Instant Download!


DP-100 Premium Bundle
- Premium File 432 Questions & Answers. Last update: Jul 25, 2026
- Training Course 80 Video Lectures
- Study Guide 608 Pages
DP-100 Premium Bundle
- Premium File 432 Questions & Answers
Last update: Jul 25, 2026 - Training Course 80 Video Lectures
- Study Guide 608 Pages
Purchase Individually

Premium File

Training Course

Study Guide








DP-100 Exam - Designing and Implementing a Data Science Solution on Azure
| Download Free DP-100 Exam Questions |
|---|
Microsoft Microsoft Certified: Azure Data Scientist Associate Certification Practice Test Questions and Answers, Microsoft Microsoft Certified: Azure Data Scientist Associate Certification Exam Dumps
All Microsoft Microsoft Certified: Azure Data Scientist Associate certification exam dumps, study guide, training courses are prepared by industry experts. Microsoft Microsoft Certified: Azure Data Scientist Associate certification practice test questions and answers, exam dumps, study guide and training courses help candidates to study and pass hassle-free!
Your Gateway to Cloud-Based Data Science with the Microsoft Certified: Azure Data Scientist Associate
The Microsoft Certified: Azure Data Scientist Associate certification represents a significant milestone for professionals operating at the intersection of cloud computing and data science. This credential validates your expertise in applying data science and machine learning principles to implement and run machine learning workloads on the Azure platform. It signifies a deep understanding of not just theoretical concepts but also the practical application of Azure's powerful suite of tools. Achieving this certification demonstrates to employers that you possess the necessary skills to manage the entire machine learning lifecycle, from data preparation and model training to deployment and monitoring, within a leading cloud environment.
This credential is more than just a certificate; it is a testament to your ability to leverage a robust, scalable, and collaborative platform to solve complex business problems. As organizations increasingly migrate their data operations to the cloud, professionals who can bridge the gap between data science and cloud infrastructure are in exceptionally high demand. The Microsoft Certified: Azure Data Scientist Associate certification is specifically designed to identify these individuals. It serves as a clear indicator of your proficiency with Azure Machine Learning, a key service that empowers data scientists to build and deploy models faster and more efficiently than ever before.
The Value Proposition of Certification
Pursuing the Microsoft Certified: Azure Data Scientist Associate certification is a strategic career move. The widespread adoption of Microsoft Azure across industries has created an ever-growing demand for skilled professionals who can manage its services. This certification directly addresses that need, making you a more attractive candidate for a wide range of roles. Data is the core asset of modern businesses, and the ability to extract meaningful insights from it is a skill that is unlikely to lose its value. Data-driven decision-making is no longer a luxury but a necessity for competitive advantage, placing certified professionals at the forefront of innovation.
Beyond enhancing your resume, this certification can lead to significant career growth and increased earning potential. It equips you with practical, in-demand skills that are directly applicable to real-world data science projects. For example, a certified professional can help a retail company build a recommendation engine or assist a financial institution in developing a fraud detection model, all within the secure and scalable Azure ecosystem. This ability to not only conceptualize but also implement and manage data products positions you as a critical asset to any organization looking to harness the power of its data.
Defining the Azure Data Scientist Role
An Azure Data Scientist is a professional who designs and implements data science solutions using Azure's comprehensive set of tools. The role extends beyond traditional data analysis; it involves the end-to-end management of machine learning models. A typical day might involve setting up and configuring an Azure Machine Learning workspace to create a collaborative environment for a data science team. This includes managing data sources, compute resources, and the overall project structure. The role is pivotal in ensuring that the infrastructure is optimized for efficient experimentation and model development, forming the foundation of all subsequent data science activities.
The core of the role revolves around experimentation and training. An Azure Data Scientist runs experiments to train machine learning models, meticulously logs metrics to evaluate performance, and troubleshoots any issues that arise. They are proficient in using the Azure Machine Learning SDK and the visual interface of the Azure Machine Learning studio designer. This dual proficiency allows them to choose the right tool for the task, whether it involves writing custom Python scripts or using a low-code graphical interface. Their work is a blend of scientific rigor and technical implementation, requiring skills in both programming and statistical analysis.
Once a promising model has been trained, the Azure Data Scientist is responsible for optimizing and managing it. This involves using advanced techniques like hyperparameter tuning with Hyperdrive to find the best possible model configuration and employing automated machine learning (AutoML) to explore different algorithms and preprocessing steps efficiently. A key part of this stage is model interpretability, where tools are used to understand why a model makes certain predictions, ensuring fairness and transparency. They also manage the model registry, versioning different models and monitoring for issues like data drift to ensure continued performance over time.
Finally, the role encompasses the critical last mile of data science: deployment and consumption. An Azure Data Scientist deploys trained models as web services that can be consumed by other applications, making the model's predictions available in real-time. They are also responsible for creating batch inference pipelines for scoring large volumes of data. This requires a solid understanding of production compute targets, security considerations, and troubleshooting deployment issues. They ensure that the machine learning models deliver tangible business value by integrating them seamlessly into operational workflows, completing the full lifecycle from concept to production.
Prerequisites and Foundational Knowledge
While Microsoft does not mandate any prior certifications to sit for the DP-100 exam, it does recommend a certain level of foundational knowledge for success. Candidates should have a solid understanding of data science principles and experience using Python with common data science libraries such as pandas, NumPy, Matplotlib, and Scikit-learn. Experience in training and deploying machine learning models is also highly recommended. The exam is not designed for complete beginners but rather for those who have some practical experience and want to validate their skills specifically on the Azure platform.
Microsoft suggests that candidates may benefit from first obtaining the Azure Data Fundamentals (DP-900) or even the Azure AI Fundamentals (AI-900) certifications. While optional, these can provide a strong baseline understanding of cloud data services and artificial intelligence concepts on Azure. More directly, the content previously associated with the "Designing and Implementing a Data Science Solution on Azure" course serves as an excellent primer. Familiarity with core Azure services and the Azure portal is beneficial, as is a conceptual understanding of how cloud resources like virtual machines and storage are provisioned and managed.
The ideal candidate has practical experience with the entire machine learning lifecycle. This includes data exploration and preparation, feature engineering, model training and evaluation, and deployment. You should be comfortable with concepts like supervised and unsupervised learning, classification, regression, and clustering. The Microsoft Certified: Azure Data Scientist Associate exam will test your ability to apply this knowledge within the specific context of the Azure Machine Learning service. Therefore, hands-on experience with the platform, even through free trial accounts or guided labs, is arguably one of the most critical prerequisites for passing the exam.
Navigating Your Certification Path
Your journey to becoming a Microsoft Certified: Azure Data Scientist Associate is centered around a single comprehensive exam: the Exam DP-100: Designing and Implementing a Data Science Solution on Azure. This exam is the sole requirement for earning the certification. The path to success involves a structured approach to learning the specific skills measured in the exam. This series will serve as your guide, breaking down the complex topics into manageable sections. We will explore each of the four major skill domains in detail, providing the insights you need to build a robust study plan.
The first step in your journey is to thoroughly understand the exam objectives. Microsoft provides a detailed skills outline which is the definitive source for what you need to know. This outline is divided into four main sections: setting up an Azure Machine Learning workspace, running experiments and training models, optimizing and managing models, and finally, deploying and consuming models. Each of these sections has a specific weighting, indicating its relative importance on the exam. A successful strategy involves allocating your study time in proportion to these weights, ensuring you have deep knowledge in the more heavily tested areas.
After familiarizing yourself with the objectives, the next phase is hands-on practice. Theoretical knowledge alone is insufficient to pass the DP-100 exam. You must be able to apply your understanding within the Azure Machine Learning studio and using the Python SDK. This means creating your own workspaces, running experiments, deploying models, and troubleshooting common problems. Microsoft Learn offers free, self-paced learning paths with interactive labs that are an invaluable resource. This practical experience is what solidifies your understanding and prepares you for the performance-based questions you may encounter on the actual exam.
The Core: Azure Machine Learning Service
At the heart of the Microsoft Certified: Azure Data Scientist Associate certification is the Azure Machine Learning service. This is a cloud-based environment that provides a comprehensive platform for managing the end-to-end machine learning lifecycle. It is designed for data scientists and machine learning engineers of all skill levels, offering both code-first (SDK/CLI) and low-code/no-code (designer, AutoML) experiences. Understanding the architecture and components of this service is fundamental to passing the DP-100 exam and succeeding in the role of an Azure Data Scientist.
The primary organizational unit in the service is the Azure Machine Learning workspace. The workspace is a centralized place to work with all the artifacts you create during your machine learning projects. It helps your team collaborate by sharing experiments, models, compute targets, and datastores. It also provides history, logging, and security features like role-based access control, ensuring a governed and auditable environment for your data science activities. Setting up and managing this workspace correctly is the first major skill area tested on the exam, as it is the foundation for everything that follows.
Within a workspace, you work with several key components. Datastores are references to your storage services on Azure, such as Blob Storage or Data Lake Storage, allowing you to securely connect to your data. Datasets are references to the specific data in those datastores, which you can then use in your experiments. Compute targets represent the computational resources where you run your training scripts or host your model deployments. These can range from your local machine to powerful GPU-enabled clusters in the cloud. Mastering the creation and management of these components is crucial for building efficient and scalable machine learning solutions on Azure.
Understanding the DP-100 Exam Structure
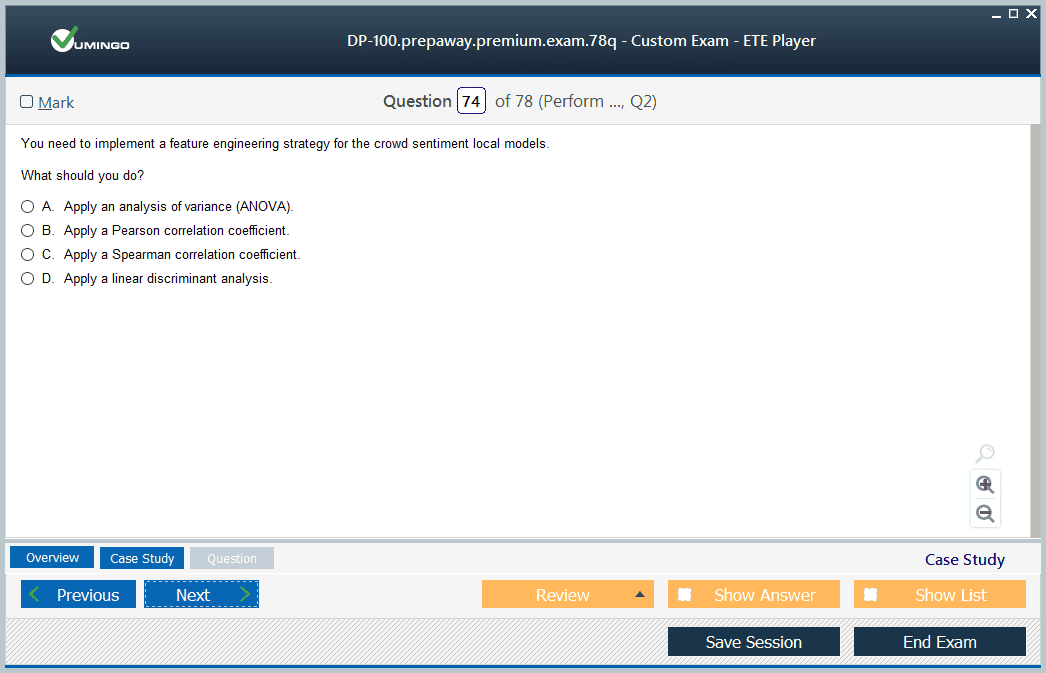
The Exam DP-100 is designed to be a rigorous test of your practical skills. It typically consists of 40 to 60 questions that you must answer within a 120-minute time frame. The questions are not just simple multiple-choice; the format can include multiple response, drag-and-drop, yes/no questions, and detailed case studies. The case studies present a business problem and a set of related questions, requiring you to analyze the situation and apply your knowledge to recommend a solution. This variety of question types ensures a thorough evaluation of your understanding from different perspectives.
To pass the exam, you need to achieve a score of 700 or greater on a scale of 1 to 1000. This is not a simple percentage; it is a scaled score that accounts for the varying difficulty of the questions. The exam costs $165 USD, although prices may vary based on your region. It is available in numerous languages, including English, Chinese, Japanese, Korean, German, and French, among others. Once you earn the certification, it is valid for one year. To maintain your Microsoft Certified: Azure Data Scientist Associate credential, you will need to complete a free online renewal assessment annually.
The exam content is broken down into four distinct domains. "Set up an Azure Machine Learning workspace" accounts for 30-35% of the questions. "Run experiments and train models" makes up 25-30%. "Optimize and manage models" constitutes 20-25%. Finally, "Deploy and consume models" also covers 20-25%. This breakdown is your most important guide for studying. It clearly indicates that having a deep understanding of setting up the environment and running experiments is paramount, as these two areas together can account for over half of the exam questions.
Deep Dive into Azure Machine Learning Workspaces
The foundational skill for any professional pursuing the Microsoft Certified: Azure Data Scientist Associate certification is the ability to effectively set up and manage an Azure Machine Learning workspace. This workspace is the central hub for all machine learning activities, providing a collaborative and governed environment. Creating a workspace involves more than just clicking a button in the Azure portal; it requires thoughtful consideration of associated resources. When you create a workspace, Azure automatically provisions several other key resources, including a storage account, a container registry, a Key Vault, and an Application Insights instance.
The Azure Storage Account serves as the default datastore for the workspace, holding notebooks, datasets, and model outputs. The Azure Container Registry is used to store the Docker images that are created when you deploy your trained models. The Azure Key Vault is a critical component for security, used to manage secrets such as authentication keys and connection strings for your datastores. Finally, Application Insights provides a powerful monitoring service for your deployed models, allowing you to track requests, response times, and failure rates. Understanding the role of each of these linked resources is crucial for both the exam and real-world application.
Configuring the workspace settings is another critical task. This includes managing access control through roles, which ensures that different team members have the appropriate level of permissions. You might assign a data scientist role with permissions to run experiments and a machine learning engineer role with permissions to deploy models to production. You can also configure network settings, such as placing the workspace within a virtual network for enhanced security. The ability to manage these settings using the Azure Machine Learning studio, a web-based UI, is a core competency for an Azure Data Scientist.
Managing Data Objects: Datastores and Datasets
Once your workspace is established, the next step in any machine learning project is to connect to your data. In Azure Machine Learning, this is accomplished through two key objects: datastores and datasets. A datastore is essentially a pointer or a connection reference to an existing Azure storage service. It does not store the data itself but securely stores the connection information, such as your account key or service principal credentials, in the Key Vault associated with your workspace. This abstraction allows you to access your data without having to embed sensitive credentials directly in your scripts.
You can register various types of Azure storage services as datastores, including Azure Blob Storage, Azure Data Lake Storage Gen1 and Gen2, and Azure SQL Database, among others. Registering and maintaining these datastores is a frequent task for an Azure Data Scientist. For the Microsoft Certified: Azure Data Scientist Associate exam, you need to know how to create these connections through both the studio interface and the Python SDK. Understanding the difference between authentication methods, like key-based versus token-based, is also important for security and governance.
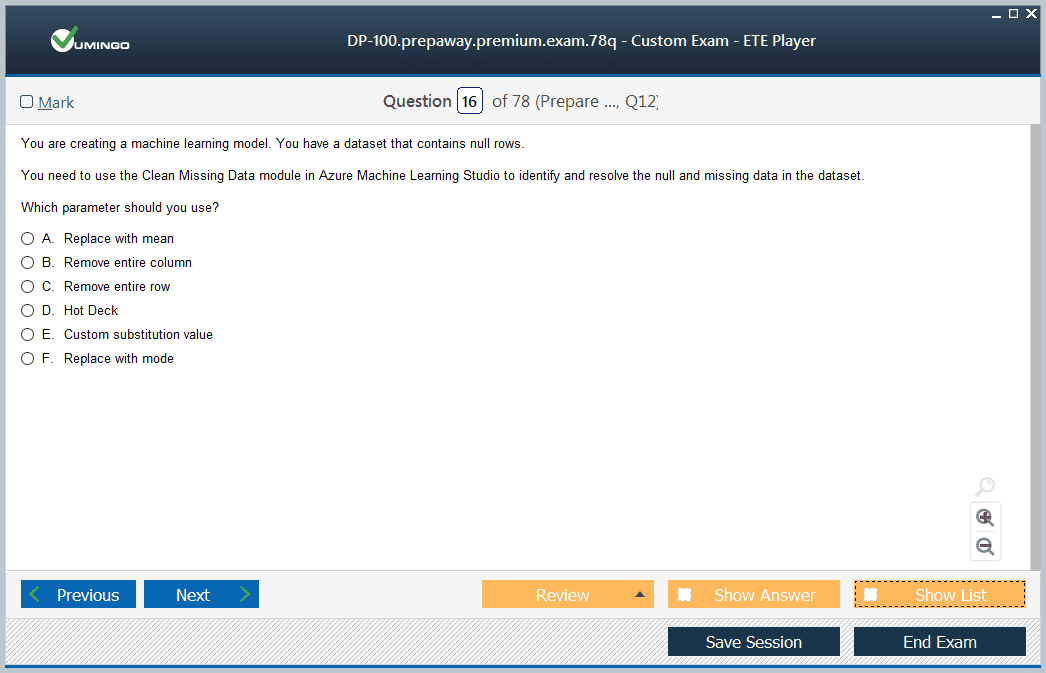
After registering a datastore, you create datasets to interact with the data. A dataset is a reference to a specific data source in a datastore, which can be a single file, multiple files, or a database table. Azure Machine Learning supports two types of datasets: Tabular and File. A Tabular dataset represents data in a structured, table-like format, which you can load into a pandas DataFrame. A File dataset, on the other hand, represents one or more files, which you can download or mount to your compute target. Creating, versioning, and managing these datasets is a fundamental skill for ensuring data reproducibility and traceability in your experiments.
Configuring Experiment Compute Contexts
Machine learning experiments, especially model training, are computationally intensive tasks. Azure Machine Learning provides a flexible framework for managing the compute resources, known as compute targets, where these tasks are executed. A key competency for the Microsoft Certified: Azure Data Scientist Associate is determining the appropriate compute specifications for a given workload. This involves choosing the right virtual machine size, deciding between CPU and GPU resources, and configuring scaling settings for compute clusters. An incorrect choice can lead to unnecessarily high costs or excessively long training times.
The simplest compute target is a compute instance. This is a cloud-based, managed workstation that comes pre-packaged with common data science tools, IDEs like Jupyter and Visual Studio Code, and the necessary SDKs. It's an ideal environment for development, data exploration, and debugging your training scripts before submitting them to more powerful compute targets. You need to know how to create and manage the lifecycle of a compute instance, including starting, stopping, and deleting it to control costs effectively. It serves as your personal development box in the cloud.
For actual model training at scale, you will typically use a compute cluster. A compute cluster is a managed pool of virtual machines that can automatically scale up or down based on the number of jobs submitted. This is a cost-effective and powerful option for running your experiments. You can configure the minimum and maximum number of nodes, the VM size for each node, and an idle timeout period. For the exam, you must understand how to create these clusters for both training and batch inferencing, ensuring you can provide the necessary computational power for any machine learning task.
Running Experiments with the Azure ML SDK
The Azure Machine Learning SDK for Python is a primary tool for a code-first data science experience. The Microsoft Certified: Azure Data Scientist Associate exam heavily tests your ability to use the SDK to programmatically interact with your workspace. This includes creating and running experiments. An experiment is a logical container for all the trials, or runs, that you conduct for a particular machine learning task. For example, you might have an experiment dedicated to training a customer churn prediction model, where each run tests a different algorithm or set of hyperparameters.
To run an experiment, you typically start by writing a Python training script. This script contains your data loading, preprocessing, model training, and evaluation logic. You then use the SDK to configure and submit this script as a run. This involves creating a ScriptRunConfig object, where you specify the training script to execute, the compute target to run it on, and the Python environment with all the necessary dependencies. You must be comfortable with this entire workflow, from writing the script to configuring its execution environment and submitting the run to the workspace.
A crucial part of using the SDK is consuming data from your registered datasets. Your training script should not hardcode paths to data files. Instead, you should use the SDK to pass a reference to a dataset as an input to your run. The Azure Machine Learning service then handles the task of making this data available on the compute target, either by downloading it or mounting it. This practice decouples your code from the data's physical location, making your scripts more portable and your experiments more reproducible, a key principle of good MLOps.
Leveraging the Azure Machine Learning Designer
For those who prefer a more visual, low-code approach, Azure Machine Learning offers the designer. The designer provides a drag-and-drop interface for building and training machine learning models. The Microsoft Certified: Azure Data Scientist Associate certification requires you to be proficient in this tool as well. You will need to know how to create a training pipeline by dragging datasets and modules onto a canvas and connecting them to define the flow of data and operations. This is an excellent tool for rapid prototyping and for users who are less comfortable with extensive coding.
The designer's canvas is populated with a wide array of pre-built modules. These modules cover the entire machine learning workflow, including data input and output, data transformation, feature selection, model training, and model scoring. For example, you might start with a dataset module, connect it to a "Select Columns" module to choose your features, then link that to a "Split Data" module to create training and testing sets. This visual flow makes the entire process intuitive and easy to follow. You need to be familiar with the common modules and how to configure their parameters.
While the designer offers many pre-built modules, it also provides flexibility. You can create your own custom logic by using the "Execute Python Script" or "Execute R Script" modules. This allows you to insert custom code for data preprocessing or feature engineering that may not be available in the standard modules. Understanding how to use these custom code modules is important for handling more complex or specialized scenarios. The designer thus offers a powerful balance between the ease of use of a graphical interface and the flexibility of custom code.
Generating and Tracking Experiment Metrics
A fundamental aspect of machine learning is the ability to evaluate and compare different models. The Microsoft Certified: Azure Data Scientist Associate must be adept at generating and analyzing metrics from experiment runs. Whether you are using the SDK or the designer, the Azure Machine Learning service provides robust capabilities for logging metrics. In an SDK-based run, you can use the run context object (run.log()) within your training script to log any value you wish to track, such as accuracy, AUC, or root mean squared error.
These logged metrics are not just numbers stored in a text file; they are structured data that can be visualized and queried within the Azure Machine Learning studio. After a run completes, you can go to the studio to view charts and tables of your logged metrics. If you log a metric over multiple epochs of training, you can see a chart of how the metric changed over time. This is invaluable for diagnosing training issues, such as overfitting, and for comparing the performance of different runs side-by-side to identify the best-performing model.
Beyond metrics, you can also log other outputs, such as images, files, or even entire trained model objects. For instance, you could log a confusion matrix plot as an image or a list of important features as a text file. These artifacts are stored with the run and can be easily retrieved from the studio. The studio also provides access to the logs and error streams from your run, which is the primary tool for troubleshooting failed runs. The ability to effectively use the logging and output features of a run is essential for debugging and managing your machine learning experiments efficiently.
Automating Model Training with Pipelines
As your machine learning projects become more complex, you will often need to orchestrate a sequence of steps. For example, a complete workflow might involve a data preparation step, a model training step, and a model evaluation step. Azure Machine Learning pipelines allow you to define and automate these multi-step workflows. The Microsoft Certified: Azure Data Scientist Associate certification expects you to be able to create these pipelines using the SDK. A pipeline is a reusable workflow that can be triggered on a schedule or by data changes, forming a key component of MLOps.
Each step in a pipeline can run on a different compute target and can use a different set of dependencies. For instance, your data preparation step might run on a CPU-based compute cluster, while your deep learning model training step runs on a GPU-enabled cluster. This flexibility allows you to optimize your use of resources. A critical concept in pipelines is the ability to pass data between steps. You can configure a pipeline so that the output of one step becomes the input for a subsequent step, creating a seamless flow of data through your workflow.
Once a pipeline is defined, you can publish it as a REST endpoint. This allows you to trigger the pipeline from external systems, integrating your machine learning workflow into broader business processes. You can also run and monitor your pipeline runs directly from the Azure Machine learning studio. The studio provides a graphical representation of your pipeline, allowing you to inspect the inputs, outputs, and logs for each individual step. This makes it much easier to manage and troubleshoot complex, automated workflows.
Creating Optimal Models with Automated ML
A significant challenge in machine learning is selecting the right algorithm and preprocessing steps for a given dataset. The process, known as model selection, can be time-consuming and requires deep expertise. The Microsoft Certified: Azure Data Scientist Associate needs to be proficient with Azure's Automated Machine Learning (AutoML) feature, which automates this entire process. AutoML iterates through various combinations of algorithms, feature engineering steps, and hyperparameter settings to find the best possible model for your specific data and task.
You can interact with AutoML through two primary interfaces: the user-friendly UI in the Azure Machine Learning studio and the more flexible Python SDK. The studio interface provides a guided, wizard-like experience where you select your dataset, specify the target column, and choose the task type, such as classification, regression, or forecasting. The SDK offers more granular control, allowing you to programmatically configure the experiment, specify constraints like timeout duration, and integrate the AutoML run into larger automated workflows. You must be comfortable with both methods for the exam.
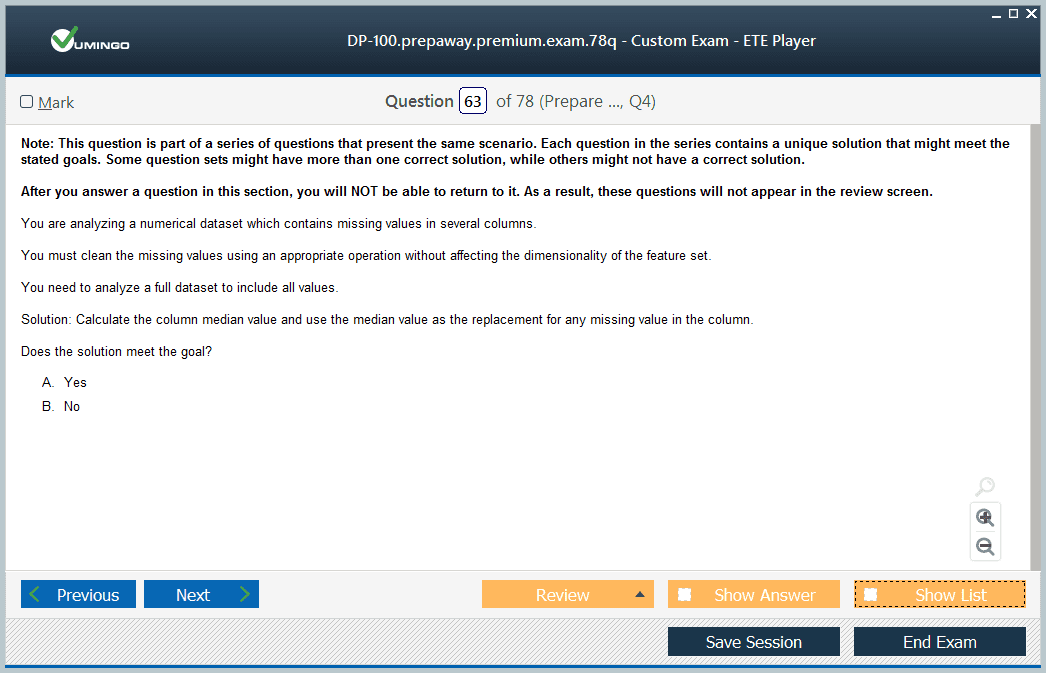
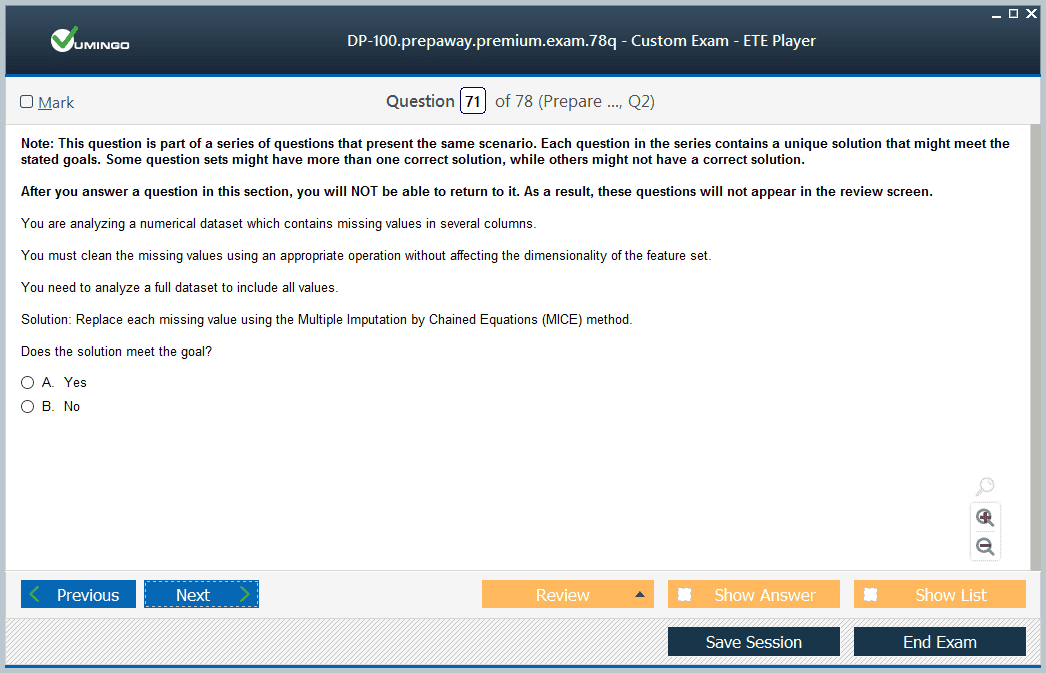
A key part of using AutoML effectively is understanding its configuration options. You can select pre-processing options, such as how to handle missing data or how to encode categorical features. You can also determine which algorithms AutoML should consider in its search, or you can let it choose from its full suite of supported models. Most importantly, you must define a primary metric, like accuracy or AUC, which AutoML will use to score and rank the models it trains. After the run completes, you can easily retrieve the best model and examine its properties, including its performance and the specific steps in its pipeline.
Fine-Tuning Models with Hyperdrive
While AutoML is excellent for finding a good baseline model quickly, sometimes you need more control over the hyperparameter tuning process for a specific algorithm. For this, Azure Machine Learning provides a service called Hyperdrive. Hyperparameter tuning is the process of finding the optimal values for parameters that are not learned from the data, such as the learning rate in a neural network or the number of trees in a random forest. The Microsoft Certified: Azure Data Scientist Associate must understand how to use Hyperdrive to perform this optimization systematically.
Hyperdrive allows you to define a search space for your hyperparameters. This involves specifying the range of values to explore for each parameter. You then need to select a sampling method. Grid sampling exhaustively tries every possible combination, which can be computationally expensive. Random sampling, on the other hand, randomly selects values from the search space. More advanced methods like Bayesian sampling use the results from previous runs to intelligently choose the next set of values to try, often finding the optimal combination more efficiently.
To prevent wasting resources on poorly performing trials, Hyperdrive supports early termination policies. For example, a Bandit policy will stop runs whose primary metric is significantly worse than the best-performing runs so far. You define the primary metric you want to optimize, just as with AutoML. After the Hyperdrive run is complete, you can easily identify the run that produced the best result and retrieve the corresponding model with its optimal hyperparameter values. This systematic approach is far more effective than manual trial and error.
Interpreting Models with Model Explainers
As machine learning models become more complex, they can often behave like "black boxes," making it difficult to understand how they arrive at their predictions. Model interpretability is becoming increasingly important for debugging, ensuring fairness, and building trust with stakeholders. The Microsoft Certified: Azure Data Scientist Associate is expected to know how to use the model explainability features integrated into Azure Machine Learning. These tools help you understand the global behavior of your model and the local predictions for individual data points.
The Azure Machine Learning SDK includes an interpretability package that provides access to various model explainers, often wrappers around popular open-source libraries like SHAP (SHapley Additive exPlanations). To generate explanations, you first select an appropriate explainer for your model and task. For example, there are specific explainers designed for tree-based models or for deep neural networks. You then use this explainer to generate feature importance data, which tells you which features had the most significant impact on the model's predictions overall.
This global feature importance helps you understand the general behavior of your model. For instance, you might discover that a customer's monthly income is the most important feature for predicting loan defaults. You can also generate local feature importance for a single prediction, explaining why the model made a specific decision for a particular customer. This is crucial for transparency and for complying with regulations that may require an explanation for an automated decision. The Azure Machine Learning studio provides rich visualizations for exploring these model explanations.
The Model Management Lifecycle
Once you have a trained and optimized model that you are satisfied with, the next step is to manage it effectively. The Microsoft Certified: Azure Data Scientist Associate must be proficient in using the model registry within the Azure Machine Learning workspace. The model registry is a centralized repository where you can store, version, and tag your trained models. When you register a model, you package it with its metadata, such as the experiment run it came from, its performance metrics, and any custom tags you want to apply.
Registering a model is the first step toward deploying it into production. It creates a traceable lineage from the training data and script all the way to the final deployed service. This is a critical principle of MLOps, as it ensures reproducibility and allows you to easily roll back to a previous version if a new model introduces problems. You can have multiple versions of the same model in the registry, allowing you to track its evolution over time as you retrain it with new data or different algorithms.
Beyond registration, effective model management also involves monitoring. Once a model is deployed, you need to monitor its usage to understand how it is being used and to track its performance in the real world. A crucial aspect of this is monitoring for data drift. Data drift occurs when the statistical properties of the data being sent to the model for prediction change over time compared to the data it was trained on. This can significantly degrade model performance. Azure Machine Learning provides tools to detect data drift and trigger alerts so you can take corrective action, such as retraining your model.
Creating Production Compute Targets
Deploying a model means making it available for other applications to consume its predictions. The first step in this process is creating a production compute target where the model will be hosted. The Microsoft Certified: Azure Data Scientist Associate needs to be able to evaluate the various compute options available for deployment and select the most appropriate one based on the specific use case. The choice of compute target will depend on factors like the expected request volume, latency requirements, and cost considerations.
For real-time inferencing, where you need immediate predictions, the most common choice is Azure Kubernetes Service (AKS). AKS provides a robust, scalable, and fully managed Kubernetes cluster that is ideal for hosting production-grade web services. It supports features like autoscaling, which can automatically adjust the number of service replicas based on CPU load or request traffic, ensuring high availability and responsive performance. For simpler scenarios or development and testing, you can also deploy to Azure Container Instances (ACI), which is a lightweight option for deploying single containers without orchestrator overhead.
Security is a paramount consideration when creating production compute targets. You must understand how to secure your deployed services. This can involve configuring authentication to control who can access your model's endpoint, using SSL to encrypt traffic, and placing the compute target within a virtual network to isolate it from the public internet. The exam will test your knowledge of these security best practices, ensuring you can deploy models in a way that protects both the model itself and the data it processes.
Deploying a Model as a Service
After preparing the compute target, the next step is to deploy your registered model as a service. This process typically involves several key components. First, you need an entry script, often called a score script. This is a Python script that contains the logic for loading your model and using it to make a prediction on incoming data. It must have an init() function, which is run once when the service starts to load the model into memory, and a run() function, which is executed for each prediction request.
Next, you need to define the software environment required to run your entry script. This includes specifying all the Python packages, such as scikit-learn or TensorFlow, that your model and script depend on. This environment is then used to build a Docker image that contains your script, your model files, and all the necessary dependencies. This containerization ensures that your model runs in a consistent and reproducible environment, regardless of where it is deployed.
Finally, you define the deployment configuration. This specifies the CPU and memory resources to allocate for your service and, if deploying to AKS, the number of replicas for autoscaling. You then combine the model, entry script, environment, and deployment configuration to deploy the service to your chosen compute target. Once deployed, the service is exposed via a REST endpoint. Consuming the service is as simple as sending an HTTP request with the input data to this endpoint and receiving the model's prediction in the response. You must also know how to troubleshoot common deployment container issues by examining the service logs.
Creating Pipelines for Batch Inferencing
Not all prediction scenarios require real-time responses. In many cases, you may need to score a large volume of data on a periodic basis, such as generating daily sales forecasts or scoring a batch of new customer leads overnight. For these scenarios, a real-time web service is not the most efficient solution. Instead, you create a pipeline for batch inferencing. The Microsoft Certified: Azure Data Scientist Associate must know how to build and publish these batch scoring pipelines.
A batch inferencing pipeline is similar in structure to a training pipeline. It consists of one or more steps, typically starting with a step to read the input data, followed by a step that uses a registered model to score the data. The output of the scoring step is then written to a datastore for later use. You can build these pipelines using either the designer or the SDK. The key difference from a training pipeline is that instead of a training script, the main step contains a scoring script.
Once you have created your batch inferencing pipeline, you can publish it. Publishing a pipeline creates a reusable workflow with a REST endpoint, just like a training pipeline. You can then trigger this pipeline on a schedule, for example, to run every night at 2 AM. When the pipeline runs, it will process the latest input data and generate the new batch of predictions. Understanding how to create, publish, and run these pipelines is essential for operationalizing your models for large-scale, non-interactive scoring tasks.
Official Microsoft Learning Path
The single most important resource for preparing for the Microsoft Certified: Azure Data Scientist Associate exam is the official learning path provided by Microsoft itself. This collection of modules, available on the Microsoft Learn platform, is meticulously designed to align with the skills measured on the DP-100 exam. The learning path is completely free and provides a structured, self-paced way to acquire the necessary knowledge. It breaks down the complex world of Azure Machine Learning into digestible modules, each focusing on a specific topic.
The learning path, titled "Design and implement a data science solution on Azure," consists of multiple modules that cover the entire machine learning lifecycle. It starts with the basics of creating an Azure Machine Learning workspace and progresses through topics like working with data and compute, running experiments, using the designer, and leveraging automated machine learning. It then covers more advanced topics like hyperparameter tuning, model interpretability, and the different options for model deployment. Each module is a mix of textual content, conceptual explanations, and, most importantly, hands-on labs.
These interactive labs are the cornerstone of the Microsoft Learn experience. They provide you with a temporary Azure environment, allowing you to practice the concepts you've just learned without incurring any costs on your own subscription. This hands-on practice is absolutely critical for the DP-100 exam, which tests your practical ability to perform tasks in Azure. Completing every module and every lab in the official learning path is the best first step you can take in your preparation. It ensures you have covered all the required topics directly from the source.
Instructor-Led Training Options
While self-paced learning is an excellent option for many, some candidates prefer a more structured and interactive learning environment. For these individuals, Microsoft also offers official instructor-led training courses. The primary course for this certification is Course DP-100T01: Designing and Implementing a Data Science Solution on Azure. This is typically a multi-day course led by a Microsoft Certified Trainer who can provide expert guidance, answer your specific questions, and offer deeper insights into the material.
The instructor-led format provides a different learning dynamic. It allows for real-time collaboration with both the instructor and other students, which can be very beneficial for understanding complex topics. The curriculum of the paid course is closely aligned with the free Microsoft Learn path but is often supplemented with additional examples, discussions, and the instructor's personal experience. This can be particularly helpful for clarifying tricky concepts or for understanding the nuances of how different services work together in a real-world context.
Choosing between the free online courses and the paid instructor-led training is a personal decision based on your learning style, budget, and timeline. The paid course offers a more intensive and guided experience, which can accelerate your learning process. However, the free Microsoft Learn path provides all the necessary content to pass the exam, provided you have the discipline to work through it diligently. Many successful candidates use a hybrid approach, starting with the free online material and then perhaps attending a paid course for a final, intensive review before the exam.
Third-Party Training Providers
Beyond the official Microsoft resources, a vibrant ecosystem of third-party training providers offers courses and materials for the Microsoft Certified: Azure Data Scientist Associate certification. Platforms like Pluralsight, A Cloud Guru, and Whizlabs offer comprehensive video courses, practice tests, and hands-on lab environments specifically designed for the DP-100 exam. These courses are often created by industry experts and can provide a different perspective on the material, which can help reinforce your learning.
These platforms often have distinct advantages. For instance, some may offer more extensive sets of practice questions that closely mimic the format and difficulty of the real exam. This can be an invaluable tool for assessing your readiness and identifying your weak areas. Others might provide more complex, project-based labs that challenge you to apply your skills in a more integrated way than the introductory labs on Microsoft Learn. These resources can be an excellent supplement to the official curriculum.
When choosing a third-party course, it is important to do your research. Look for courses that have been recently updated to reflect the latest version of the DP-100 exam objectives. Reading reviews from other students can also provide insight into the quality of the instruction and the effectiveness of the materials. While these courses come at a cost, many candidates find that the investment is worthwhile for the structured content and additional practice opportunities they provide, significantly boosting their confidence before taking the exam.
The Importance of Hands-On Experience
It is impossible to overstate the importance of hands-on experience when preparing for the Microsoft Certified: Azure Data Scientist Associate exam. This is not an exam you can pass by simply memorizing facts or watching videos. The questions are designed to test your ability to apply your knowledge to solve practical problems within the Azure Machine Learning environment. You need to have spent considerable time working directly with the service, whether through the studio UI or the Python SDK.
The best way to gain this experience is to build your own projects. Start with a free Azure account, which provides a certain amount of credit and free services for a limited time. Find a dataset that interests you and try to take it through the entire machine learning lifecycle. Create a workspace, upload your data, run an experiment to train a model, register the best version, and then deploy it as a web service. This process will force you to encounter and solve the real-world challenges that are often the basis for exam questions.
As you work on your projects, make a conscious effort to use both the SDK and the studio designer. The exam can ask questions about either interface, so you need to be comfortable with both. Try to perform the same task, like training a model, using both methods. This will give you a deeper understanding of how the different components of the service work together. Don't be afraid to experiment with different settings and options. The more you explore the platform and its capabilities, the better prepared you will be for whatever the exam throws at you.
Leveraging the Official Documentation
Another invaluable and often underutilized resource is the official Microsoft documentation for Azure Machine Learning. While the Microsoft Learn path provides a structured learning curriculum, the official documentation serves as the comprehensive reference manual for the service. Whenever you have a specific question about a particular function, class, or parameter in the SDK, or a setting in the studio, the documentation is the definitive place to find the answer.
The documentation is incredibly detailed and includes conceptual articles, how-to guides, tutorials, and a complete API reference. It is an essential companion to your hands-on practice. For example, while you are writing a script to submit a Hyperdrive run, you can have the documentation page for the HyperdriveConfig class open to understand all the available configuration options for sampling methods and termination policies. This practice of cross-referencing with the documentation will solidify your understanding of the fine-grained details of the service.
For the Microsoft Certified: Azure Data Scientist Associate exam, being able to navigate and find information in the documentation is a skill in itself. During the actual exam, you may have access to the Microsoft Learn and documentation websites. Knowing how to quickly search for and locate relevant information can be a significant advantage if you encounter a question about a niche topic you are unsure about. Therefore, you should make it a regular habit to consult the documentation throughout your study process, not just as a last resort.
Microsoft Certified: Azure Data Scientist Associate certification practice test questions and answers, training course, study guide are uploaded in ETE files format by real users. Study and pass Microsoft Microsoft Certified: Azure Data Scientist Associate certification exam dumps & practice test questions and answers are the best available resource to help students pass at the first attempt.



