- Home
- Microsoft Certifications
- DP-900 Microsoft Azure Data Fundamentals Dumps
Pass Microsoft Azure Data DP-900 Exam in First Attempt Guaranteed!
Get 100% Latest Exam Questions, Accurate & Verified Answers to Pass the Actual Exam!
30 Days Free Updates, Instant Download!


DP-900 Premium Bundle
- Premium File 332 Questions & Answers. Last update: Jul 07, 2026
- Training Course 32 Video Lectures
- Study Guide 672 Pages








Last Week Results!

Includes question types found on the actual exam such as drag and drop, simulation, type-in and fill-in-the-blank.

Based on real-life scenarios similar to those encountered in the exam, allowing you to learn by working with real equipment.

Developed by IT experts who have passed the exam in the past. Covers in-depth knowledge required for exam preparation.
All Microsoft Azure Data DP-900 certification exam dumps, study guide, training courses are Prepared by industry experts. PrepAway's ETE files povide the DP-900 Microsoft Azure Data Fundamentals practice test questions and answers & exam dumps, study guide and training courses help you study and pass hassle-free!
Ace the DP-900: Essential Azure Data Concepts Explained
The DP-900 exam certification, also known as Microsoft Azure Data Fundamentals, is designed for individuals who want to demonstrate foundational knowledge of core data concepts and how they are implemented using Microsoft Azure data services. This certification is ideal for beginners who are new to cloud data services and want to establish a solid understanding before pursuing more advanced Azure certifications.
DP-900 covers essential data concepts such as relational and non-relational data, big data, and analytics. It also introduces candidates to the basics of Azure data services including databases, analytics, and data warehousing.
Why Pursue The DP-900 Exam Certification?
Pursuing the DP-900 exam certification offers several benefits, especially for those starting their journey in data and cloud technology. Firstly, it provides a recognized credential that validates your understanding of basic data principles and Azure data services. This can help in career advancement or pivoting to cloud-focused roles.
The certification is also a stepping stone to more advanced Microsoft Azure certifications like DP-203 (Data Engineering) or Azure AI certifications. For businesses, having certified employees ensures that data professionals understand the fundamentals of working with Azure data solutions, improving project outcomes and efficiency.
What Is Covered In The DP-900 Exam?
The DP-900 exam content is organized into several key areas. These include understanding core data concepts, working with relational data on Azure, working with non-relational data, and an overview of analytics workloads on Azure. Each area tests your knowledge of how data is stored, managed, and analyzed.
Understanding core data concepts involves knowing different types of data, such as structured, semi-structured, and unstructured data. Candidates learn about relational databases, non-relational databases (also called NoSQL), and basic concepts of big data.
The section on relational data focuses on understanding tables, rows, columns, keys, and relationships. It also covers Azure’s relational database services such as Azure SQL Database and Azure Database for MySQL or PostgreSQL.
The non-relational data part explains document, key-value, graph, and column-family databases. It introduces Azure Cosmos DB as a fully managed NoSQL database service supporting multiple models.
The analytics section covers data ingestion, processing, and visualization using Azure services like Azure Synapse Analytics and Power BI. It introduces the concept of big data analytics and data pipelines.
Skills Measured In The DP-900 Exam
The exam tests several specific skills, including the ability to identify core data concepts, describe how relational and non-relational data is stored and managed, and understand analytics workloads on Azure. Candidates must be able to articulate the purpose and capabilities of various Azure data services.
More specifically, the skills measured include:
Describe core data concepts such as types of data and data workloads
Describe how to work with relational data on Azure
Describe how to work with non-relational data on Azure
Describe an analytics workload on Azure
These skills ensure that candidates have a well-rounded understanding of the basics required for data-related roles on Azure.
Who Should Take The DP-900 Exam?
The DP-900 exam is ideal for data professionals, business users, and developers who want to demonstrate foundational knowledge of data concepts and Azure data services. It is also suitable for students and individuals starting their careers in data or cloud computing.
Since the exam focuses on fundamental concepts, no prior technical experience or programming skills are required, though familiarity with cloud computing concepts can be helpful. Candidates interested in learning how data services work on the cloud and how to leverage them in business or technical scenarios will find this certification valuable.
Preparing For The DP-900 Exam
Preparing for the DP-900 exam involves a combination of studying theoretical concepts and practicing with Azure data services. Microsoft offers official learning paths that cover the exam objectives, including free online modules and instructor-led training.
Candidates should focus on understanding the basics of relational and non-relational data, the different Azure data offerings, and how data analytics workflows operate. Hands-on experience with Azure portals, databases, and analytics tools can significantly enhance preparation.
It is recommended to review the official exam skills outline, use practice exams to identify knowledge gaps, and engage with community forums or study groups. Consistent study and practical exercises increase the chances of passing the exam on the first attempt.
Exam Format And Passing Criteria
The DP-900 exam typically consists of multiple-choice questions, drag-and-drop exercises, and case studies. The number of questions ranges from 40 to 60, and the allotted time is about 60 minutes. The exam is computer-based and can be taken at a testing center or online with remote proctoring.
The passing score is usually around 700 out of 1000, but Microsoft can update this threshold. Candidates are evaluated on their ability to correctly answer questions covering all exam domains. It is important to answer thoroughly and manage time efficiently during the exam.
How The DP-900 Certification Helps Your Career
Holding the DP-900 certification can open doors to various roles in data and cloud computing. It demonstrates your knowledge of Azure data services to employers and clients, helping you stand out in a competitive job market.
Entry-level positions such as data analyst, data engineer trainee, cloud administrator, or business intelligence analyst can benefit from this certification. Additionally, it lays the groundwork for more specialized certifications and roles in data engineering, data science, and cloud architecture.
Organizations also value certified professionals because they bring verified skills to projects, reducing training time and improving project success rates.
Common Challenges In DP-900 Preparation
Some candidates may find the breadth of topics in DP-900 challenging, especially those unfamiliar with cloud or database concepts. Understanding both relational and non-relational data paradigms requires grasping different data structures and use cases.
Another challenge is learning the Azure-specific services and terminology, which can be overwhelming if you are new to Microsoft Azure. Hands-on experience and practice labs can help overcome this hurdle by providing real-world context.
Time management is also critical. Balancing study time with other responsibilities can be difficult, so creating a structured study plan is essential for success.
Tips For Passing The DP-900 Exam
To increase the chances of success in the DP-900 exam, follow these tips:
Study the official exam guide and focus on each skill measured
Use Microsoft Learn modules and practice labs to gain hands-on experience
Take practice tests to familiarize yourself with question formats and time limits
Join study groups or online forums to discuss topics and clarify doubts
Review and understand the different Azure data services and their use cases
Manage your exam time carefully to ensure you answer all questions
Stay calm and confident during the exam
Consistency in preparation and practical knowledge will greatly improve your performance.
What Comes After DP-900 Certification?
After earning the DP-900 certification, many candidates choose to deepen their expertise by pursuing more advanced Azure certifications. For example, the DP-203 certification focuses on data engineering and more complex Azure data services.
Other related certifications include Azure AI Fundamentals for those interested in artificial intelligence or Azure Solutions Architect for a broader cloud computing role.
Continuous learning and staying updated with Azure’s evolving services are important to maintain relevance and advance your career.
The DP-900 exam certification is an excellent starting point for anyone looking to build foundational knowledge in data concepts and Microsoft Azure data services. It validates your understanding of both traditional and cloud-based data management and analytics.
Whether you are a student, a professional seeking to shift careers, or a business user interested in cloud data, DP-900 offers a valuable credential. Proper preparation through study and hands-on practice will help you pass the exam and open up opportunities in the growing field of cloud data services.
By understanding the exam objectives, practicing with Azure services, and following a structured study plan, you can confidently earn the DP-900 certification and take the first step in your Azure data journey.
Understanding Core Data Concepts For DP-900
A key part of the DP-900 exam certification is a solid grasp of core data concepts. These include understanding what data is, the types of data, and how data can be categorized and used. Data is the foundation for any data service, and knowing the differences between structured, semi-structured, and unstructured data is crucial.
Structured data fits neatly into tables with rows and columns, making it easy to organize and query using languages like SQL. Semi-structured data, such as JSON or XML, has some organizational properties but does not fit rigid tables. Unstructured data includes images, videos, and text files, which require different handling methods.
Understanding these data types helps you decide which Azure data services to use based on the data format and workload needs. It also forms the basis for learning relational versus non-relational databases.
Exploring Relational Data In DP-900
Relational data is at the heart of many business applications. It organizes data into tables, with rows representing records and columns representing fields. Keys like primary and foreign keys establish relationships between tables, enabling complex queries and data integrity.
The DP-900 certification requires understanding how relational databases work and their common use cases. Microsoft Azure offers relational database services such as Azure SQL Database, a managed version of Microsoft SQL Server, and Azure Database for MySQL and PostgreSQL.
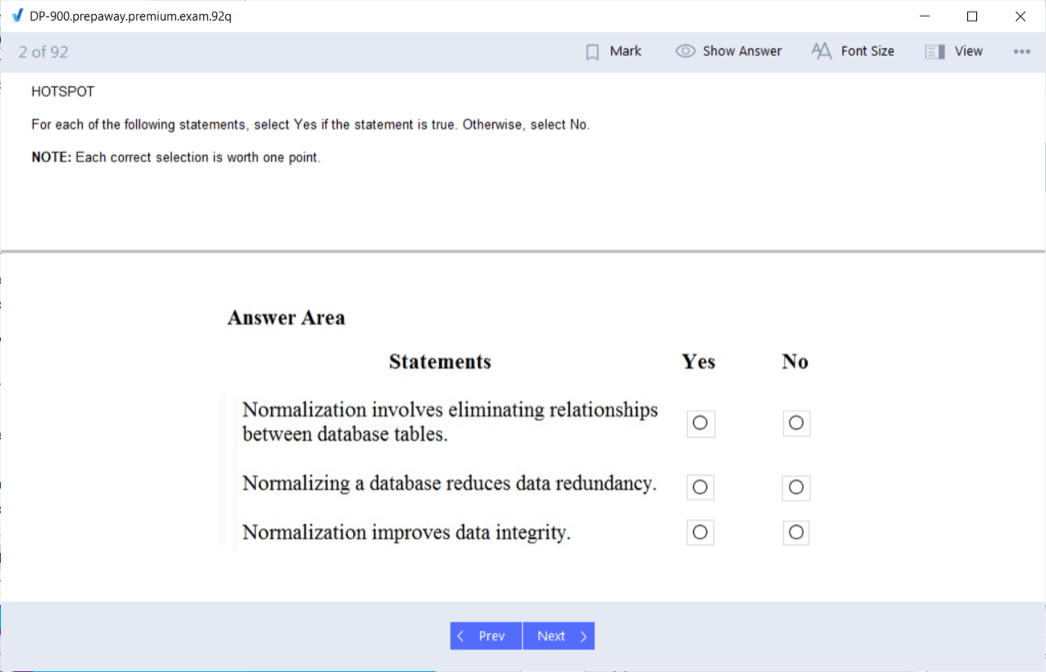
You should be familiar with concepts like normalization, indexing, and transaction support, which ensure efficient and reliable data storage and retrieval in relational databases.
Working With Non-Relational Data In DP-900
Non-relational data, often called NoSQL data, does not rely on the table model. It is designed to handle large volumes of diverse data types and scale out across many servers. There are several types of NoSQL databases, including document stores, key-value stores, graph databases, and column-family stores.
Azure Cosmos DB is Microsoft’s flagship NoSQL service and supports multiple data models. Understanding how Cosmos DB works, including its global distribution, consistency models, and query capabilities, is essential for the DP-900 exam.
Candidates should also recognize when non-relational databases are better suited for certain applications, such as handling social networks, real-time analytics, or IoT data.
Introduction To Big Data And Analytics In DP-900
Big data refers to extremely large and complex datasets that traditional database systems cannot handle effectively. The DP-900 exam covers the basic concepts of big data and the analytics services available on Azure to process and analyze this data.
Azure Synapse Analytics is a key service that integrates big data and data warehousing capabilities. It allows you to run analytics on massive datasets using SQL, Spark, and other processing frameworks.
Understanding how data is ingested, processed, stored, and visualized is part of the exam objectives. Candidates should be aware of Azure Data Factory for data movement and Power BI for data visualization.
Azure Data Services Overview For DP-900
The DP-900 exam tests knowledge of Azure data services and how they fit different data scenarios. Some core Azure services include Azure SQL Database, Azure Cosmos DB, Azure Synapse Analytics, Azure Data Factory, and Azure Databricks.
Candidates should understand the purpose of each service, their main features, and typical use cases. For example, Azure SQL Database is best for relational data applications, while Cosmos DB suits globally distributed NoSQL workloads.
Learning about pricing models, scalability options, and security features helps candidates make informed choices about which service to use.
Data Security And Compliance In DP-900
Data security is a fundamental part of managing data in the cloud. The DP-900 exam includes topics on how Azure protects data and ensures compliance with regulations.
Candidates need to know about encryption at rest and in transit, network security, identity management using Azure Active Directory, and data masking techniques.
Understanding compliance frameworks like GDPR and how Azure services help organizations meet these requirements is important for the exam and real-world applications.
Preparing For The DP-900 Exam With Hands-On Practice
While theoretical knowledge is important, practical experience with Azure data services significantly enhances understanding. Candidates should use the Azure portal to create and manage databases, ingest data, and run queries.
Many learning platforms provide free access to Azure sandboxes where you can explore services without needing your own subscription. Hands-on labs help you connect concepts to real tasks.
Practice with writing SQL queries, setting up Cosmos DB containers, and running data pipelines in Azure Data Factory will build confidence.
Time Management During The DP-900 Exam
The DP-900 exam has a time limit that requires effective time management. It is important to pace yourself and not spend too long on any single question.
Start by answering the questions you find easiest, then return to the more challenging ones. Use the review feature if available to flag questions and revisit them before submitting.
Reading each question carefully and eliminating obviously wrong answers can improve speed and accuracy.
Common Mistakes To Avoid In The DP-900 Exam
One common mistake is neglecting to fully understand the exam objectives. Many candidates focus only on Azure services without mastering the underlying data concepts, which can lead to lower scores.
Another mistake is ignoring practice tests. These help familiarize you with question formats and exam conditions.
Overconfidence can lead to rushing through the exam without double-checking answers. Conversely, spending too much time on one question reduces time for others. Balance is key.
Building A Study Plan For DP-900 Success
Creating a structured study plan tailored to your schedule is essential for success. Allocate time each day or week to cover different exam domains.
Start with foundational data concepts, then move on to Azure services. Include time for hands-on labs and practice exams.
Set milestones to track your progress and adjust your plan based on areas of difficulty.
Consistency and discipline in following the study plan will make the exam preparation manageable and effective.
Understanding The Role Of DP-900 In Cloud Career Paths
DP-900 certification is often the first step in a cloud data career. It lays the groundwork for roles such as data analyst, junior data engineer, and database administrator.
With this certification, you demonstrate to employers that you have the basic skills to work with cloud data services.
As you gain experience, you can pursue specialized certifications and roles in big data, machine learning, or cloud architecture, building on the knowledge from DP-900.
Using Exam Results To Plan Your Next Steps
After completing the DP-900 exam, reviewing your results can provide valuable insights. Microsoft provides a score breakdown by skill area, showing strengths and weaknesses.
If you pass, consider which advanced certifications align with your career goals. If you don’t pass, use the feedback to focus your study on weaker areas before retaking the exam.
Continuous learning and certification renewal are part of a long-term career strategy in cloud and data fields.
How DP-900 Fits Into The Microsoft Certification Ecosystem
The DP-900 certification belongs to Microsoft’s fundamental level certifications. It complements other fundamentals exams such as AZ-900 for Azure Fundamentals and AI-900 for Azure AI Fundamentals.
Together, these certifications build a comprehensive understanding of Azure cloud capabilities.
Candidates often start with fundamentals and progress to role-based certifications, which offer deeper technical knowledge and specialized skills.
Real-World Applications Of DP-900 Knowledge
The skills gained from DP-900 certification are immediately applicable in many business scenarios. Understanding data types and services helps in designing solutions that meet business needs.
For example, selecting the right database service for an application improves performance and reduces costs.
Data security and compliance knowledge ensures that data handling meets legal requirements, protecting organizations from risks.
Analytics skills help turn data into actionable insights, supporting decision-making and strategic planning.
The Future Of Data Roles With DP-900 Foundation
As organizations increasingly adopt cloud technologies, demand for data professionals familiar with Azure will continue to grow.
DP-900 certification equips individuals with a foundation to adapt to evolving data technologies and cloud services.
With the rapid pace of innovation, continuous upskilling is essential to remain relevant and take advantage of emerging opportunities.
The foundational knowledge from DP-900 provides a solid base for lifelong learning in data and cloud domains.
The Role Of Data In Modern Cloud Solutions
Data is one of the most valuable assets for any organization today. The DP-900 exam certification highlights the importance of understanding data’s role in cloud solutions. Data drives decision-making, powers applications, and enables businesses to innovate. In modern cloud environments, data must be stored, managed, and analyzed efficiently and securely.
The cloud provides scalable and flexible resources that allow organizations to handle increasing data volumes and complexity. Understanding how data fits into these cloud architectures is fundamental knowledge tested in the DP-900 exam.
Key Concepts Of Data Storage And Management
At the heart of the DP-900 exam is the concept of data storage and management. Data storage involves where and how data is saved, while data management refers to the processes that ensure data’s accuracy, availability, and security.
Relational databases organize data in tables with well-defined schemas. This structure supports complex queries and transactions, which are common in business applications. Non-relational databases offer flexibility for diverse data types, which is critical for modern applications handling large or rapidly changing datasets.
Candidates must understand storage options on Azure, including managed relational databases and NoSQL offerings. They should also grasp how these services ensure data durability, availability, and recovery.
Introduction To Azure SQL Database For DP-900
Azure SQL Database is a fully managed relational database service on Azure. It supports familiar SQL Server capabilities without the overhead of managing infrastructure. The DP-900 exam tests understanding of how Azure SQL Database simplifies deployment, scaling, and maintenance.
Key features include automated backups, high availability, security features like encryption, and integration with other Azure services. Knowing how and when to use Azure SQL Database is critical for DP-900 candidates, especially when handling transactional workloads requiring strong consistency and relational data models.
Exploring Azure Cosmos DB
Azure Cosmos DB is a globally distributed, multi-model database service designed for scalable and low-latency access to data. It supports key-value, document, graph, and column-family data models, making it versatile for many applications.
For DP-900, candidates should understand Cosmos DB’s unique features, such as global replication, tunable consistency levels, and multiple APIs for accessing data. Cosmos DB is ideal for applications needing fast, global data access and flexible schema design.
Basics Of Data Analytics On Azure
The DP-900 certification introduces candidates to data analytics fundamentals on Azure. Analytics involves collecting, processing, and analyzing data to extract meaningful insights.
Azure Synapse Analytics is a powerful analytics service that combines data warehousing and big data analytics. It enables querying data using SQL, Spark, and integrates with machine learning tools. Understanding the flow of data through ingestion, transformation, storage, and visualization is a key exam objective.
Candidates should also be familiar with Azure Data Factory, a service for orchestrating data movement and transformation across various data sources.
Understanding Data Ingestion And Processing
Data ingestion refers to bringing data into storage or analytics systems from various sources. In the context of Azure, this often means using Azure Data Factory to copy data from on-premises or cloud sources into data lakes or databases.
Processing transforms raw data into formats suitable for analysis. This can include cleaning, aggregating, or enriching data. Azure offers multiple processing options, including batch processing with Azure Data Factory and real-time streaming with Azure Stream Analytics.
The DP-900 exam tests familiarity with these concepts and the services that support them.
Introduction To Power BI For Data Visualization
Data visualization is the process of representing data graphically to reveal patterns and insights. Power BI is Microsoft’s business analytics tool that enables users to create interactive reports and dashboards.
For DP-900, understanding the role of Power BI as a visualization layer is important. Candidates should know how Power BI connects to Azure data services, allowing business users to explore data without deep technical expertise.
Visualization helps in communicating results effectively, supporting decision-making at all levels of an organization.
Security Considerations For Azure Data Services
Security is a critical aspect of managing data on Azure. The DP-900 exam includes key security principles, such as encryption of data at rest and in transit, role-based access control, and network security.
Azure provides built-in security features for its data services. These include encryption options, firewall rules, virtual network integration, and auditing capabilities. Candidates should understand how these features protect data and help organizations comply with regulatory requirements.
Knowledge of identity and access management, particularly through Azure Active Directory, is also essential.
Compliance And Governance In Azure Data Solutions
Compliance involves adhering to laws and regulations governing data privacy and protection. Governance refers to policies and processes ensuring data is managed responsibly.
The DP-900 certification covers basic compliance frameworks like GDPR and HIPAA. Azure offers tools to help organizations monitor compliance and apply governance policies.
Candidates should understand the importance of data classification, auditing, and monitoring to maintain compliance and reduce risk.
Exam Day Tips For DP-900
On exam day, it is important to approach the DP-900 exam calmly and strategically. Candidates should arrive early or log in ahead of time if taking the exam remotely.
Reading questions carefully and understanding what is being asked is crucial. Many questions test conceptual knowledge and the ability to choose the best service for a scenario.
Time management is key. Candidates should pace themselves and avoid getting stuck on difficult questions. It is better to mark and return to challenging items if the exam format allows.
Building Confidence Through Practice Exams
One of the best ways to prepare for the DP-900 exam is through practice exams. They help candidates get used to the format, question types, and pacing of the real exam.
Practice exams reveal knowledge gaps, allowing candidates to focus their studies where needed. They also build confidence by simulating the exam environment.
Consistent use of practice tests along with hands-on Azure experience creates a well-rounded preparation strategy.
The Importance Of Continuous Learning Post Certification
Earning the DP-900 certification is just the beginning. The cloud and data landscape are rapidly evolving, requiring continuous learning to stay current.
Candidates should regularly review Azure updates, new services, and best practices. This habit not only maintains certification relevance but also enhances job performance.
Engaging in community forums, attending webinars, and pursuing advanced certifications help build expertise over time.
Career Paths Opened By DP-900 Certification
The DP-900 certification opens multiple career paths in the data and cloud ecosystem. Roles such as data analyst, junior data engineer, and cloud data administrator often start with foundational knowledge validated by DP-900.
As professionals gain experience, they can move into specialized roles like data scientist, database administrator, or cloud architect. Each path builds on the basics covered in the DP-900 certification.
Employers value the certification as evidence of a candidate’s commitment to understanding cloud data fundamentals.
DP-900 Exam Certification Benefits
In summary, the DP-900 exam certification provides a strong foundation in data concepts and Azure data services. It helps candidates demonstrate skills relevant to the growing cloud data market.
The certification is accessible to beginners but also valuable for professionals looking to formalize their knowledge. It prepares individuals for more advanced certifications and roles.
By mastering data fundamentals and Azure services, candidates can contribute effectively to cloud data projects and drive business value.
Introduction To Data Workloads In DP-900
Data workloads refer to the specific types of data processing tasks that different systems and services are designed to handle. The DP-900 exam covers understanding the various data workloads and selecting the appropriate Azure data services based on workload requirements.
These workloads include transactional processing, analytical processing, big data processing, and real-time streaming. Each workload has distinct characteristics, such as the volume of data processed, latency requirements, and the nature of queries or operations performed.
Understanding workloads is key to designing efficient data solutions on Azure and forms a critical portion of the DP-900 exam.
Transactional Workloads And Their Importance
Transactional workloads are characterized by frequent data updates, inserts, and deletes, often supporting operational business applications. These workloads require strong consistency, fast response times, and support for complex queries involving multiple tables.
Azure SQL Database is a prime example of a service designed for transactional workloads. It supports ACID transactions, ensuring data integrity and reliability during concurrent access.
The DP-900 exam expects candidates to know when transactional workloads are appropriate and how Azure services support them. Understanding transaction concepts and how to optimize them is beneficial.
Analytical Workloads And Data Warehousing
Analytical workloads focus on querying large volumes of data to uncover trends, patterns, and insights. Unlike transactional systems, they are optimized for read-heavy operations, aggregations, and complex joins over massive datasets.
Azure Synapse Analytics is a service designed for analytical workloads and data warehousing. It integrates big data and data warehouse capabilities, allowing seamless querying of relational and non-relational data.
Candidates should understand how data warehouses differ from operational databases and the role they play in business intelligence and reporting.
Big Data Workloads And Distributed Systems
Big data workloads involve processing extremely large and complex datasets that exceed the capabilities of traditional systems. These workloads often require distributed storage and parallel processing.
Azure offers services like Azure Databricks and HDInsight to handle big data workloads. These services support frameworks such as Apache Spark and Hadoop, enabling scalable data processing.
The DP-900 exam covers basic concepts of big data and the Azure services available to support it. Candidates should grasp the challenges of big data, including storage, processing speed, and data variety.
Real-Time And Streaming Data Workloads
Real-time workloads process data as it arrives, enabling immediate insights and actions. These workloads are common in scenarios such as IoT telemetry, fraud detection, and live analytics.
Azure Stream Analytics is a service that allows real-time stream processing on Azure. It can ingest data from various sources, perform filtering, aggregations, and analytics on the fly.
For DP-900, understanding the differences between batch and stream processing and knowing when to use stream analytics is important.
Overview Of Azure Data Storage Options
Choosing the right data storage option is critical for performance and cost efficiency. Azure provides multiple storage services suited to different data types and workloads.
Azure Blob Storage is optimized for unstructured data such as images, videos, and logs. It is highly scalable and cost-effective for large datasets.
Azure Data Lake Storage builds on Blob Storage, offering hierarchical namespaces and features tailored for big data analytics.
Understanding these storage options and their use cases is essential for the DP-900 exam.
Understanding Data Consistency Models
Data consistency defines how up-to-date and synchronized data copies are across different nodes in distributed databases. The DP-900 exam includes understanding consistency models used by Azure data services.
Strong consistency guarantees that all users see the same data at the same time, suitable for transactional systems.
Eventual consistency allows temporary differences between data copies to improve performance and availability, common in globally distributed systems like Cosmos DB.
Candidates should be familiar with these models and their trade-offs when selecting Azure services.
Exploring Azure Cosmos DB Consistency Levels
Azure Cosmos DB offers multiple consistency levels, providing flexibility in balancing latency, throughput, and data accuracy.
The levels include strong, bounded staleness, session, consistent prefix, and eventual consistency.
Each level provides different guarantees about how quickly updates propagate to all replicas. For example, strong consistency ensures immediate synchronization but may increase latency.
DP-900 candidates must understand these levels and select appropriate consistency for application requirements.
Data Partitioning And Scalability
Partitioning divides data into manageable pieces called partitions or shards, allowing distributed systems to scale horizontally.
Azure Cosmos DB automatically partitions data based on a partition key, enabling high scalability and performance.
Understanding how partitioning works and its importance in scaling data services is part of the DP-900 exam objectives.
Candidates should also know how partition keys affect query efficiency and storage distribution.
Introduction To Azure Data Factory
Azure Data Factory is a cloud-based data integration service that orchestrates data movement and transformation. It supports data ingestion from diverse sources and can trigger data workflows on schedule or in response to events.
DP-900 candidates should know the basic components of Data Factory, such as pipelines, datasets, and activities.
Understanding Data Factory’s role in ETL (extract, transform, load) and ELT (extract, load, transform) processes is important for data solution design.
Data Processing Techniques On Azure
Processing data can involve batch or real-time techniques. Batch processing handles large data volumes at intervals, while real-time processing works on continuous data streams.
Azure Synapse Analytics supports batch processing for analytics, while Azure Stream Analytics handles real-time data.
Candidates should understand scenarios where each technique applies and the strengths and limitations of Azure services supporting them.
Introduction To Serverless Data Architectures
Serverless computing allows users to build and run applications without managing infrastructure. In Azure, serverless data services automatically scale and handle operational concerns.
Azure Functions can process data events triggered by changes in storage or messaging systems.
Azure SQL Database serverless tier allows databases to auto-scale compute resources based on workload.
DP-900 includes understanding serverless options and how they simplify data processing and reduce costs.
Data Security Best Practices For Azure Data Solutions
Protecting data is a critical responsibility. Azure provides various security mechanisms that candidates should understand for the DP-900 exam.
These include encryption at rest using Azure Storage Service Encryption, encryption in transit via TLS, and access control through Azure Role-Based Access Control (RBAC).
Azure Key Vault allows secure management of encryption keys and secrets.
Understanding identity management, network security, and auditing are also key aspects.
Monitoring And Managing Azure Data Services
Effective data management requires monitoring performance and usage. Azure provides monitoring tools like Azure Monitor and Log Analytics to track metrics, diagnose issues, and optimize resources.
DP-900 candidates should understand the importance of monitoring for maintaining service reliability and meeting service-level agreements.
Learning how to use these tools to identify bottlenecks or security events supports operational excellence.
Preparing For The DP-900 Exam: Study Strategies
A successful DP-900 exam preparation plan includes mastering fundamentals, gaining practical experience, and reviewing exam objectives thoroughly.
Focus on understanding core data concepts before diving into specific Azure services.
Use Azure’s free tier or sandbox environments to practice creating and managing databases, running queries, and configuring data pipelines.
Practice exams and quizzes help reinforce knowledge and improve exam readiness.
Understanding Exam Format And Question Types
The DP-900 exam typically includes multiple-choice, drag-and-drop, and scenario-based questions.
Scenario questions assess the ability to apply knowledge to real-world situations, selecting appropriate services and design approaches.
Candidates should practice interpreting scenarios and focusing on the best-fit solution rather than memorizing service details alone.
Building A Foundation For Advanced Certifications
DP-900 serves as a stepping stone for more advanced Azure data certifications, such as DP-200, DP-201, and DP-203, which focus on data engineering and solution architecture.
Mastering DP-900 fundamentals makes learning advanced concepts easier and more effective.
Candidates planning long-term careers in cloud data should consider these pathways.
The Value Of DP-900 Certification In The Job Market
Having the DP-900 certification demonstrates a validated understanding of cloud data fundamentals, which is attractive to employers.
It signals a candidate’s readiness to work with Azure data services and contribute to data projects.
As cloud adoption grows, foundational certifications like DP-900 become valuable credentials for starting or advancing careers.
Final Thoughts
DP-900 certification covers essential knowledge of core data concepts, Azure data services, workloads, security, and best practices.
It equips candidates with foundational skills to build, manage, and analyze data solutions on Microsoft Azure.A combination of theoretical knowledge and hands-on practice is critical for success.
Achieving DP-900 certification opens doors to various cloud data roles and sets the stage for advanced learning.
Microsoft Azure Data DP-900 practice test questions and answers, training course, study guide are uploaded in ETE Files format by real users. Study and Pass DP-900 Microsoft Azure Data Fundamentals certification exam dumps & practice test questions and answers are to help students.
Exam Comments * The most recent comment are on top
- AZ-104 - Microsoft Azure Administrator
- AZ-305 - Designing Microsoft Azure Infrastructure Solutions
- DP-700 - Implementing Data Engineering Solutions Using Microsoft Fabric
- AB-100 - Agentic AI Business Solutions Architect
- MD-102 - Endpoint Administrator
- SC-300 - Microsoft Identity and Access Administrator
- PL-300 - Microsoft Power BI Data Analyst
- AB-900 - Microsoft 365 Copilot and Agent Administration Fundamentals
- MS-102 - Microsoft 365 Administrator
- SC-200 - Microsoft Security Operations Analyst
- AI-900 - Microsoft Azure AI Fundamentals
- AZ-900 - Microsoft Azure Fundamentals
- SC-401 - Administering Information Security in Microsoft 365
- AZ-700 - Designing and Implementing Microsoft Azure Networking Solutions
- DP-600 - Implementing Analytics Solutions Using Microsoft Fabric
- AI-102 - Designing and Implementing a Microsoft Azure AI Solution
- AZ-500 - Microsoft Azure Security Technologies
- SC-100 - Microsoft Cybersecurity Architect
- AI-103 - Developing AI Apps and Agents on Azure
- AB-730 - AI Business Professional
- AB-731 - AI Transformation Leader
- GH-300 - GitHub Copilot
- PL-400 - Microsoft Power Platform Developer
- AZ-204 - Developing Solutions for Microsoft Azure
- SC-900 - Microsoft Security, Compliance, and Identity Fundamentals
- AZ-140 - Configuring and Operating Microsoft Azure Virtual Desktop
- AZ-400 - Designing and Implementing Microsoft DevOps Solutions
- DP-300 - Administering Microsoft Azure SQL Solutions
- AZ-801 - Configuring Windows Server Hybrid Advanced Services
- MS-700 - Managing Microsoft Teams
- PL-600 - Microsoft Power Platform Solution Architect
- AZ-800 - Administering Windows Server Hybrid Core Infrastructure
- MB-800 - Microsoft Dynamics 365 Business Central Functional Consultant
- PL-200 - Microsoft Power Platform Functional Consultant
- AI-300 - Operationalizing Machine Learning and Generative AI Solutions
- PL-900 - Microsoft Power Platform Fundamentals
- MB-310 - Microsoft Dynamics 365 Finance Functional Consultant
- MB-330 - Microsoft Dynamics 365 Supply Chain Management
- DP-900 - Microsoft Azure Data Fundamentals
- SC-500 - Implementing End-to-End Security Controls for Cloud and AI Workloads
- AI-901 - Microsoft Azure AI Fundamentals
- MB-820 - Microsoft Dynamics 365 Business Central Developer
- MB-280 - Microsoft Dynamics 365 Customer Experience Analyst
- MB-230 - Microsoft Dynamics 365 Customer Service Functional Consultant
- MS-721 - Collaboration Communications Systems Engineer
- GH-200 - GitHub Actions
- DP-800 - Developing AI-Enabled Database Solutions
- MB-700 - Microsoft Dynamics 365: Finance and Operations Apps Solution Architect
- DP-100 - Designing and Implementing a Data Science Solution on Azure
- DP-420 - Designing and Implementing Cloud-Native Applications Using Microsoft Azure Cosmos DB
- MB-500 - Microsoft Dynamics 365: Finance and Operations Apps Developer
- DP-750 - Implementing Data Engineering Solutions Using Azure Databricks
- GH-900 - GitHub Foundations
- PL-500 - Microsoft Power Automate RPA Developer
- MB-335 - Microsoft Dynamics 365 Supply Chain Management Functional Consultant Expert
- GH-100 - GitHub Administration
- GH-500 - GitHub Advanced Security
- MS-900 - Microsoft 365 Fundamentals
- AZ-120 - Planning and Administering Microsoft Azure for SAP Workloads
- SC-400 - Microsoft Information Protection Administrator
- MB-240 - Microsoft Dynamics 365 for Field Service
- DP-203 - Data Engineering on Microsoft Azure
- 62-193 - Technology Literacy for Educators
- MO-200 - Microsoft Excel (Excel and Excel 2019)
- MO-400 - Microsoft Outlook (Outlook and Outlook 2019)
- MS-203 - Microsoft 365 Messaging
- MB-910 - Microsoft Dynamics 365 Fundamentals Customer Engagement Apps (CRM)
- 98-367 - Security Fundamentals
Purchase DP-900 Exam Training Products Individually
Why customers love us?
What do our customers say?
The resources provided for the Microsoft certification exam were exceptional. The exam dumps and video courses offered clear and concise explanations of each topic. I felt thoroughly prepared for the DP-900 test and passed with ease.
Studying for the Microsoft certification exam was a breeze with the comprehensive materials from this site. The detailed study guides and accurate exam dumps helped me understand every concept. I aced the DP-900 exam on my first try!
I was impressed with the quality of the DP-900 preparation materials for the Microsoft certification exam. The video courses were engaging, and the study guides covered all the essential topics. These resources made a significant difference in my study routine and overall performance. I went into the exam feeling confident and well-prepared.
The DP-900 materials for the Microsoft certification exam were invaluable. They provided detailed, concise explanations for each topic, helping me grasp the entire syllabus. After studying with these resources, I was able to tackle the final test questions confidently and successfully.
Thanks to the comprehensive study guides and video courses, I aced the DP-900 exam. The exam dumps were spot on and helped me understand the types of questions to expect. The certification exam was much less intimidating thanks to their excellent prep materials. So, I highly recommend their services for anyone preparing for this certification exam.
Achieving my Microsoft certification was a seamless experience. The detailed study guide and practice questions ensured I was fully prepared for DP-900. The customer support was responsive and helpful throughout my journey. Highly recommend their services for anyone preparing for their certification test.
I couldn't be happier with my certification results! The study materials were comprehensive and easy to understand, making my preparation for the DP-900 stress-free. Using these resources, I was able to pass my exam on the first attempt. They are a must-have for anyone serious about advancing their career.
The practice exams were incredibly helpful in familiarizing me with the actual test format. I felt confident and well-prepared going into my DP-900 certification exam. The support and guidance provided were top-notch. I couldn't have obtained my Microsoft certification without these amazing tools!
The materials provided for the DP-900 were comprehensive and very well-structured. The practice tests were particularly useful in building my confidence and understanding the exam format. After using these materials, I felt well-prepared and was able to solve all the questions on the final test with ease. Passing the certification exam was a huge relief! I feel much more competent in my role. Thank you!
The certification prep was excellent. The content was up-to-date and aligned perfectly with the exam requirements. I appreciated the clear explanations and real-world examples that made complex topics easier to grasp. I passed DP-900 successfully. It was a game-changer for my career in IT!


