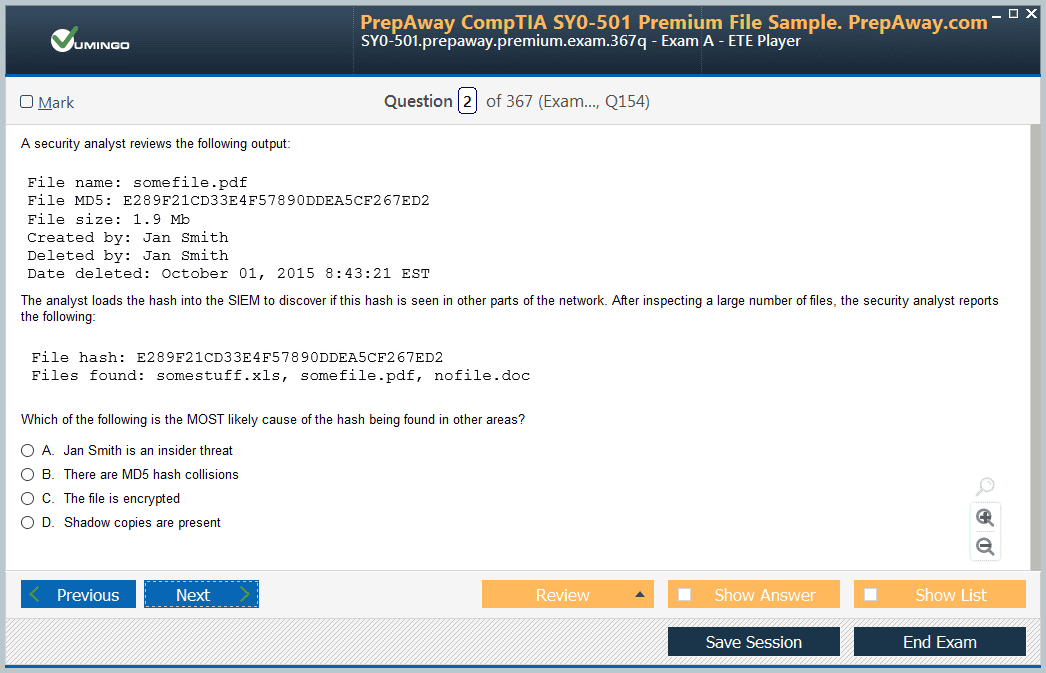
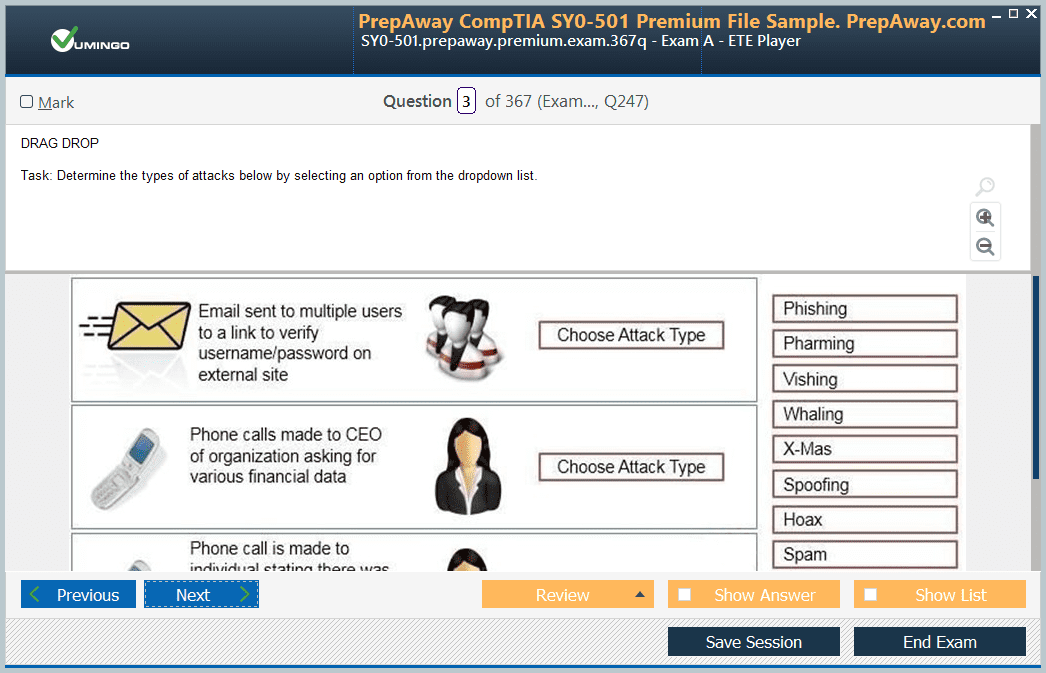
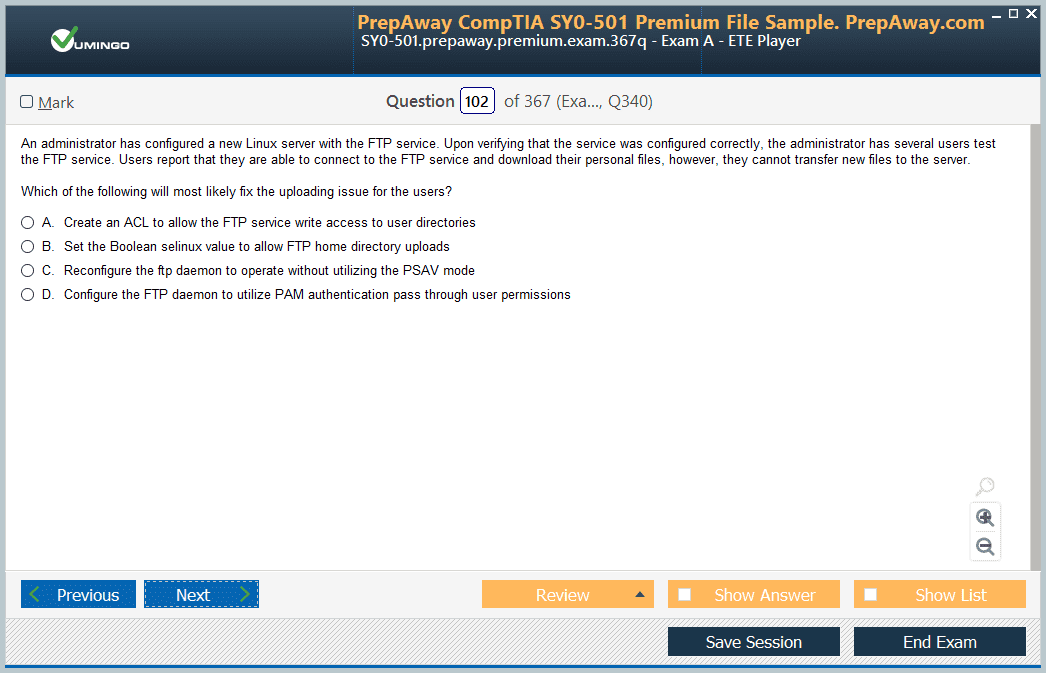
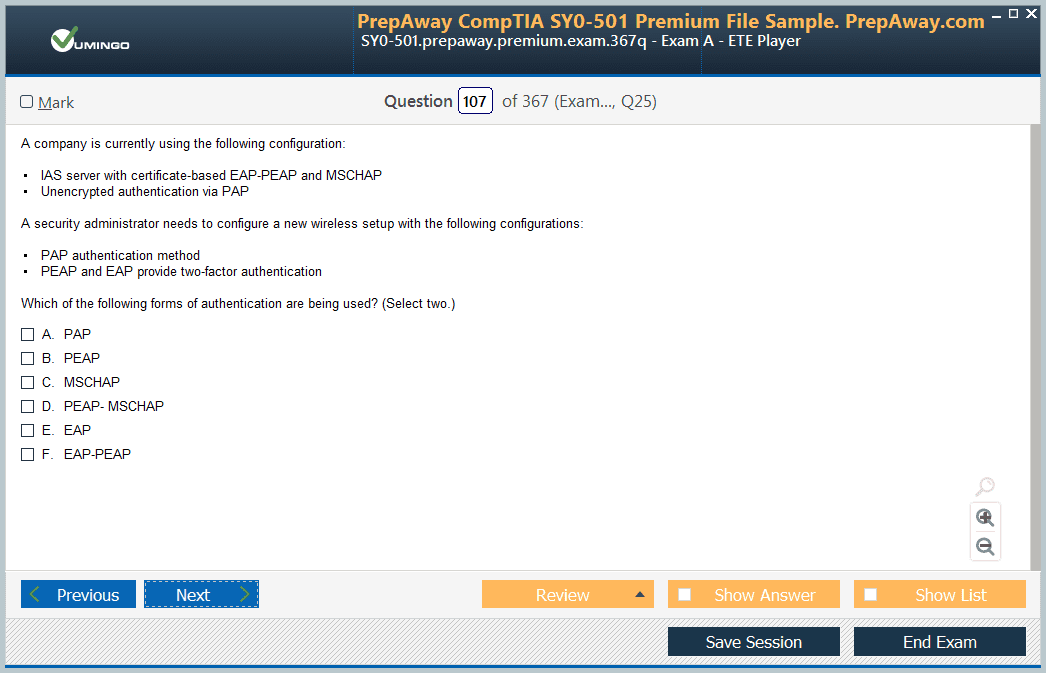
- Home
- Microsoft Certifications
- DP-203 Data Engineering on Microsoft Azure Dumps
Pass Microsoft Azure DP-203 Exam in First Attempt Guaranteed!
Get 100% Latest Exam Questions, Accurate & Verified Answers to Pass the Actual Exam!
30 Days Free Updates, Instant Download!


DP-203 Premium Bundle
- Premium File 397 Questions & Answers. Last update: Jun 15, 2026
- Training Course 262 Video Lectures
- Study Guide 1325 Pages








Last Week Results!

Includes question types found on the actual exam such as drag and drop, simulation, type-in and fill-in-the-blank.

Based on real-life scenarios similar to those encountered in the exam, allowing you to learn by working with real equipment.

Developed by IT experts who have passed the exam in the past. Covers in-depth knowledge required for exam preparation.
All Microsoft Azure DP-203 certification exam dumps, study guide, training courses are Prepared by industry experts. PrepAway's ETE files povide the DP-203 Data Engineering on Microsoft Azure practice test questions and answers & exam dumps, study guide and training courses help you study and pass hassle-free!
From Raw to Refined: A Deep Dive into DP-203 Data Engineering
The responsibilities of a data engineer extend far beyond managing databases or writing queries. These professionals are the architects of the data pipeline, ensuring that raw data is converted into meaningful insights for decision-makers. In the context of the DP-203 exam, this role becomes even more focused. The certification targets your ability to design and implement data solutions using Azure data services, setting a benchmark for your skills in cloud-based data engineering.
The exam reflects real-world scenarios that require integrating, transforming, and consolidating data from various structured and unstructured data systems. It tests your understanding of not only the tools within the Azure ecosystem but also how to use them strategically to build secure, scalable, and efficient data pipelines.
Core Concepts Covered In The DP-203 Exam
The exam encompasses a wide range of technical areas. Each segment evaluates different skill sets that a professional data engineer must possess. Below are the four primary focus areas:
Design and implement data storage
Design and develop data processing
Design and implement data security
Monitor and optimize data solutions
Each domain demands both conceptual clarity and practical implementation capabilities. The exam not only asks what a tool does but also how and when to use it effectively.
Data Storage Strategies In Azure
Data storage is foundational to any data pipeline. The exam requires familiarity with Azure Data Lake Storage, Azure Blob Storage, and Azure Synapse Analytics. You must understand when to use a data lake versus a relational database and how to implement hierarchical namespace in storage accounts. Knowledge of partitioning, indexing, and file formats such as Parquet and Avro will help you design optimal storage layers.
You’ll also be tested on implementing data retention policies and securing storage endpoints using managed identities and private endpoints. These are critical for ensuring data compliance and access control.
Building Data Processing Pipelines
Data transformation and movement are essential for turning raw data into actionable insights. Azure Data Factory and Azure Synapse Pipelines are core services you should master. Understanding activities like Copy, Mapping Data Flows, and executing Spark jobs is necessary.
In real-world scenarios, batch and stream processing often coexist. Therefore, the DP-203 exam evaluates your ability to choose between Azure Stream Analytics, Azure Data Explorer, and Azure Databricks based on use cases. Additionally, knowledge of triggers, parameterization, and integration runtime types in Data Factory can make your solutions more efficient.
Securing Data Architectures
Security is not an afterthought but a core component of data engineering. The exam expects you to implement encryption at rest and in transit, configure authentication and authorization using Azure Active Directory, and manage secrets via Azure Key Vault.
Role-based access control is another frequent topic. You must understand how to apply RBAC to limit data access, use firewalls for storage accounts, and ensure compliance with regulatory standards. Integration of security into pipeline execution also plays a part, including secure credential management and use of private endpoints.
Performance Optimization Techniques
Building a data pipeline is not enough—it must also be efficient. The DP-203 exam includes questions about performance tuning in Azure Synapse, including distribution methods like hash and round-robin, as well as index strategies.
For stream processing, latency and event ordering are critical. You’ll need to understand watermarking in Azure Stream Analytics and the performance implications of windowing functions. For batch pipelines, optimizing data flows through parallelism, caching, and transformations like joins and lookups is often tested.
Monitoring tools such as Azure Monitor, Log Analytics, and integration with Application Insights are equally important. They allow for proactive issue detection, cost optimization, and maintenance of service-level agreements.
Real-World Scenarios In The Exam
The DP-203 exam often presents you with scenarios instead of isolated questions. For example, you may be asked to design a pipeline that ingests real-time IoT data and stores it in a data lake for further analytics. In such cases, understanding how to combine Azure IoT Hub, Stream Analytics, and Data Lake Storage is essential.
Another scenario may involve migrating an on-premise ETL process to Azure. You should be able to evaluate whether Data Factory or Synapse Pipelines is more appropriate and how to integrate existing logic into Azure’s infrastructure.
Understanding The Scoring Pattern
Although Microsoft does not disclose exact scoring algorithms, experience shows that not all questions carry equal weight. Scenario-based questions often contribute more to your final score. These usually contain multiple sub-questions tied to a single situation.
There’s no penalty for wrong answers, so attempting every question is advisable. Additionally, keep in mind that some questions are scored on partial correctness—especially in case studies and multi-step operations.
Importance Of Hands-On Labs
Theory alone will not suffice. To pass this exam, practical exposure is vital. Deploy Azure services, write scripts to automate pipeline creation, and set up monitoring tools. Repetition is key. The more hands-on experience you gain, the more intuitive the solutions will become when faced with complex exam scenarios.
Creating and troubleshooting a pipeline from scratch not only reinforces your learning but also boosts your confidence. Experiment with edge cases, errors, and performance bottlenecks to deepen your understanding.
Common Mistakes And How To Avoid Them
One of the most common pitfalls is underestimating the exam’s scenario-based nature. Rote memorization of services and their functions won’t help unless you know how to apply them effectively. Avoid skipping security and monitoring topics, as these are integral to Azure-based solutions.
Another mistake is ignoring documentation or relying on outdated resources. Azure services evolve quickly, and the exam blueprint reflects recent changes. Stay updated with new features and best practices.
Time management is another crucial element. Practice completing case studies under time constraints. If you get stuck, mark the question and revisit it later.
Preparing for the DP-203 exam requires more than casual reading. Design a study plan that includes daily learning goals, weekly review sessions, and regular hands-on labs. Pair theory with application. If you read about a new Azure feature, try deploying it immediately and walk through a use case.
Join discussion forums or peer groups. Explaining a concept to someone else can significantly strengthen your grasp on the subject. Don’t hesitate to review failed attempts at pipeline configurations—they often offer the best learning opportunities.
Approach the certification as a validation of your real-world readiness. Passing the exam isn’t the end goal—it’s the beginning of a stronger, more impactful data engineering journey.
Building Reliable Data Pipelines
Data pipelines are the backbone of modern data engineering. For the DP-203 exam, understanding how to design and orchestrate efficient and resilient pipelines is essential. The goal is to move, clean, transform, and validate data through a structured flow using Azure services.
Azure Data Factory is the primary orchestration service for building these pipelines. It supports both code-based and visual development, allowing data engineers to create complex data workflows. Pipelines typically consist of activities such as copy data, data flow, notebook execution, and custom scripts. Triggers such as scheduled time, tumbling window, or event-based triggers control pipeline execution.
Reliability is ensured through mechanisms like retries, dependency conditions, and failure alerts. Data lineage and logging through Azure Monitor or Log Analytics help track the flow and performance of data pipelines. For the exam, expect to evaluate cases where pipelines fail and suggest appropriate logging or error-handling strategies.
Implementing Data Transformation Using Data Flows
Transforming data from raw to refined form is critical in a data engineering lifecycle. Azure Data Factory offers Mapping Data Flows, a low-code approach to implement transformations at scale. These data flows can perform joins, filters, derived columns, and conditional splits.
The DP-203 exam may present scenarios where different transformation options are evaluated. For example, some operations like aggregations are better suited for Spark-based transformations, while others may require native SQL expressions. Understanding when to use Mapping Data Flows versus custom notebooks in Azure Synapse Analytics or Azure Databricks is key.
Maintaining performance in transformation workloads involves selecting appropriate integration runtimes, managing partitioning strategies, and optimizing memory usage. Candidates are often tested on these best practices and how they influence cost and latency.
Managing Data Storage Across Services
Azure provides several storage options depending on the nature and purpose of data. Data engineers must choose the appropriate service based on durability, access speed, compliance needs, and integration support. The exam tests how well you differentiate between options like Azure Data Lake Storage Gen2, Blob Storage, Azure SQL Database, Cosmos DB, and Synapse Dedicated SQL Pools.
Data Lake Storage Gen2 is favored for storing large volumes of structured and unstructured data due to its hierarchical namespace and compatibility with big data analytics tools. Blob Storage is often used for storing binary files, logs, or backups, while Azure SQL Database is better for transactional datasets.
In exam scenarios, you may need to optimize data access by managing file sizes, leveraging caching mechanisms, or structuring data hierarchies using folder-based partitions. Cost management also plays a role, such as using lifecycle management policies to transition data to cooler tiers.
Applying Partitioning And Indexing Strategies
Efficient data processing relies heavily on smart partitioning and indexing. Partitioning divides a dataset into segments, making parallel processing easier and faster. For instance, in Azure Synapse, you can partition tables based on date or geographical regions. Similarly, Data Lake storage structures may benefit from folder-based partitioning.
Indexing is crucial for query optimization. In Azure SQL or Synapse, clustered indexes define physical data order, while non-clustered indexes support faster lookups for common query patterns. In Cosmos DB, indexing policies are used to improve query performance and reduce latency.
The exam might require you to recommend strategies to improve performance in a poorly optimized system. Understanding when to use hash-based versus range-based partitioning, and knowing how to manage index maintenance, can help solve these kinds of exam problems.
Designing Secure Access To Data
Data security is a cornerstone of the DP-203 exam. Data engineers are expected to implement robust access control mechanisms across all stages of data handling. Azure Role-Based Access Control and Access Control Lists work together to restrict unauthorized access.
Data Lake Storage supports granular permissions at both the folder and file levels. RBAC controls apply at the Azure resource level and should align with enterprise roles and responsibilities. Additionally, managing secrets using services like Azure Key Vault helps secure connection strings, API tokens, and service credentials.
Exam scenarios often involve selecting the correct authentication method for a given architecture—such as managed identities, service principals, or shared access signatures. It's important to understand the strengths and weaknesses of each option and when each is appropriate based on scalability, security, and operational complexity.
Enabling Data Auditing And Monitoring
Auditing and monitoring are essential for operational visibility. Azure provides several tools like Azure Monitor, Log Analytics, and Azure Synapse Monitoring to track activity across pipelines, data flows, and storage access.
Metrics such as data latency, throughput, error rates, and resource consumption are vital for diagnosing issues. Alerts can be configured to notify teams of critical failures, allowing for quick remediation. The exam will likely include cases where you must identify bottlenecks or propose monitoring enhancements.
For example, if a data pipeline takes longer than expected to complete, the ability to pinpoint whether the delay is due to slow source retrieval, poor transformation logic, or sink write issues is crucial. Familiarity with diagnostic settings, Kusto queries for logs, and custom metrics is a strong advantage in the exam.
Managing And Optimizing Cost
Cost optimization is an important aspect of a data engineer’s role. Azure services operate on pay-as-you-go pricing, which can quickly escalate if not managed properly. The DP-203 exam evaluates your understanding of cost-related decisions and resource management.
Using reserved capacity for predictable workloads, selecting the right integration runtime size, and avoiding unnecessary data movement are all strategies to lower expenses. Data engineers should also optimize data volume by implementing compression, archiving, and pruning of stale records.
For example, a scenario may involve a data warehouse incurring high costs due to frequent full-table scans. The optimal solution may include partitioning strategies, materialized views, or using PolyBase for efficient external table queries.
Using Delta Lake And Versioned Data
Delta Lake provides ACID transactions and scalable metadata handling in a data lake environment. It enhances data reliability, supports schema evolution, and enables time-travel queries. This is particularly valuable for use cases involving slowly changing dimensions or maintaining snapshots of data.
The DP-203 exam often presents data consistency challenges. Delta Lake can resolve issues like partial writes, duplicate records, or conflicting updates. It works seamlessly with Spark-based engines such as Azure Databricks and Synapse Spark Pools.
Understanding how to implement merges, upserts, and deletes in Delta format helps answer exam questions around data versioning and consistency guarantees. It’s also important to understand how Delta tables integrate with data catalogs and governance models.
Managing Metadata And Catalogs
Metadata management allows for better discoverability, lineage tracking, and compliance. Azure Purview and Synapse’s built-in Data Catalog help catalog assets across Azure and external sources. This makes it easier for teams to collaborate and ensures data is not duplicated or misused.
Metadata includes schema definitions, data classifications, and usage statistics. For the DP-203 exam, expect to be tested on managing schema drift, implementing classifications, and integrating metadata with security tools.
The role of metadata becomes more important in large-scale environments. Automated metadata extraction during ingestion, tagging sensitive fields, and enforcing data quality checks based on metadata are emerging best practices.
Ingesting Streaming Data
Real-time data ingestion is key in scenarios such as fraud detection, IoT telemetry, or clickstream analytics. Azure Stream Analytics, Event Hubs, and Azure Data Explorer are among the tools used to process streaming data.
Event Hubs acts as the ingestion layer, accepting high-volume data from external sources. Azure Stream Analytics then processes the data in real-time and writes it to various sinks like Data Lake, Synapse, or even Power BI for visualization.
The DP-203 exam may challenge you with architectural decisions around latency tolerance, windowing functions, and message retention. Understanding how to scale streaming jobs, implement checkpoints, and handle late-arriving data is important for success.
Creating CI/CD Pipelines For Data Workflows
Modern data engineering practices emphasize automation. Continuous integration and continuous deployment pipelines for data workflows improve development velocity and reduce human error. Azure DevOps and GitHub Actions are commonly used to automate deployment of Azure Data Factory pipelines, Synapse artifacts, and notebooks.
For the DP-203 exam, knowledge of how to integrate source control, promote artifacts across environments, and manage infrastructure as code is beneficial. YAML-based pipeline definitions, parameterized templates, and secrets management are areas frequently assessed.
Version control also enables rollback in case of failures and enforces standardized coding practices. Even data transformation logic inside Mapping Data Flows or notebooks can benefit from versioning.
Implementing Data Governance
Data governance ensures that data is used responsibly, securely, and compliantly. For the DP-203 exam, this includes topics such as data classification, sensitivity labeling, data masking, and lineage tracking.
Azure Purview, Microsoft Defender for Cloud, and Synapse’s built-in policies enable enforcement of governance rules. Scenarios on the exam might involve identifying data exfiltration risks, proposing classification policies, or recommending governance structures across multiple Azure subscriptions.
Proper governance improves not only compliance but also trust in the data. It supports audit readiness, reduces data breaches, and streamlines data usage across departments.
Understanding Data Transformation Workflows In DP-203
Data transformation is a critical component of the DP-203 exam, testing your ability to manipulate, convert, and prepare data for analysis. Candidates are expected to understand how to work with various transformation tools and languages such as T-SQL, Data Flows in Azure Data Factory, and Azure Synapse Pipelines. The objective is to ensure data conforms to business logic, rules, and formatting expectations for downstream consumption.
Transformation operations can range from simple tasks like changing column formats to complex activities like aggregations, joins, derived columns, and conditional logic. Mastery over these operations ensures efficiency in data processing and supports business decision-making with accurate insights.
A strong grasp of mapping data flows allows you to visually design transformation logic without writing any code. For more advanced scenarios, the ability to author stored procedures or leverage Data Flow expressions becomes essential. Understanding these areas gives you a strategic advantage when designing data workflows that are both scalable and maintainable.
Working With Azure Synapse Analytics
Azure Synapse Analytics plays a central role in modern data engineering. The DP-203 exam focuses heavily on this platform because it provides an integrated environment for ingesting, preparing, managing, and serving data. It supports both on-demand querying using serverless SQL pools and high-performance data warehousing using dedicated SQL pools.
Candidates must understand how to create Synapse workspaces, configure linked services, and manage security settings. There is a strong emphasis on executing T-SQL scripts for transformations, implementing partitioning strategies, and optimizing performance with distribution methods like hash, round-robin, and replicated distributions.
Another important area is managing and analyzing large volumes of structured and unstructured data. Azure Synapse’s integration with Spark pools and pipeline orchestration makes it a powerful tool for advanced data analytics. Developing familiarity with notebooks, resource classes, and workload management policies will prepare you to solve complex data problems efficiently.
Building Real-Time Data Processing Solutions
In data engineering, real-time processing is becoming increasingly important. The DP-203 exam evaluates your capability to build real-time ingestion and transformation pipelines using tools such as Azure Stream Analytics and Event Hubs. These components allow data to be processed as it arrives, enabling use cases like fraud detection, monitoring dashboards, and IoT scenarios.
Azure Stream Analytics supports querying live data streams using a SQL-like language, making it accessible to those familiar with traditional SQL syntax. However, candidates must also understand advanced topics such as windowing functions, user-defined functions, and late arrival data handling.
You should be able to design a pipeline that reads data from multiple input sources, performs filtering or aggregations, and outputs to destinations like Azure SQL Database, Cosmos DB, or Azure Data Lake. Ensuring reliability and scalability in your streaming jobs, while managing cost and performance, is critical to success in real-time data systems.
Optimizing Data Storage For Performance
One of the fundamental principles in data engineering is understanding how to store data efficiently. The DP-203 exam tests your ability to choose the right storage solutions and apply optimizations that balance cost, performance, and scalability.
Azure offers various storage options such as Azure Data Lake Storage Gen2, Azure Blob Storage, and Azure SQL. Knowing when to use hierarchical namespaces, how to organize data into folders, and how to partition files based on attributes like date or region is vital.
Compression techniques and file format choices also significantly impact performance. For instance, Parquet and Avro offer better performance for analytics due to their columnar nature and support for schema evolution. CSV and JSON, while more human-readable, are not as efficient for large-scale processing.
The exam also expects you to configure access tiers like Hot, Cool, and Archive, depending on data access patterns. Policies for data retention and lifecycle management help automate storage cost optimization while maintaining compliance with governance standards.
Securing Data Engineering Workloads
Security is a core pillar in the DP-203 exam. Data engineers must be equipped to secure data at rest and in transit, implement authentication mechanisms, and manage access controls. Azure provides several tools for this purpose, including Azure Key Vault, Managed Identities, and Role-Based Access Control.
Encryption should be enabled for all sensitive data, and best practices include using customer-managed keys when necessary. Data masking and row-level security help ensure that users only see what they are authorized to access.
Another important area is monitoring and auditing. Azure Monitor, Log Analytics, and Activity Logs provide visibility into access attempts, configuration changes, and potential threats. Being proactive in designing secure architectures not only protects your data but also ensures compliance with organizational policies and regulatory frameworks.
Designing Reliable And Recoverable Data Pipelines
Reliability is a key concern for enterprise-grade data solutions. In the context of DP-203, this means designing pipelines that can gracefully handle failures, retries, and ensure data integrity. Azure Data Factory and Azure Synapse Pipelines offer built-in fault tolerance mechanisms that you should leverage during implementation.
Using activities such as error handling, conditional paths, and timeouts can help build robust workflows. Checkpointing in streaming jobs, transactional writes, and idempotent logic are also essential for avoiding data duplication or loss.
The exam also explores strategies for data backup and disaster recovery. You should understand how to restore data from Azure Blob snapshots, reprocess failed events, and design failover architectures that ensure continuity in the event of a region-wide outage or system failure.
Integrating Machine Learning With Data Engineering
As organizations seek to extract more value from their data, integrating machine learning into data engineering pipelines becomes increasingly relevant. Although the DP-203 exam does not test in-depth machine learning knowledge, it expects candidates to understand how to support data science workflows.
This includes preparing and delivering data for training models, storing model artifacts, and operationalizing models using batch or real-time scoring. Azure Machine Learning service can be orchestrated within Synapse or Data Factory pipelines to automate these tasks.
Feature engineering is another critical task that overlaps with data engineering. You should be able to design transformation workflows that generate meaningful features from raw datasets, and ensure that they are stored in a format consumable by model training jobs.
Collaboration with data scientists is essential, and part of your responsibility as a data engineer is to ensure that models receive clean, structured, and well-documented data consistently.
Monitoring And Tuning Data Workloads
Monitoring is not just about observability but also about performance optimization. The DP-203 exam places importance on tuning and monitoring data pipelines, storage, and compute resources. Azure Monitor, Log Analytics, and the Synapse Studio performance hub are your primary tools for this task.
Understanding metrics such as CPU usage, memory, data skew, query execution time, and I/O wait times helps pinpoint bottlenecks. For example, long-running queries in Synapse may benefit from indexing strategies, materialized views, or a re-design of the data distribution strategy.
Similarly, Data Factory performance can be improved by batching records, choosing the correct integration runtime, or breaking down large datasets into manageable chunks using parameterized pipelines. Cost management is also part of performance optimization, and knowing how to reduce unnecessary data scans or idle compute time is vital.
Implementing Metadata And Lineage Tracking
Data lineage and metadata management are essential in maintaining trust and understanding in data systems. The DP-203 exam touches upon implementing data catalogs, managing metadata, and tracking data flow from source to destination.
Azure Purview or similar cataloging services provide centralized metadata repositories that store details about datasets, including schema, ownership, classification, and quality metrics. Integrating these with your pipelines allows for improved discoverability and governance.
Lineage tracking helps debug issues in complex workflows and supports auditing and impact analysis. Whether you are ingesting data from raw logs or delivering it to dashboards, knowing every transformation and movement builds confidence in the data.
Automation plays a key role here. Instead of relying on manual documentation, modern data platforms use metadata-driven pipelines and lineage tracking tools to dynamically update system knowledge as changes occur.
Managing Data Security And Compliance In Azure Data Solutions
Understanding data security is vital for a data engineer. Azure provides numerous tools and policies to safeguard data, ensure access control, and meet compliance standards. In the context of the DP-203 exam, mastering these concepts is crucial, especially since the modern data landscape demands strict governance and privacy awareness.
Implementing Data Encryption At Rest And In Transit
Data encryption is one of the fundamental strategies to ensure data confidentiality and integrity. In Azure, data at rest can be encrypted using Azure Storage Service Encryption for blob storage, Data Lake, and Azure SQL Database. Encryption at rest ensures that even if storage media is compromised, the data remains inaccessible without proper keys.
Data in transit, such as data moving between services or users accessing data via tools, can be protected using Transport Layer Security. This is typically enabled by default in Azure services. As a data engineer, you must understand how to enforce encryption during data movement operations using tools like Azure Data Factory and Azure Synapse Pipelines.
Controlling Access Using Role Based Access Control
Role based access control allows fine grained access management for Azure resources. It uses built in roles like reader, contributor, and owner, as well as custom roles tailored to your data environment. You need to grant only the necessary permissions based on the principle of least privilege.
For instance, a data pipeline might need access to read from one storage container and write to another. Assigning a system assigned managed identity to the pipeline and configuring RBAC roles on the resources ensures secure access without managing secrets.
Using Managed Identity For Secure Access
A managed identity in Azure eliminates the need to manage credentials when accessing resources. Services like Azure Data Factory, Azure Synapse, and Azure Databricks support managed identity, allowing them to authenticate with services like Azure Key Vault, Blob Storage, and SQL Database.
During the exam, expect questions that test your knowledge of integrating managed identities into data solutions. You might be asked to troubleshoot authentication failures due to missing permissions or misconfigured identities.
Leveraging Azure Key Vault For Secret Management
Azure Key Vault allows secure storage and access control over secrets, certificates, and encryption keys. You can reference secrets directly in data pipeline configurations, ensuring that sensitive information like database passwords or access keys is not hard coded in code or configuration files.
A scenario might involve configuring an Azure Synapse linked service to use a credential stored in Azure Key Vault. Understanding the Key Vault integration and permission assignment is key to implementing secure, maintainable solutions.
Monitoring And Auditing Data Operations
Monitoring and auditing are essential to ensure system health, detect anomalies, and maintain compliance. Azure Monitor, Log Analytics, and Azure Activity Logs are primary tools used for this purpose. For example, you can configure diagnostic settings on Azure SQL Database to route logs and metrics to Log Analytics and analyze performance bottlenecks or unauthorized access attempts.
In data engineering solutions, it’s critical to monitor pipeline failures, data latency, and resource utilization. You should also set up alerts to notify responsible teams when thresholds are breached.
Implementing Data Retention And Purge Policies
Compliance often requires data to be retained for a specific period or purged after its lifecycle ends. Azure provides capabilities like lifecycle management in Blob Storage, which automates tiering and deletion based on rules. Similarly, Azure Purview can define policies for data lifecycle and classify data for regulatory purposes.
Data engineers must balance operational efficiency with regulatory requirements. Implementing these policies correctly minimizes storage costs while meeting legal standards.
Classifying Data For Governance
Data classification involves labeling data based on its sensitivity and importance. Azure Purview enables automated scanning and classification of data sources, allowing you to tag data such as personally identifiable information or financial records.
In exam scenarios, you might be asked how to enforce governance rules based on classification tags, or how to restrict access to data containing sensitive attributes. Knowing how data classification integrates into security policies is essential.
Building Resilient And Reliable Data Pipelines
Reliability is a core architectural pillar in Azure. When building data pipelines, ensuring that systems can handle failures, retries, and fallback operations is a must. Azure Data Factory offers built in features like retry policies, dependency conditions, and fault tolerance.
Implementing checkpoints in pipelines and using durable task mechanisms in Azure Data Factory ensures data is not duplicated or lost. In Synapse pipelines, activities like conditional logic and error paths allow you to control execution flow based on runtime behavior.
Managing Pipeline Failures And Recovery
As a data engineer, you must prepare for various failure points such as API timeouts, data corruption, and service outages. In Azure Data Factory, you can configure the pipeline to send failure notifications using webhooks or Logic Apps, and implement custom logic to rerun or skip failed activities.
Using Azure Monitor integration with Data Factory, you can track execution history, visualize pipeline runs, and drill down into error details. Recovery strategies include idempotent data operations and transactional data loading.
Designing High Availability Architectures
High availability ensures that your data workloads continue functioning even when some components fail. This can involve strategies like geo redundancy, load balancing, and distributed systems.
For example, Azure SQL Database supports active geo replication and failover groups. Azure Storage accounts can be configured for zone redundancy to survive regional failures. Your role as a data engineer includes designing solutions that avoid single points of failure.
Scaling Azure Data Solutions
Azure offers both vertical and horizontal scaling capabilities. In Synapse Analytics, scaling is managed using dedicated SQL pools or serverless on demand pools. With Data Factory, scaling is implicit as integration runtimes scale based on demand.
Understanding how to manage and optimize scale ensures consistent performance and cost efficiency. You’ll also need to configure auto scaling in Databricks clusters or adjust throughput in Cosmos DB based on workload patterns.
Optimizing Performance Of Data Pipelines
Performance tuning is a frequent requirement in real world solutions and appears in many exam questions. It involves optimizing pipeline activities, reducing data movement, and using efficient file formats.
For example, loading data into a Synapse dedicated pool is faster using PolyBase with compressed parquet files than unstructured CSVs. Choosing the correct data partitioning strategy also reduces query latency and resource consumption.
Azure Data Factory performance can be improved by parallelizing data movement, tuning batch sizes, and eliminating unnecessary transformations during movement stages.
Cost Management In Data Solutions
Designing cost effective solutions is a key responsibility. Azure Cost Management tools allow you to monitor and forecast resource usage, set budgets, and implement governance.
In the exam, you may encounter scenarios where you must choose between premium and standard tiers, or design workflows that minimize compute hours and storage consumption. Selecting the right pricing tier, optimizing data storage formats, and using serverless compute when possible all contribute to cost efficiency.
Using Serverless Technologies In Data Engineering
Serverless options like Azure Synapse serverless SQL pools and Azure Functions allow you to run compute workloads on demand. These are especially useful for event driven or ad hoc data processing.
For example, using serverless SQL pools to query data in Data Lake without provisioning compute saves time and cost. Combining Azure Event Grid with Azure Functions allows real time data transformation triggered by events such as blob creation or IoT telemetry.
Monitoring Cost And Usage Patterns
Regularly tracking usage patterns helps in identifying resource wastage and opportunities for optimization. You can configure cost alerts and build dashboards in Power BI or Log Analytics to visualize data pipeline utilization.
As a best practice, tag all resources with cost center or environment metadata to help analyze costs effectively across teams and projects.
Ensuring Data Integrity And Validation
Data validation is a critical step in data pipelines. You must ensure that incoming data meets schema requirements and contains valid values. Azure Data Factory provides Data Flow components for validation and transformation.
Building a data quality layer helps in identifying anomalies early and prevents bad data from propagating. For instance, you can add a validation step before loading to Synapse or Databricks that checks for null values in primary key columns or ensures date formats are consistent.
Integrating With Real Time Data Streams
Modern data applications often require real time insights. Azure offers services like Event Hubs, Azure Stream Analytics, and Azure Data Explorer to manage streaming data.
Data engineers must understand the design and implementation of stream ingestion pipelines. For example, reading telemetry from IoT devices through Event Hubs, processing it with Stream Analytics, and persisting the results in Cosmos DB or Synapse for downstream analytics.
Streaming workloads have different performance, scaling, and schema evolution considerations compared to batch data. Preparing for these differences is vital for DP-203 success.
Conclusion
The journey to earning the Azure Data Engineer certification through the DP-203 exam is both a technical and strategic endeavor. It demands a deep understanding of data storage, transformation, security, and performance optimization on Azure platforms. Those who take the time to build hands-on experience with tools such as Azure Data Factory, Synapse Analytics, Databricks, and Data Lake Storage stand out not only in passing the exam but also in real-world applications.
This certification is not merely about clearing an exam—it marks your ability to build and manage reliable data solutions that align with organizational needs. It challenges you to think holistically about data architecture, governance, integration, and real-time processing. As enterprises grow more data-driven, certified professionals with this skill set become essential for innovation and operational efficiency.
A successful preparation strategy includes consistent practice, lab-based exploration, and reviewing scenarios that reflect real business problems. Leveraging this preparation process as a foundation, professionals can transition into roles that involve decision-making, cross-functional collaboration, and technical leadership.
Ultimately, the DP-203 exam is more than a milestone. It opens doors to advanced roles, deeper learning, and a stronger influence within cloud and data engineering domains. Those who master the knowledge areas it covers are well-positioned to lead in a future defined by data intelligence, automation, and cloud-first architecture. Let this certification be your stepping stone to continuous growth and contribution in the evolving world of cloud data engineering.
Microsoft Azure DP-203 practice test questions and answers, training course, study guide are uploaded in ETE Files format by real users. Study and Pass DP-203 Data Engineering on Microsoft Azure certification exam dumps & practice test questions and answers are to help students.
- AZ-104 - Microsoft Azure Administrator
- DP-700 - Implementing Data Engineering Solutions Using Microsoft Fabric
- AZ-305 - Designing Microsoft Azure Infrastructure Solutions
- AB-100 - Agentic AI Business Solutions Architect
- MD-102 - Endpoint Administrator
- SC-300 - Microsoft Identity and Access Administrator
- PL-300 - Microsoft Power BI Data Analyst
- AI-900 - Microsoft Azure AI Fundamentals
- MS-102 - Microsoft 365 Administrator
- AZ-900 - Microsoft Azure Fundamentals
- AB-900 - Microsoft 365 Copilot and Agent Administration Fundamentals
- SC-401 - Administering Information Security in Microsoft 365
- SC-200 - Microsoft Security Operations Analyst
- AI-102 - Designing and Implementing a Microsoft Azure AI Solution
- AZ-700 - Designing and Implementing Microsoft Azure Networking Solutions
- DP-600 - Implementing Analytics Solutions Using Microsoft Fabric
- AB-730 - AI Business Professional
- AB-731 - AI Transformation Leader
- SC-100 - Microsoft Cybersecurity Architect
- AZ-500 - Microsoft Azure Security Technologies
- PL-400 - Microsoft Power Platform Developer
- AZ-204 - Developing Solutions for Microsoft Azure
- GH-300 - GitHub Copilot
- SC-900 - Microsoft Security, Compliance, and Identity Fundamentals
- AZ-140 - Configuring and Operating Microsoft Azure Virtual Desktop
- DP-300 - Administering Microsoft Azure SQL Solutions
- AZ-400 - Designing and Implementing Microsoft DevOps Solutions
- AI-103 - Developing AI Apps and Agents on Azure
- PL-600 - Microsoft Power Platform Solution Architect
- AZ-801 - Configuring Windows Server Hybrid Advanced Services
- MS-700 - Managing Microsoft Teams
- MB-800 - Microsoft Dynamics 365 Business Central Functional Consultant
- PL-200 - Microsoft Power Platform Functional Consultant
- AZ-800 - Administering Windows Server Hybrid Core Infrastructure
- PL-900 - Microsoft Power Platform Fundamentals
- MB-330 - Microsoft Dynamics 365 Supply Chain Management
- AI-300 - Operationalizing Machine Learning and Generative AI Solutions
- MB-310 - Microsoft Dynamics 365 Finance Functional Consultant
- DP-900 - Microsoft Azure Data Fundamentals
- MB-280 - Microsoft Dynamics 365 Customer Experience Analyst
- MB-820 - Microsoft Dynamics 365 Business Central Developer
- MB-230 - Microsoft Dynamics 365 Customer Service Functional Consultant
- DP-100 - Designing and Implementing a Data Science Solution on Azure
- MS-721 - Collaboration Communications Systems Engineer
- GH-200 - GitHub Actions
- MB-700 - Microsoft Dynamics 365: Finance and Operations Apps Solution Architect
- MB-500 - Microsoft Dynamics 365: Finance and Operations Apps Developer
- MB-335 - Microsoft Dynamics 365 Supply Chain Management Functional Consultant Expert
- GH-900 - GitHub Foundations
- PL-500 - Microsoft Power Automate RPA Developer
- DP-420 - Designing and Implementing Cloud-Native Applications Using Microsoft Azure Cosmos DB
- SC-500 - Implementing End-to-End Security Controls for Cloud and AI Workloads
- MS-900 - Microsoft 365 Fundamentals
- AI-901 - Microsoft Azure AI Fundamentals
- GH-500 - GitHub Advanced Security
- DP-800 - Developing AI-Enabled Database Solutions
- GH-100 - GitHub Administration
- AZ-120 - Planning and Administering Microsoft Azure for SAP Workloads
- SC-400 - Microsoft Information Protection Administrator
- MB-240 - Microsoft Dynamics 365 for Field Service
- 98-382 - Introduction to Programming Using JavaScript
- DP-203 - Data Engineering on Microsoft Azure
- DP-750 - Implementing Data Engineering Solutions Using Azure Databricks
- MO-200 - Microsoft Excel (Excel and Excel 2019)
- MB-910 - Microsoft Dynamics 365 Fundamentals Customer Engagement Apps (CRM)
- 98-367 - Security Fundamentals
- MB-920 - Microsoft Dynamics 365 Fundamentals Finance and Operations Apps (ERP)
- 62-193 - Technology Literacy for Educators
- 98-383 - Introduction to Programming Using HTML and CSS
- MO-400 - Microsoft Outlook (Outlook and Outlook 2019)
- MS-203 - Microsoft 365 Messaging
Purchase DP-203 Exam Training Products Individually
Why customers love us?
What do our customers say?
The resources provided for the Microsoft certification exam were exceptional. The exam dumps and video courses offered clear and concise explanations of each topic. I felt thoroughly prepared for the DP-203 test and passed with ease.
Studying for the Microsoft certification exam was a breeze with the comprehensive materials from this site. The detailed study guides and accurate exam dumps helped me understand every concept. I aced the DP-203 exam on my first try!
I was impressed with the quality of the DP-203 preparation materials for the Microsoft certification exam. The video courses were engaging, and the study guides covered all the essential topics. These resources made a significant difference in my study routine and overall performance. I went into the exam feeling confident and well-prepared.
The DP-203 materials for the Microsoft certification exam were invaluable. They provided detailed, concise explanations for each topic, helping me grasp the entire syllabus. After studying with these resources, I was able to tackle the final test questions confidently and successfully.
Thanks to the comprehensive study guides and video courses, I aced the DP-203 exam. The exam dumps were spot on and helped me understand the types of questions to expect. The certification exam was much less intimidating thanks to their excellent prep materials. So, I highly recommend their services for anyone preparing for this certification exam.
Achieving my Microsoft certification was a seamless experience. The detailed study guide and practice questions ensured I was fully prepared for DP-203. The customer support was responsive and helpful throughout my journey. Highly recommend their services for anyone preparing for their certification test.
I couldn't be happier with my certification results! The study materials were comprehensive and easy to understand, making my preparation for the DP-203 stress-free. Using these resources, I was able to pass my exam on the first attempt. They are a must-have for anyone serious about advancing their career.
The practice exams were incredibly helpful in familiarizing me with the actual test format. I felt confident and well-prepared going into my DP-203 certification exam. The support and guidance provided were top-notch. I couldn't have obtained my Microsoft certification without these amazing tools!
The materials provided for the DP-203 were comprehensive and very well-structured. The practice tests were particularly useful in building my confidence and understanding the exam format. After using these materials, I felt well-prepared and was able to solve all the questions on the final test with ease. Passing the certification exam was a huge relief! I feel much more competent in my role. Thank you!
The certification prep was excellent. The content was up-to-date and aligned perfectly with the exam requirements. I appreciated the clear explanations and real-world examples that made complex topics easier to grasp. I passed DP-203 successfully. It was a game-changer for my career in IT!


