Pass Google Professional Cloud Architect Certification Exam in First Attempt Guaranteed!
Get 100% Latest Exam Questions, Accurate & Verified Answers to Pass the Actual Exam!
30 Days Free Updates, Instant Download!


Professional Cloud Architect Premium Bundle
- Premium File 360 Questions & Answers. Last update: Jun 26, 2026
- Training Course 63 Video Lectures
- Study Guide 491 Pages
Professional Cloud Architect Premium Bundle
- Premium File 360 Questions & Answers
Last update: Jun 26, 2026 - Training Course 63 Video Lectures
- Study Guide 491 Pages
Purchase Individually

Premium File

Training Course

Study Guide
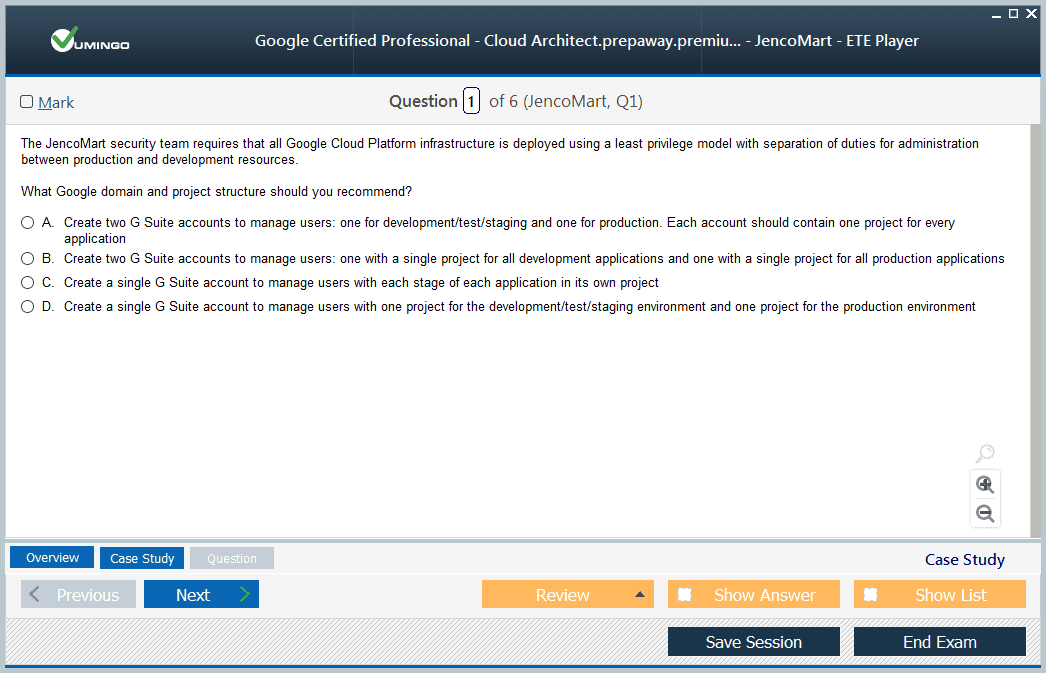
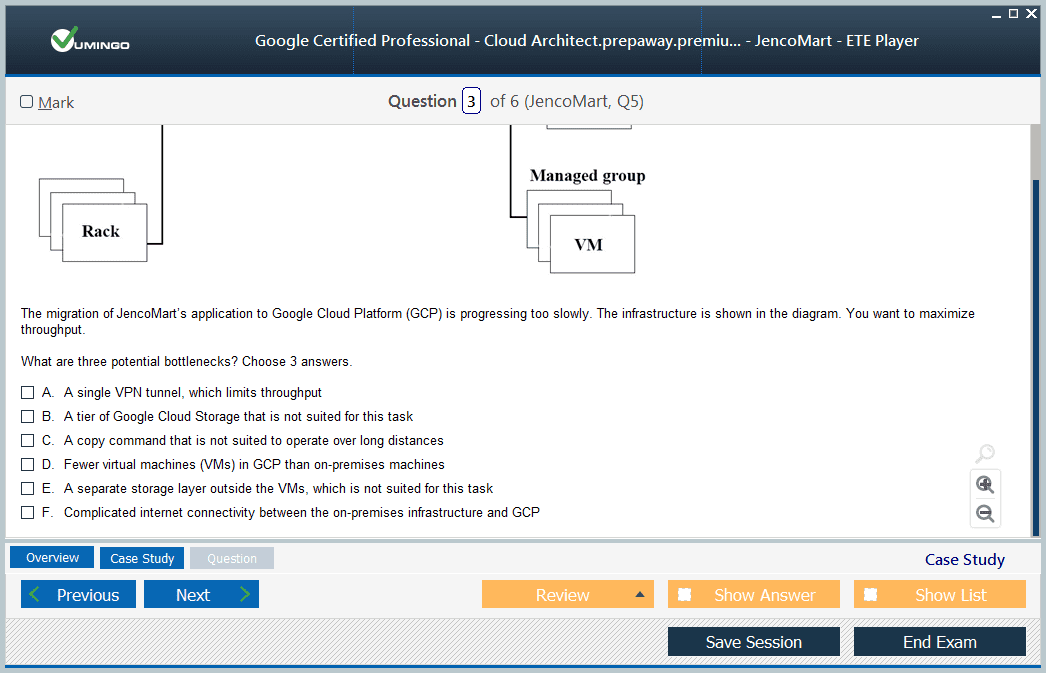
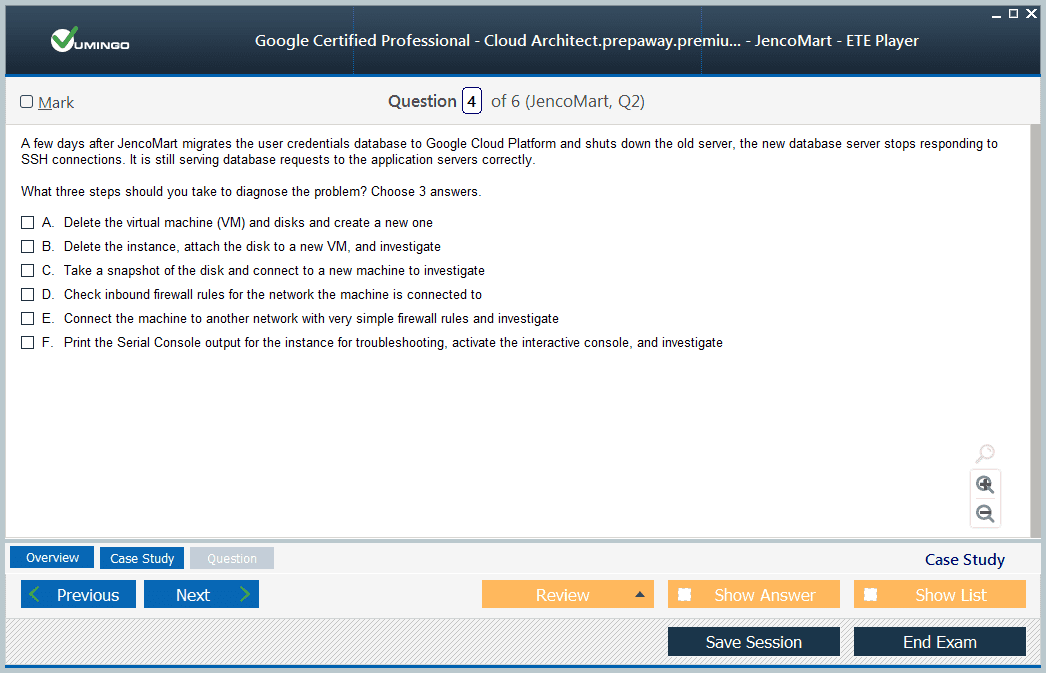
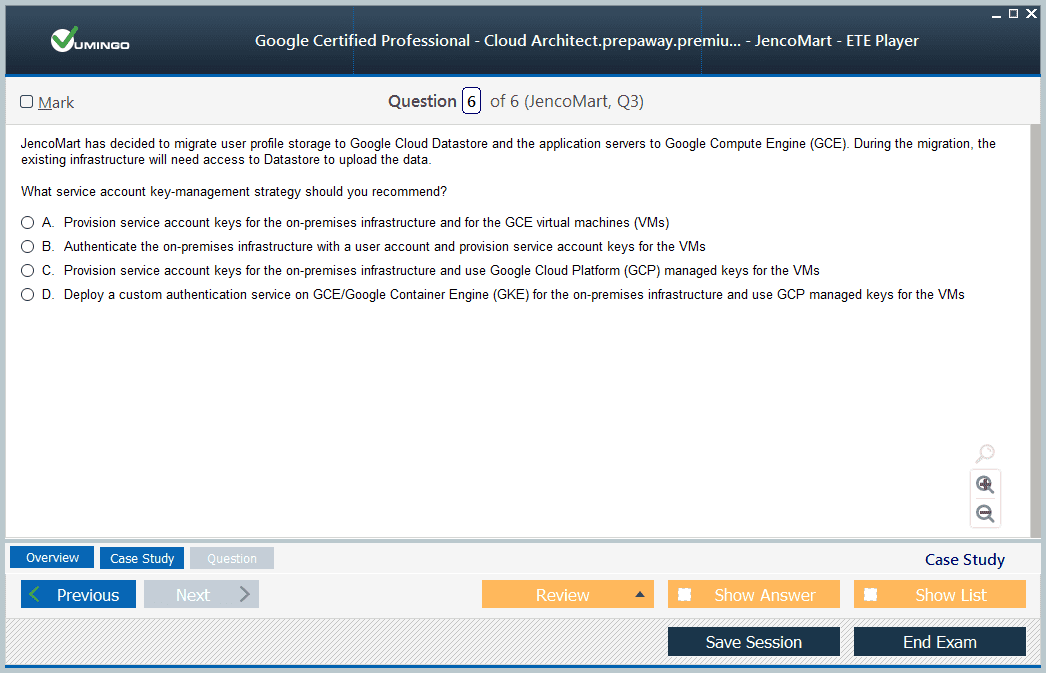








Professional Cloud Architect Exam - Google Cloud Certified - Professional Cloud Architect
| Download Free Professional Cloud Architect Exam Questions |
|---|
Google Professional Cloud Architect Certification Practice Test Questions and Answers, Google Professional Cloud Architect Certification Exam Dumps
All Google Professional Cloud Architect certification exam dumps, study guide, training courses are prepared by industry experts. Google Professional Cloud Architect certification practice test questions and answers, exam dumps, study guide and training courses help candidates to study and pass hassle-free!
The Professional Cloud Architect - Core Infrastructure and Compute
Embarking on the path to become a certified Professional Cloud Architect is a significant step in any technology professional's career. This certification is designed for individuals who can design, develop, and manage robust, secure, scalable, highly available, and dynamic solutions to drive business objectives. It is not merely a test of product knowledge but a rigorous evaluation of your ability to apply cloud principles to solve real-world business challenges. The credential validates your expertise in cloud architecture and your deep understanding of the leading cloud provider's platform and technologies. To succeed, a candidate must demonstrate proficiency across a wide range of competencies. This includes planning and designing cloud solution architecture, managing and provisioning infrastructure, designing for security and compliance, and optimizing technical and business processes. The exam is known for its focus on business requirements and case studies, pushing candidates to think like a seasoned architect who must balance technical feasibility, cost-effectiveness, and operational excellence. It is a certification that truly signifies a professional's ability to translate business needs into technical cloud solutions, making it highly respected and sought after in the industry.
The Critical Role of Hands-On Practice
While theoretical knowledge is the essential starting point for any certification, the Professional Cloud Architect exam demands more than just rote memorization of concepts. The scenario-based questions require a deep, intuitive understanding of how services interact and behave, an understanding that can only be forged through practical, hands-on experience. Reading about a virtual private cloud is one thing; designing, configuring, and troubleshooting one in a live environment is an entirely different level of learning. Hands-on labs bridge this crucial gap between theory and practice, moving knowledge from the abstract to the concrete. These labs provide a safe, controlled environment where you can experiment with platform services without the fear of breaking a production system or incurring unexpected costs. They allow you to build muscle memory, internalize command-line syntax, and navigate the cloud management interface with confidence. By working through guided exercises that mirror real-world tasks, you develop the problem-solving skills and practical intuition that are essential for answering the exam's complex questions and for succeeding in a real-world cloud architect role. Practical application is not just a study aid; it is a fundamental requirement for mastery.
Mastering the Command Line and SDK
Before an architect can design complex systems, they must be fluent in the fundamental tools used to interact with the cloud platform. The command-line interface (CLI) and the associated Software Development Kit (SDK) are the bedrock of automation and efficient management. A hands-on lab focused on these tools is the perfect starting point. Such an exercise typically involves using the in-browser cloud shell environment to perform basic tasks like creating a virtual machine instance or a cloud storage bucket. This builds familiarity with the command structure and syntax in a low-stakes environment. The value of this skill cannot be overstated. While the web-based management interface is excellent for visualization and one-off tasks, the CLI is essential for scripting, automation, and repeatable deployments. An architect must be comfortable with the CLI to write automation scripts, troubleshoot issues from a terminal, and integrate cloud operations with CI/CD pipelines. This lab helps you understand the power and efficiency of managing cloud resources programmatically, a core competency for any modern cloud professional and a key element in provisioning and managing solution infrastructure as tested on the exam.
Deep Dive into Core Compute Services
The virtual machine, or compute instance, is the fundamental unit of computing in the cloud. A comprehensive lab on this topic is non-negotiable for any aspiring architect. This type of lab guides you through the process of creating a virtual machine instance, typically with a standard operating system like Ubuntu. The exercise involves more than just clicking a "create" button; it requires you to make architectural decisions. You will select a machine type, choose a geographic region and zone, and configure the boot disk, all of which are critical considerations for performance, cost, and availability. This hands-on experience directly maps to the exam domain of planning and designing cloud solution architecture. The lab will also involve connecting to the instance via SSH, giving you practical experience with secure remote access. Some labs even extend to configuring a graphical user interface on a Linux instance and connecting via RDP, demonstrating the versatility of cloud compute for different workloads. Mastering the creation and management of compute instances is the first major step in learning how to build and deploy applications on the platform, forming the foundation for more advanced topics.
Automating with Startup and Shutdown Scripts
Efficiency and consistency are hallmarks of a well-designed cloud architecture. A lab that explores the use of startup and shutdown scripts in compute instances is an excellent way to learn about instance lifecycle automation. These scripts are powerful tools that allow you to execute commands or run code automatically whenever an instance is started or stopped. A typical lab exercise involves creating a virtual machine and providing a simple startup script that installs a web server or other software. When the instance boots up, you can verify that the script executed successfully and the software is running. This practical exercise teaches the concept of bootstrapping, which is the process of preparing a server for service automatically. It is a cornerstone of creating immutable infrastructure, where servers are never modified after deployment but are instead replaced with new instances built from a consistent template. An architect needs to understand this principle to design scalable and self-healing systems. Shutdown scripts are equally important for performing graceful shutdown tasks, such as saving application state or deregistering from a load balancer, ensuring system reliability, a key objective of the certification.
Ensuring Data Durability with Persistent Disk Backups
Data is the lifeblood of any application, and an architect's primary responsibility is to ensure its protection and availability. A hands-on lab focused on persistent disk backups, snapshots, and scheduled snapshots is crucial for understanding data management in the cloud. In such a lab, you would typically start by creating a persistent storage disk and attaching it to a compute instance. You then learn how to create a manual snapshot of that disk, which serves as a point-in-time backup. This process demonstrates a fundamental disaster recovery technique. The lab then progresses to a more advanced and architecturally sound approach: automating backups. You will learn how to create a snapshot schedule, which automatically creates snapshots of your disks on a recurring basis, such as daily or weekly. This hands-on experience is directly relevant to designing for reliability and business continuity. It teaches you how to implement automated backup strategies that reduce the risk of data loss from accidental deletion, application errors, or system failure, a critical consideration in any production environment and a frequent topic in exam scenarios.
Designing for Elasticity with Autoscaling
One of the most powerful capabilities of the cloud is the ability to automatically scale resources to meet demand. A hands-on lab on autoscaling is essential for any architect who needs to design cost-effective and high-performing applications. The lab typically begins with the creation of an instance template. This is a reusable definition of a virtual machine's properties, including its machine type, boot disk image, and startup script. This step reinforces the concept of creating consistent, repeatable configurations, which is the foundation of effective autoscaling. Next, you will create a managed instance group based on this template and configure an autoscaling policy. This policy defines the criteria for adding or removing instances, most commonly based on CPU utilization. By generating a load on the instances, you can watch the autoscaler automatically add new virtual machines to the group to handle the increased demand. This practical demonstration brings the concept of elasticity to life, showing you how to build systems that are both resilient to traffic spikes and cost-efficient during quiet periods, a core principle of cloud architecture.
The Blueprint of the Cloud: Virtual Networking
A secure and well-designed network is the foundation upon which all cloud solutions are built. For a Professional Cloud Architect, a deep understanding of virtual networking is not optional; it is a prerequisite for designing any non-trivial system. A virtual private cloud (VPC) provides a private, isolated network environment within the public cloud, giving you complete control over your IP address space, subnets, routing, and firewall rules. It is the logical boundary that protects your resources from the public internet and from other tenants on the platform, making it the first thing you design in a new project. An architect must be able to design a VPC architecture that meets the specific needs of an application. This includes deciding whether to use the default network, which is suitable for simple projects, or a custom-mode VPC for more complex, production-grade environments. A custom VPC allows you to define your own IP ranges and subnets, providing greater control and security. This decision has long-term implications for scalability, security, and connectivity, making a solid grasp of VPC fundamentals absolutely essential for the exam and for real-world success.
Infrastructure as Code with Network Automation
Manually configuring network resources through a web interface is feasible for small projects, but it does not scale and is prone to human error. Modern cloud architecture relies on the principle of Infrastructure as Code (IaC), where infrastructure is defined and managed using machine-readable definition files. A hands-on lab that uses a tool like Terraform to deploy a VPC network is an invaluable experience for an aspiring architect. In such a lab, you will write a configuration file that declaratively defines your VPC, its subnets, and its firewall rules. With a single command, you can then instruct the IaC tool to provision all these resources in the correct order. This demonstrates a powerful, repeatable, and version-controlled approach to infrastructure management. If you need to make a change, you simply update the code and re-apply it. This lab teaches you how to automate the creation of your network backbone, ensuring consistency across different environments like development, staging, and production. This is a core skill for managing implementation and ensuring reliability, two key domains of the Professional Cloud Architect exam.
Understanding Network Security with Firewalls
Network security is a paramount concern for any cloud architect. A hands-on lab that focuses on firewall rules and their priorities provides practical insight into how to secure your virtual network. Firewall rules in the cloud control the ingress (incoming) and egress (outgoing) traffic to and from your virtual machine instances. A typical lab exercise involves creating multiple firewall rules with different priorities and then observing their effect on network traffic. For example, you might create a high-priority rule to deny all SSH traffic and a lower-priority rule to allow it, demonstrating that the higher-priority rule takes precedence. This type of lab is crucial for understanding the principle of least privilege, a foundational concept in security. You learn how to use network tags to apply specific firewall rules to groups of instances, allowing for a more scalable and manageable security posture. By creating two instances and attempting to ping between them while modifying firewall rules and tags, you gain a tangible understanding of how these rules are evaluated and enforced. This practical experience is essential for designing secure network architectures and for answering scenario-based security questions on the exam.
Distributing Traffic with Foundational Load Balancing
Load balancing is a fundamental technique for building scalable and highly available applications. An introductory lab on this topic is an essential part of the learning path. This type of lab typically focuses on a foundational load balancer, such as a regional TCP/UDP load balancer. The exercise involves creating a backend service or target pool that contains a group of virtual machine instances that will serve the application traffic. You then configure the load balancer to distribute incoming requests across these instances. This ensures that no single instance is overwhelmed and provides redundancy if one instance fails. The lab also requires you to create a forwarding rule, which ties a public IP address to your backend service. This gives your application a single, stable entry point for users. You will also create a firewall rule to allow traffic from the load balancer to reach your backend instances. By completing this lab, you gain practical experience with all the moving parts of a basic load balancing setup. This knowledge is the foundation for understanding more advanced load balancing solutions and for designing resilient application architectures that can handle failures gracefully.
Advanced Application Delivery with HTTP(S) Load Balancing
For web-based applications, a more sophisticated type of load balancer is required. A hands-on lab focused on HTTP(S) load balancing is critical for any architect designing modern applications. Unlike a network load balancer that simply forwards traffic, an HTTP(S) load balancer is a global, managed service that operates at the application layer. It can make intelligent routing decisions based on the content of the HTTP request, such as the URL path or the host header. This allows for more advanced traffic management, such as routing requests for "/video" to one set of backends and "/images" to another. This lab will guide you through creating an instance template and a managed instance group to serve as your backend. You will then configure a global HTTP(S) load balancer, including setting up a URL map for routing rules and configuring a health check to monitor the status of your backends. A key feature of this load balancer is its ability to handle SSL termination, offloading the cryptographic processing from your instances. This hands-on experience is vital for designing globally distributed, high-performance, and secure web applications.
Choosing the Right Load Balancer
The cloud platform offers a variety of load balancing solutions, each designed for different use cases. A key skill for a cloud architect is the ability to choose the right one for a given scenario. The platform typically provides global external load balancers for web traffic, regional external load balancers for other TCP/UDP traffic, and regional internal load balancers for traffic within your VPC. A lab that covers the implementation of a network load balancer provides a valuable point of comparison to the HTTP(S) load balancer. The network load balancer operates at a lower level and is suitable for non-HTTP traffic, such as for database or gaming servers. By implementing both types in hands-on labs, you develop a practical understanding of their differences in scope, features, and configuration. This knowledge is directly tested on the Professional Cloud Architect exam, which often presents scenarios that require you to select the most appropriate load balancing solution based on technical requirements for traffic type, geographic scope, and performance. Hands-on experience makes this decision process intuitive rather than purely academic.
Managing Stateful Applications with Sticky Sessions
While many modern applications are designed to be stateless, there are still many legacy or specific workloads that require a client to be consistently routed to the same backend instance. This is known as session affinity or a "sticky session." A hands-on lab that demonstrates how to enable this feature on an HTTP(S) load balancer is important for architects who need to support these types of applications. The lab typically involves creating an instance group and a load balancer, and then enabling the session affinity feature in the backend service configuration. To validate that it is working, you would access the web application through the load balancer's IP address. The first request would be routed to one of the backend instances. Subsequent requests from the same client should then be consistently routed to that same instance for the duration of the session. This lab teaches a practical technique for handling stateful applications in a scalable way. It is another example of a specific architectural pattern that an architect must have in their toolkit to address diverse business and technical requirements.
Advanced Traffic Management with Routing Rules
Modern application delivery often requires more sophisticated traffic management than simple round-robin distribution. A lab that explores the use of routing rules, also known as URL maps, in an HTTP(S) load balancer provides insight into these advanced capabilities. This type of lab typically involves creating two different backend services, each serving a different version of an application or different types of content. You would then configure the load balancer's URL map to route traffic based on the request path. For example, requests to "/app1" go to the first backend, and requests to "/app2" go to the second. This hands-on exercise demonstrates how a single load balancer can be used to direct traffic for multiple microservices or to perform path-based routing. This is a common pattern in modern, microservices-based architectures. The lab might also extend to configuring host-based routing, where traffic is directed based on the domain name in the request. These advanced routing capabilities are a key feature of the global load balancer and a powerful tool for an architect designing complex, distributed applications, making this a crucial lab for exam preparation.
Foundations of Object Storage
For a cloud architect, understanding the different types of storage is fundamental, and object storage is one of the most versatile and widely used services. A hands-on lab that introduces the platform's object storage service, often referred to as a storage bucket, is an essential starting point. This type of lab guides you through the process of creating a bucket, which is a container for your data. During creation, you must make key architectural decisions, such as choosing a globally unique name, selecting a geographic location for the data, and picking a default storage class. The lab then proceeds to demonstrate how to upload and manage objects, which can be any kind of file, such as images, videos, or log files. You will learn how to organize data using folders and how to access your objects via a unique URL. This practical experience is crucial because object storage is the foundation for a vast number of cloud use cases, including data lakes, backup and archival, and content delivery. Understanding its basic operations is a prerequisite for building almost any solution on the cloud.
Securing and Sharing Data in Object Storage
Once data is in a storage bucket, an architect must know how to control access to it. A lab on object storage should cover the critical aspects of security and sharing. You will learn about the principle of uniform bucket-level access and the more granular, fine-grained access controls. A key exercise involves configuring Identity and Access Management (IAM) permissions, granting specific users or services the ability to read or write data in the bucket. This demonstrates the standard, recommended way to manage access within your organization, adhering to the principle of least privilege. The lab will also explore how to make an object publicly accessible on the internet, a common requirement for hosting static assets like images or CSS files. You will learn the security implications of this action and how to configure it correctly. This hands-on practice is directly relevant to the exam's domain of designing for security and compliance. It provides a tangible understanding of how to implement secure data storage policies and manage access control for one of the most fundamental services on the platform.
High-Performance Content Delivery with a CDN
Delivering content to a global user base with low latency and high performance is a common architectural challenge. A hands-on lab that combines object storage with a Content Delivery Network (CDN) provides a practical solution. This lab typically starts with you hosting a simple static website directly from an object storage bucket. You upload your HTML, CSS, and image files to the bucket and configure it to serve web pages. This alone is a powerful and cost-effective hosting pattern. The lab then takes it a step further by integrating the platform's CDN service. You will configure an HTTP(S) load balancer with a backend bucket pointing to your object storage. Then, you enable the CDN on this backend. This simple checkbox action automatically begins caching your static content at the cloud provider's edge locations around the world. When a user requests the content, it is served from the edge location closest to them, dramatically reducing latency. This lab provides a hands-on demonstration of how to design a high-performance, globally scalable solution for static content.
Managing Relational Data with Cloud SQL
Many applications rely on traditional relational databases to store structured data. A hands-on lab on the platform's managed relational database service, often called Cloud SQL, is essential for any architect. This lab guides you through the process of creating a new database instance, a task that involves several key architectural decisions. You will need to choose a database engine, such as MySQL or PostgreSQL, select a machine size, and configure storage. This process highlights the benefits of a managed service, which handles the underlying infrastructure and administrative tasks. Once the instance is running, the lab will walk you through connecting to it, typically using the in-browser cloud shell. You will create a database, define a table schema, and insert some sample data using standard SQL commands. This practical exercise demonstrates the entire lifecycle of a managed database, from provisioning to operation. For an architect, it is crucial to have hands-on experience with this service to design solutions that require a reliable, scalable, and easy-to-manage relational database backend, a very common business requirement.
Choosing Between Serverless and Cluster-Based Big Data Processing
The world of big data processing offers a spectrum of tools, and an architect must be able to choose the right one for the job. A comparative hands-on lab that explores both a serverless data processing service (like Dataflow) and a managed cluster service (like Dataproc) is incredibly valuable. This lab helps you understand the fundamental trade-offs between these two approaches. The serverless option abstracts away the underlying infrastructure, allowing you to focus purely on your data processing logic, making it ideal for stream and batch processing pipelines. In contrast, the managed cluster service gives you a fully managed Hadoop and Spark cluster, providing more control and compatibility with the open-source ecosystem. A lab that has you run a simple data processing job on both platforms provides a powerful comparison. You will experience the simplicity of submitting a serverless job versus the process of creating, managing, and submitting a job to a cluster. This hands-on experience is critical for making informed architectural decisions for big data workloads, a specialized but important area covered on the exam.
Managed Big Data Clusters with Dataproc
For organizations that have existing investments in the Hadoop and Spark ecosystem, or for workloads that require fine-grained control over the cluster environment, a managed cluster service is the ideal choice. A hands-on lab focused on this service will typically involve using the command line or the web interface to create a new cluster. This process requires you to specify the number and type of master and worker nodes, giving you direct control over the cluster's size and power. Once the cluster is provisioned, the lab will guide you through submitting a job to it. A common example is a simple Spark job that performs a calculation, like estimating the value of Pi. You submit the job, wait for it to complete, and then view the output. The lab might also include steps on how to update or resize the cluster while it is running. This practical exercise provides a solid understanding of how to use a managed service to quickly stand up and operate big data clusters, offloading the administrative burden of managing the underlying infrastructure.
The Importance of Automation and Orchestration
A key responsibility of a Professional Cloud Architect is to design systems that are not only powerful but also manageable, repeatable, and automated. Manual configuration and deployment are simply not viable for modern, large-scale cloud environments. Automation reduces the risk of human error, increases the speed of delivery, and ensures consistency across all environments. This is where automation and orchestration tools become indispensable. They allow an architect to define the desired state of the infrastructure and applications, and then let the tools handle the complex task of making it a reality. Orchestration goes a step beyond simple automation. It involves coordinating multiple automated tasks to execute a complex workflow. For example, deploying a new application might involve provisioning a network, setting up databases, configuring load balancers, and deploying compute instances in a specific sequence. A well-designed orchestration process ensures that all these moving parts come together correctly. Understanding the principles and tools of automation and orchestration is a core competency for the exam and for any effective cloud architect, as it directly impacts the manageability and reliability of the solutions they design.
Configuration Management with Ansible
Configuration management is a critical aspect of automation, focused on ensuring that a system is maintained in a consistent state. A hands-on lab that uses a tool like Ansible to configure a compute engine instance is an excellent way to learn this concept. Ansible is a popular open-source tool that uses a simple, human-readable language (YAML) to define tasks. In a typical lab, you would first install Ansible in the cloud shell environment. Then, you would write an "Ansible Playbook" file. This file contains a set of instructions, such as to install a web server or create a user account. You then execute this playbook against a target virtual machine. Ansible connects to the machine via SSH and runs the tasks you defined, bringing the machine to your desired state. This demonstrates a powerful push-based configuration management model. For an architect, understanding this approach is important for managing fleets of virtual machines, ensuring that they all have a consistent software configuration and security baseline. This skill is directly applicable to the exam domain of managing and provisioning solution infrastructure.
Native Infrastructure as Code
In addition to third-party tools, cloud platforms provide their own native Infrastructure as Code (IaC) services. A hands-on lab that introduces the platform's native deployment manager is crucial for understanding this approach. Similar to other IaC tools, this service allows you to define all the resources for your application in a declarative template file. A lab exercise would involve creating a template file that defines a compute instance and a firewall rule. You would then create a "deployment" based on this template. The deployment manager service reads your template and provisions the specified resources in the correct order. This provides a centralized and platform-native way to manage your infrastructure as a single logical unit. You can update your infrastructure by modifying the template and updating the deployment, and you can easily delete all the resources by deleting the deployment. This hands-on experience provides a valuable comparison to other IaC tools and demonstrates a powerful method for automating the deployment and management of complex cloud solutions.
Event-Driven Automation with Serverless Functions
Modern cloud architectures are increasingly event-driven. A hands-on lab that combines a scheduling service with a serverless functions platform is a perfect introduction to this paradigm. Serverless functions allow you to run small, single-purpose pieces of code in response to events, without managing any underlying servers. A scheduling service, on the other hand, allows you to trigger events on a recurring schedule, much like a traditional cron job. The lab combines these two services to create a powerful automation pattern. In the lab, you will first deploy a simple function that is triggered by a message on a pub/sub topic. Then, you will create a job in the scheduling service that publishes a message to that same topic on a regular schedule, for example, every five minutes. This will, in turn, trigger your function to run. This practical exercise demonstrates how to build serverless, event-driven systems to perform scheduled tasks, such as generating nightly reports, performing regular data cleanup, or running periodic health checks, all without provisioning any virtual machines.
The Pillars of Observability: Monitoring
You cannot manage what you cannot measure. For a cloud architect, designing for observability is just as important as designing for performance or security. A hands-on lab that introduces the platform's native monitoring service is essential for learning this skill. Observability is often described as having three pillars: metrics, logs, and traces. This lab focuses on the first two. The exercise typically starts with creating a virtual machine and ensuring that the monitoring and logging agents are installed. These agents collect performance metrics and application logs from the instance. You will then learn how to explore these metrics in the monitoring interface, building charts and dashboards to visualize data like CPU utilization or disk I/O. A critical part of the lab is creating an alerting policy. You will configure a rule that sends you a notification if a specific metric, such as CPU usage, crosses a defined threshold for a certain period. This hands-on experience is vital for learning how to proactively monitor the health and performance of your cloud solutions and ensure their reliability.
Troubleshooting with Distributed Tracing
In a modern microservices architecture, a single user request might travel through dozens of different services before a response is generated. When performance problems arise, it can be incredibly difficult to pinpoint the bottleneck. This is where the third pillar of observability, distributed tracing, becomes invaluable. A hands-on lab on the platform's tracing service provides a practical introduction to this powerful troubleshooting technique. The lab typically involves deploying a simple, multi-component sample application that has already been instrumented for tracing. You will then run the application and explore the resulting traces in the service's user interface. A trace provides a detailed, end-to-end visualization of a request as it flows through the different services. You can see how long the request spent in each service and identify which component is causing the latency. This practical exercise demonstrates how a tracing system can dramatically reduce the time it takes to diagnose and resolve performance issues in complex, distributed systems, a critical skill for an architect responsible for ensuring the reliability of operations.
The Architect's Mindset: Beyond Individual Services
As you progress in your preparation for the Professional Cloud Architect exam, your focus must shift from understanding individual services to designing comprehensive solutions. The exam is not a trivia contest about product features; it is a test of your ability to synthesize your knowledge and apply it to solve complex business problems. This requires developing an architect's mindset. You must learn to think about the big picture, considering all the non-functional requirements such as security, reliability, cost-effectiveness, and operational excellence for any solution you design. The case studies are the most challenging part of the exam for this very reason. They present you with a detailed description of a fictional company, including its business goals, technical constraints, and existing infrastructure. You are then asked a series of questions that require you to make architectural decisions for that company. To answer these questions correctly, you must be able to analyze the business requirements, evaluate the trade-offs between different technical options, and justify your chosen design. This holistic approach is the essence of the cloud architect role.
Designing for Security and Compliance
Security is not a feature that can be added to a solution at the end; it must be designed in from the very beginning. The Professional Cloud Architect exam places a heavy emphasis on your ability to design for security and compliance. This goes beyond simply knowing about firewalls and encryption. It involves a deep understanding of concepts like the principle of least privilege, defense in depth, and the shared responsibility model. You must be able to design an identity and access management strategy, define organizational policies, and secure your network perimeter. Hands-on labs that cover firewalls, IAM, and secure data storage provide the foundational skills. However, an architect must also consider compliance. You need to be familiar with major regulatory frameworks like GDPR, HIPAA, and PCI DSS and understand how the cloud platform's services can be used to help meet these requirements. For the exam, you should be prepared to design a solution that not only meets the technical needs but also adheres to the strict security and compliance mandates of a regulated industry, such as healthcare or finance.
Analyzing and Optimizing Processes
A key domain of the exam focuses on analyzing and optimizing both business and technical processes. This reflects the reality that a cloud architect's job is not just about technology but also about improving how an organization operates. On the business side, this means understanding a company's financial and operational goals and designing cloud solutions that help achieve them. This could involve migrating a workload to the cloud to reduce capital expenditure or designing a data analytics pipeline to provide new business insights. On the technical side, this involves optimizing the software development lifecycle and operational procedures. An architect should be able to design a CI/CD pipeline for automated testing and deployment, implement an effective monitoring and alerting strategy, and design for business continuity and disaster recovery. The hands-on labs on automation, monitoring, and infrastructure as code provide the practical skills needed to implement these processes. For the exam, you need to be able to recommend process improvements that will make an organization more agile, efficient, and resilient.
Navigating Exam Prerequisites and Difficulty
The Professional Cloud Architect certification is not an entry-level credential. The official recommendation is that candidates should have at least three years of industry experience, including more than one year designing and managing solutions using the specific cloud platform. This experience is crucial because the exam tests your judgment and decision-making abilities, which are typically developed over time through real-world work. While it is possible to pass with less experience through intensive study, a solid foundation in IT and cloud concepts is highly recommended. The exam is widely considered to be challenging. Test-takers often report that the questions are ambiguous and that there are often multiple technically correct answers. The key is to select the "best" answer that most closely aligns with the platform's recommended practices and the business requirements stated in the question or case study. The difficulty lies not in the technical complexity of the services but in the nuance of applying them correctly in a given context. This is why hands-on experience and a deep understanding of the architectural principles are so critical for success.
The Value of Certification in the Job Market
Earning the Professional Cloud Architect certification is a significant value addition to your professional profile. As more companies migrate to the cloud and look to optimize their existing cloud deployments, the demand for skilled architects is incredibly high. This certification is a clear and verifiable signal to employers that you possess the skills and knowledge needed to design and manage enterprise-grade cloud solutions. It can open doors to new job opportunities, increase your earning potential, and provide a competitive edge in the crowded IT job market. Many organizations are actively restructuring their IT teams to embrace cloud-native technologies and a DevOps culture. Certified architects are in a prime position to lead these transformation initiatives. The certification demonstrates not only your technical expertise but also your commitment to continuous learning and professional development. Whether you are looking to advance within your current organization or seek new opportunities elsewhere, this credential can be a powerful catalyst for your career growth in the dynamic and expanding field of cloud computing.
Professional Cloud Architect certification practice test questions and answers, training course, study guide are uploaded in ETE files format by real users. Study and pass Google Professional Cloud Architect certification exam dumps & practice test questions and answers are the best available resource to help students pass at the first attempt.



