Pass Microsoft Certified: Azure Data Engineer Associate Certification Exam in First Attempt Guaranteed!
Get 100% Latest Exam Questions, Accurate & Verified Answers to Pass the Actual Exam!
30 Days Free Updates, Instant Download!


DP-203 Premium Bundle
- Premium File 397 Questions & Answers. Last update: May 14, 2026
- Training Course 262 Video Lectures
- Study Guide 1325 Pages
DP-203 Premium Bundle
- Premium File 397 Questions & Answers
Last update: May 14, 2026 - Training Course 262 Video Lectures
- Study Guide 1325 Pages
Purchase Individually

Premium File

Training Course

Study Guide








DP-203 Exam - Data Engineering on Microsoft Azure
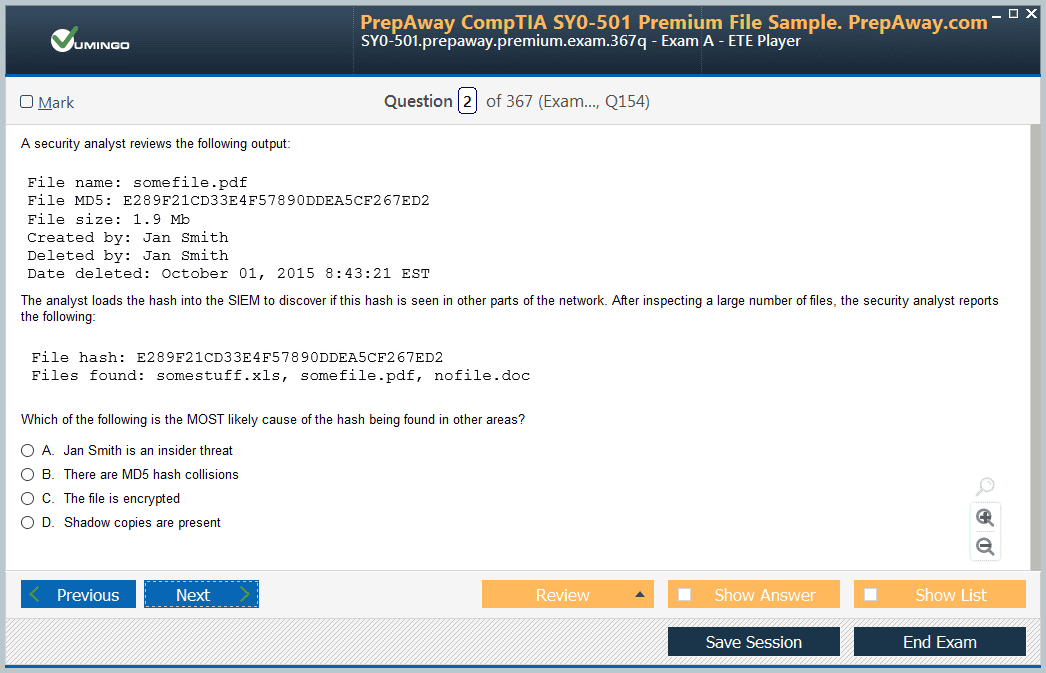
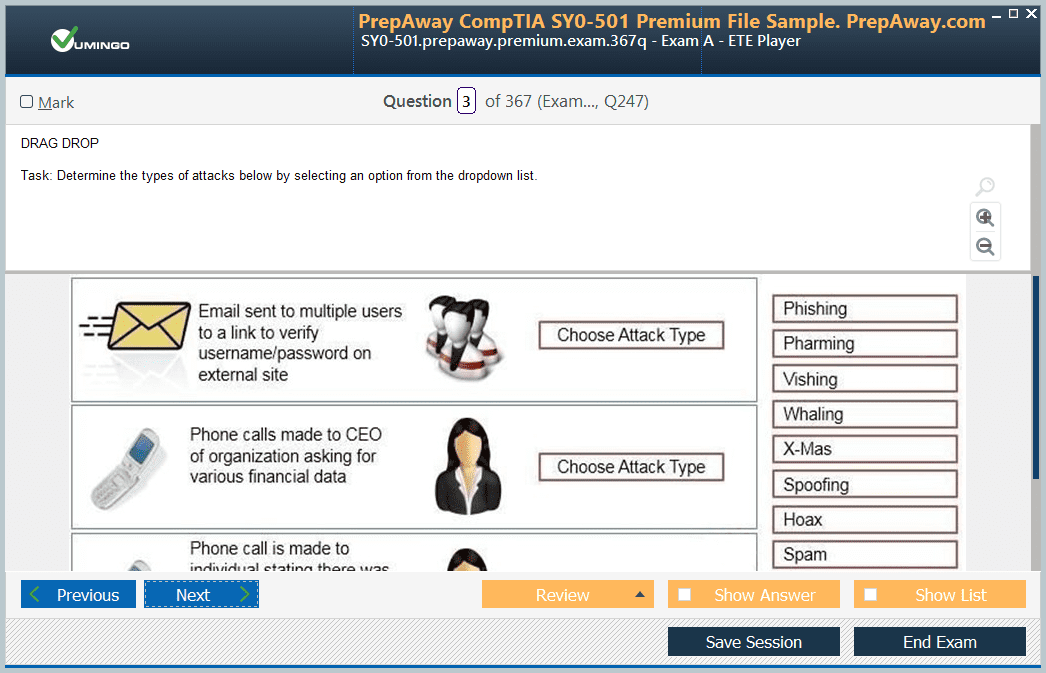
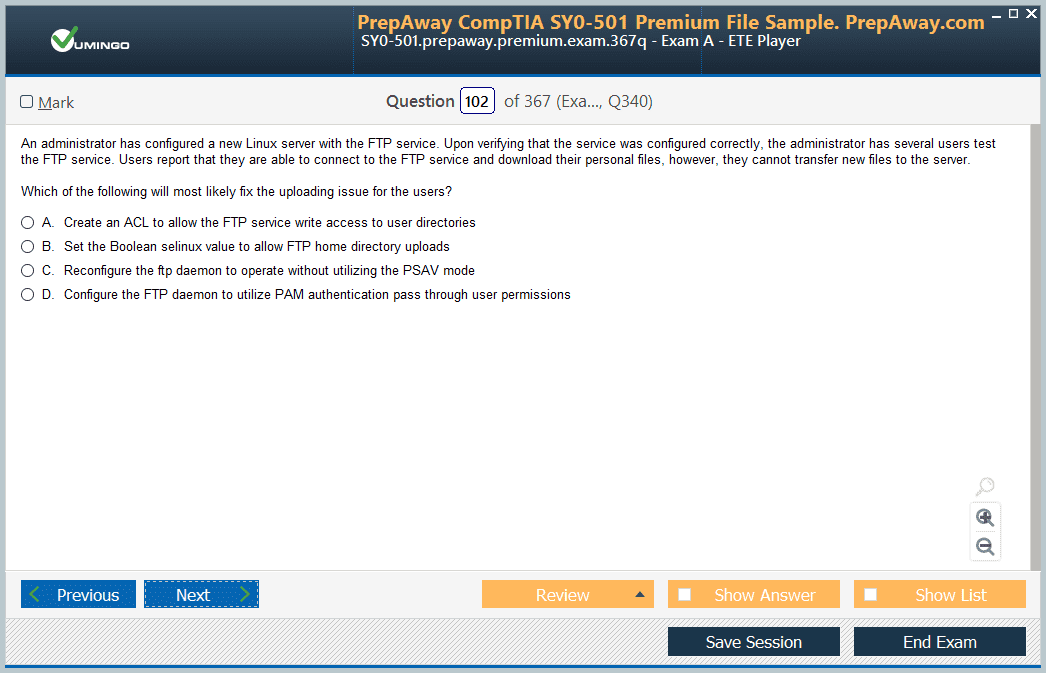
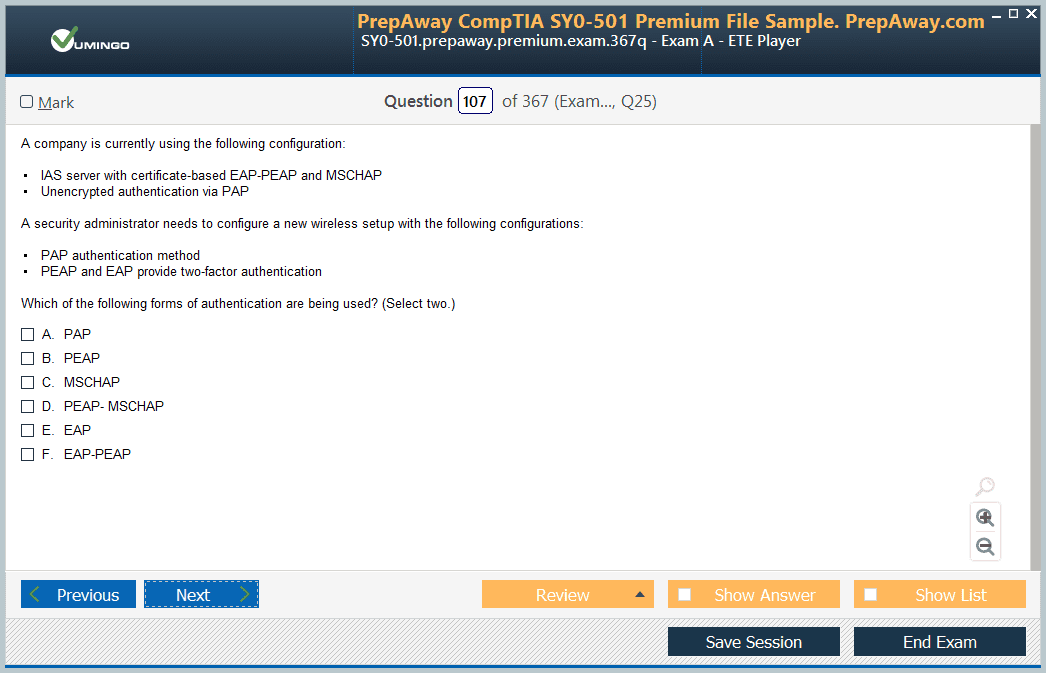
| Download Free DP-203 Exam Questions |
|---|
Microsoft Microsoft Certified: Azure Data Engineer Associate Certification Practice Test Questions and Answers, Microsoft Microsoft Certified: Azure Data Engineer Associate Certification Exam Dumps
All Microsoft Microsoft Certified: Azure Data Engineer Associate certification exam dumps, study guide, training courses are prepared by industry experts. Microsoft Microsoft Certified: Azure Data Engineer Associate certification practice test questions and answers, exam dumps, study guide and training courses help candidates to study and pass hassle-free!
The Foundation of Modern Data: Your Journey to Becoming a Microsoft Certified: Azure Data Engineer Associate
In today's digital landscape, data is the most valuable currency. Businesses across every sector, from retail and finance to healthcare and manufacturing, are leveraging vast amounts of information to make smarter decisions, understand customer behavior, and innovate their products and services. This explosion of data has created an unprecedented demand for professionals who can manage, process, and make sense of it all. While data scientists often capture the spotlight for their work in analytics and machine learning, their efforts would be impossible without the foundational work laid by another critical professional: the data engineer.
A data engineer is the architect of the data world. They are responsible for building and maintaining the infrastructure that collects, stores, and transports data. Think of them as the civil engineers of the digital age, constructing the robust data pipelines, reservoirs, and highways that allow information to flow smoothly and reliably to its destination. Without these systems, the raw data generated by applications, user interactions, and IoT devices would remain a chaotic and unusable flood. The role of a Microsoft Certified: Azure Data Engineer Associate is to perform this vital function within the powerful and scalable Microsoft Azure cloud ecosystem.
Why Choose a Career as an Azure Data Engineer?
Pursuing a career in data engineering, specifically on the Azure platform, offers a compelling combination of professional opportunity, technical challenge, and long-term stability. The demand for skilled data engineers consistently outpaces supply, leading to competitive salaries and excellent job security. This role is not just a job; it is a pathway into the heart of modern technology, where you will work with cutting-edge tools and solve complex problems that have a direct impact on business success. It is a dynamic field where continuous learning is not just encouraged but required, ensuring that your skills remain relevant and valuable.
The role of a data engineer is also deeply satisfying because it is foundational. You are the enabler, the one who prepares the clean, organized, and accessible data that empowers data scientists to uncover insights, data analysts to build reports, and machine learning models to learn. You get to see the tangible results of your work as the systems you build become the backbone of your organization's data strategy. Choosing Azure as your platform further enhances these prospects, as it is one of the leading cloud providers globally, trusted by a vast majority of Fortune 500 companies.
Distinguishing Data Roles: Engineer vs. Scientist vs. Analyst
To fully appreciate the path to becoming a Microsoft Certified: Azure Data Engineer Associate, it is crucial to understand how this role fits within the broader data ecosystem. While often grouped together, the roles of a data engineer, data scientist, and data analyst are distinct, with unique responsibilities and skill sets. A data analyst primarily focuses on examining existing data sets to identify trends, create visualizations, and generate reports that answer specific business questions. They work with clean data to extract historical insights. Their primary goal is to interpret the past and present state of the business through data.
A data scientist, on the other hand, often works with a predictive or prescriptive focus. They use advanced statistical methods, machine learning algorithms, and programming to build models that can forecast future outcomes or suggest optimal actions. Their work is exploratory and often involves complex modeling. The data engineer, however, precedes both of these roles. The engineer is responsible for the entire data lifecycle before it reaches the analysts and scientists. They design, build, and manage the systems for data ingestion, storage, transformation, and processing, ensuring the data is reliable, secure, and ready for consumption.
The Azure Advantage in Data Engineering
Microsoft Azure provides a comprehensive and integrated suite of services specifically designed for data workloads, making it an ideal environment for data engineers. The platform offers a powerful combination of tools that cover every aspect of the data lifecycle. For storage, services like Azure Data Lake Storage provide a highly scalable and secure repository for massive amounts of structured and unstructured data. For data processing and transformation, tools like Azure Data Factory and Azure Synapse Analytics allow engineers to build sophisticated data pipelines and perform large-scale analytics with incredible efficiency and power.
Furthermore, Azure Databricks offers a collaborative Apache Spark-based analytics platform, which is a favorite among data engineers for big data processing and machine learning tasks. The platform's ability to seamlessly integrate these services allows engineers to construct end-to-end data solutions that are robust, scalable, and secure. Earning the Microsoft Certified: Azure Data Engineer Associate certification validates your ability to skillfully wield these tools, signaling to employers that you have the expertise to build enterprise-grade data solutions on one of the world's leading cloud platforms. This makes Azure not just a platform, but a career accelerator.
A Glimpse into the Daily Life of an Azure Data Engineer
The day-to-day responsibilities of an Azure Data Engineer are varied and challenging. A typical day might begin with monitoring the health and performance of existing data pipelines, ensuring that data is flowing correctly from source systems into the data lake or data warehouse. This involves checking for errors, diagnosing bottlenecks, and optimizing processes for speed and cost-efficiency. You might spend a significant portion of your day designing and developing new data pipelines using Azure Data Factory to onboard a new data source, which could involve collaborating with business stakeholders to understand their data requirements.
Another key activity is data modeling and schema design. As data is ingested, it often needs to be cleaned, transformed, and structured in a way that is optimal for analysis. This could involve writing SQL queries in Azure Synapse Analytics or developing data transformation logic in Python or Scala within an Azure Databricks notebook. Security and compliance are also paramount, so you will be responsible for implementing security controls, managing access, and ensuring that data handling practices comply with regulations. It is a role that blends software engineering, database management, and systems architecture.
Core Responsibilities of the Role
At its core, the job of an Azure Data Engineer revolves around several key responsibilities that form the foundation of an organization's data platform. The primary responsibility is designing and implementing data storage solutions. This involves selecting the appropriate Azure service, such as Azure Blob Storage, Azure Data Lake Storage, or Azure Cosmos DB, based on the data's structure, volume, and access patterns. They are then tasked with configuring these storage solutions for optimal performance, security, and cost-effectiveness, ensuring the data is both safe and accessible for downstream use.
Another fundamental duty is the management and development of data processing. This is the heart of data engineering, where raw data is transformed into valuable information. Engineers build and maintain data pipelines to extract, transform, and load (ETL) or extract, load, and transform (ELT) data. They use services like Azure Data Factory, Azure Databricks, and Azure Stream Analytics to handle both batch and real-time data streams. This work requires strong programming and scripting skills to implement the complex business logic required for data cleansing, aggregation, and enrichment, making it ready for analysis.
Finally, a Microsoft Certified: Azure Data Engineer Associate is responsible for monitoring, optimizing, and securing the data solutions they build. This involves implementing robust logging and monitoring to track the health and performance of data pipelines and storage systems. They analyze performance metrics to identify and resolve bottlenecks, ensuring the system operates efficiently. They are also the guardians of the data, implementing security measures such as encryption, access control, and network security to protect sensitive information from unauthorized access and ensure compliance with industry standards and data privacy regulations.
The Growing Demand and Career Outlook
The career outlook for Azure Data Engineers is exceptionally bright. As organizations continue to migrate their data infrastructure to the cloud and expand their data-driven initiatives, the need for professionals who can build and manage these systems is skyrocketing. The skills required for this role are specialized and in high demand, which translates into a strong job market for qualified individuals. Companies are actively seeking candidates who not only understand data principles but can also implement them using the powerful tools available in the Azure cloud. This demand spans across all industries, from tech startups to established multinational corporations.
Becoming a Microsoft Certified: Azure Data Engineer Associate provides a clear and verifiable credential that demonstrates your expertise in this high-demand area. This certification can significantly enhance your resume, open doors to new job opportunities, and increase your earning potential. The career path for a data engineer is also rich with possibilities for growth. With experience, you can advance to senior or lead data engineer roles, specialize in areas like big data or stream processing, or transition into related fields such as data architecture, machine learning engineering, or even data management leadership positions within an organization.
Building Your Foundational Knowledge
Before diving into the specifics of Azure services, it is essential to build a solid foundation in the core concepts that underpin all data engineering work. A strong understanding of database technologies is non-negotiable. This includes proficiency in SQL for querying and manipulating data in relational databases, as well as an understanding of NoSQL database concepts for handling unstructured data. You should be familiar with data modeling techniques, such as normalization and dimensional modeling, which are crucial for designing efficient and scalable data warehouses. This knowledge forms the bedrock upon which you will build your Azure-specific skills.
In addition to database skills, a fundamental grasp of programming is essential. Languages like Python and Scala are staples in the data engineering world, used extensively for scripting data transformations, automating tasks, and working with big data frameworks like Apache Spark. Understanding basic software engineering principles, such as version control with Git, is also important for collaborating effectively in a team environment. Finally, having a conceptual understanding of distributed systems and how they enable the processing of large datasets across multiple machines will provide the context needed to master cloud-based data platforms like Microsoft Azure.
The First Step on Your Certification Path
Your journey to becoming a Microsoft Certified: Azure Data Engineer Associate officially begins with a commitment to learning and a structured approach to skill development. This five-part guide will walk you through every stage of the process, from understanding the foundational skills required, to deep-diving into the core Azure data services you will use every day. We will explore the specific objectives of the certification exam, providing you with a clear roadmap for your studies. Finally, we will look at what comes after certification, including career opportunities and future trends in the field.
Embarking on this path is an investment in a future-proof career at the intersection of data and cloud computing. The skills you will acquire are not just theoretical; they are practical, in-demand abilities that solve real-world business problems. By the end of this series, you will have a comprehensive understanding of what it takes to succeed as an Azure Data Engineer and a clear plan to achieve the prestigious Microsoft Certified: Azure Data Engineer Associate certification. The journey requires dedication, but the rewards in terms of career growth and professional fulfillment are immense.
Mastering the Language of Data: SQL
For any aspiring data engineer, Structured Query Language (SQL) is not just a skill; it is the fundamental language of data manipulation. It is the primary tool used to interact with relational databases, which remain a cornerstone of data storage in most organizations. A deep proficiency in SQL is absolutely essential for a Microsoft Certified: Azure Data Engineer Associate. You will use it daily to query data, filter for specific records, join data from multiple tables, and perform aggregations to create summary datasets. This is a critical part of the data exploration and transformation process.
Your SQL knowledge must extend beyond basic SELECT statements. You need to be comfortable with advanced concepts such as subqueries, common table expressions (CTEs), and window functions, which are vital for performing complex analytical queries. Furthermore, you must understand Data Definition Language (DDL) for creating and modifying database structures like tables and indexes, and Data Control Language (DCL) for managing permissions and security. In the Azure ecosystem, you will apply these SQL skills extensively within services like Azure SQL Database and, most importantly, Azure Synapse Analytics to query and manage massive datasets in a data warehouse environment.
The Power of Programming: Python and Scala
While SQL is crucial for interacting with structured data stores, much of a data engineer's work involves tasks that require the flexibility and power of a general-purpose programming language. Python has emerged as the de facto language for data engineering due to its simple syntax, extensive libraries, and strong community support. You will use Python to write scripts for automating data ingestion, cleaning complex unstructured data, and implementing custom transformation logic that goes beyond what is possible with SQL alone. Libraries such as Pandas are indispensable for data manipulation, while others are used for connecting to various data sources.
Another powerful language in the big data space is Scala. Because it runs on the Java Virtual Machine (JVM), Scala offers excellent performance, which is a major advantage when processing very large datasets. It is the native language of Apache Spark, a leading distributed computing framework that is at the heart of Azure Databricks. While Python is often easier for beginners, learning Scala can provide a performance edge and a deeper understanding of Spark's inner workings. A Microsoft Certified: Azure Data Engineer Associate should aim for proficiency in at least one of these languages, with a strong preference for Python due to its ubiquity.
Understanding Data Structures and Algorithms
While you may not be developing complex software from scratch, a solid understanding of fundamental data structures and algorithms is a key differentiator for an effective data engineer. Knowing how different data structures, such as arrays, linked lists, hash maps, and trees, work under the hood allows you to make informed decisions about how to store and process data efficiently. For example, understanding the performance characteristics of a hash map can help you optimize a data transformation job that involves frequent lookups, significantly reducing processing time and cost. This knowledge is invaluable for writing efficient code.
Similarly, familiarity with common algorithms, particularly those related to sorting and searching, is beneficial. When you are working with datasets containing billions of records, the efficiency of your algorithms can be the difference between a pipeline that runs in minutes versus one that runs for hours. This theoretical computer science knowledge allows you to think critically about performance and scalability. It empowers you to move beyond simply using a tool to understanding how to use it in the most optimal way possible, a hallmark of a senior-level data engineer and a valuable skill for a Microsoft Certified: Azure Data Engineer Associate.
On-Premises vs. Cloud Data Solutions
A crucial conceptual skill for an Azure Data Engineer is a clear understanding of the differences between traditional on-premises data solutions and modern cloud-based solutions. On-premises environments involve managing physical servers, storage hardware, and networking infrastructure within an organization's own data center. This model requires significant upfront capital investment, ongoing maintenance, and a dedicated IT staff to manage the hardware. Scaling an on-premises system can be slow and expensive, as it requires purchasing and provisioning new physical servers. This context is important because many data engineering projects involve migrating data from these legacy systems to the cloud.
In contrast, cloud data solutions, like those offered by Microsoft Azure, operate on a pay-as-you-go model, eliminating the need for large capital expenditures. The cloud provider manages all the underlying infrastructure, allowing data engineers to focus on building data solutions rather than managing hardware. The key advantage of the cloud is its elasticity and scalability. You can provision vast computing and storage resources in minutes and scale them up or down based on demand. A Microsoft Certified: Azure Data Engineer Associate must be able to articulate these benefits and design solutions that leverage the unique capabilities of the cloud.
The Core of Big Data: Distributed Systems
Modern data engineering is synonymous with big data, and the ability to process big data relies on the principles of distributed systems. A distributed system is a collection of independent computers that work together and appear to the user as a single, coherent system. Instead of processing a massive dataset on a single, powerful machine, the data and the workload are distributed across a cluster of many smaller machines. This approach provides massive scalability and fault tolerance. If one machine in the cluster fails, the system can continue to operate by redistributing the work among the remaining machines.
Frameworks like Apache Hadoop and Apache Spark are built on this principle. As an aspiring Microsoft Certified: Azure Data Engineer Associate, you need to grasp this concept fundamentally. You do not need to be an expert in building distributed systems from scratch, but you must understand how they work. This knowledge is essential for using services like Azure HDInsight and Azure Databricks effectively. Understanding concepts like data partitioning, parallel processing, and fault tolerance will enable you to design and troubleshoot large-scale data processing jobs efficiently within the Azure environment.
Architecting Data Flow: Understanding Data Pipelines
The concept of a data pipeline is central to the role of a data engineer. A data pipeline is a series of data processing steps that move data from a source system to a destination, often transforming it along the way. The goal is to automate this entire process, ensuring that data is delivered reliably and efficiently. Designing and implementing these pipelines is a primary responsibility of a Microsoft Certified: Azure Data Engineer Associate. A typical pipeline might start by ingesting raw data from a transactional database, a set of log files, or a streaming API.
Once ingested, the data moves through several stages of transformation. This could involve cleansing the data to remove errors and inconsistencies, enriching it by joining it with other datasets, and aggregating it into a more useful format. Finally, the processed data is loaded into a destination system, such as an Azure Synapse Analytics data warehouse or a data lake, where it can be used for analytics and reporting. Understanding how to design these pipelines for reliability, scalability, and maintainability using tools like Azure Data Factory is a critical skill that you will be tested on.
Data Warehousing and Data Modeling
A core component of many enterprise data solutions is the data warehouse, a centralized repository of integrated data from one or more disparate sources. Data warehouses are designed to support business intelligence activities and analytics. As an Azure Data Engineer, you will be responsible for designing and implementing these systems using services like Azure Synapse Analytics. This requires a strong understanding of data warehousing concepts, including the difference between online transaction processing (OLTP) systems, which are optimized for fast transactions, and online analytical processing (OLAP) systems, which are optimized for complex queries.
A key skill related to data warehousing is data modeling, specifically dimensional modeling. This technique, which involves organizing data into "fact" and "dimension" tables, is the industry standard for designing data warehouses that are easy to understand and fast to query. You will need to be familiar with concepts like star schemas and snowflake schemas. The ability to translate business requirements into an effective dimensional model is a hallmark of a skilled data engineer and a crucial competency for anyone pursuing the Microsoft Certified: Azure Data Engineer Associate certification.
Exploring the Data Lake Concept
While data warehouses are ideal for structured data, organizations today also need to store and analyze vast quantities of semi-structured and unstructured data, such as text, images, and sensor data. This is where the concept of a data lake comes in. A data lake is a centralized storage repository that allows you to store all your structured and unstructured data at any scale. Unlike a data warehouse, a data lake stores data in its raw, native format, without requiring you to first structure it. This approach is known as "schema-on-read" and provides greater flexibility.
In the Azure ecosystem, the primary service for implementing a data lake is Azure Data Lake Storage (ADLS). It is a highly scalable and secure storage service built on top of Azure Blob Storage. As an Azure Data Engineer, you will be responsible for designing and managing the data lake, including its folder structure, security, and data lifecycle management policies. You will build pipelines to ingest data into the data lake and then use services like Azure Databricks or Azure Synapse Analytics to process and analyze that data directly within the lake.
Batch vs. Stream Processing
Data processing can be broadly categorized into two paradigms: batch processing and stream processing. Batch processing involves processing large volumes of data at regular intervals. For example, a pipeline might run every night to process all the sales transactions from that day, calculate daily summaries, and load them into the data warehouse. This approach is efficient for workloads that can tolerate some latency and where data is collected over a period of time. Azure services like Azure Data Factory and Azure Synapse Analytics are well-suited for batch processing workloads.
Stream processing, on the other hand, involves processing data in real-time as it is generated. This is essential for use cases that require immediate insights or actions, such as fraud detection, real-time monitoring of IoT devices, or dynamic pricing. Data is processed as a continuous stream of small events rather than in large batches. As an aspiring Microsoft Certified: Azure Data Engineer Associate, you must understand the concepts of stream processing and be familiar with Azure services designed for this purpose, such as Azure Stream Analytics and the structured streaming capabilities within Azure Databricks.
Putting It All Together: The Modern Data Platform
The skills and concepts discussed in this part are not isolated; they come together to form a modern data platform. An Azure Data Engineer is the architect and builder of this platform. The platform typically begins with data ingestion, where batch and streaming pipelines bring data from various sources into a central data lake built on Azure Data Lake Storage. This raw data is then processed and refined using tools like Azure Databracks or Azure Synapse Analytics. The transformation process cleanses, standardizes, and structures the data, preparing it for analysis and creating curated datasets.
These curated datasets can then be served to end-users through various means. Some data might be loaded into a highly structured data warehouse in Azure Synapse Analytics to power business intelligence dashboards and reports. Other data might be used to train machine learning models or be exposed through APIs for consumption by other applications. The role of the Microsoft Certified: Azure Data Engineer Associate is to design, build, and orchestrate this entire end-to-end system, ensuring that it is secure, scalable, reliable, and capable of meeting the diverse data needs of the organization.
The Foundation: Azure Data Lake Storage
At the heart of any modern data platform on Azure lies Azure Data Lake Storage (ADLS) Gen2. This service is the foundational storage layer where you will house all of your organization's data, both structured and unstructured, at massive scale. ADLS Gen2 is not just a file system; it is a highly optimized storage solution built specifically for big data analytics workloads. It combines the scalability and low cost of Azure Blob Storage with features like a hierarchical namespace, which allows you to organize data in a familiar directory structure, making it much easier to manage and secure.
As a future Microsoft Certified: Azure Data Engineer Associate, you must have a deep understanding of ADLS Gen2. This includes knowing how to provision a storage account with the hierarchical namespace enabled, how to design an effective folder structure for organizing raw and processed data, and how to ingest data into the lake. Critically, you must master its security model, which involves a combination of role-based access control (RBAC) for broad permissions and access control lists (ACLs) for fine-grained, file-level security. This ensures that data is both accessible to authorized users and protected from unauthorized access.
The Orchestrator: Azure Data Factory
Once you have your data lake in place, you need a way to populate it with data and orchestrate the transformation processes. This is the primary role of Azure Data Factory (ADF), a fully managed, cloud-based data integration service. ADF allows you to visually create, schedule, and manage data pipelines, which are known as ETL (extract, transform, load) and ELT (extract, load, transform) workflows. It provides a rich set of connectors to a vast array of data sources, both in the cloud and on-premises, making it easy to ingest data from anywhere.
For a Microsoft Certified: Azure Data Engineer Associate, mastering Azure Data Factory is non-negotiable. You will use its drag-and-drop interface to build complex control flows, defining the sequence of activities in your pipeline. A key feature is the Mapping Data Flow, which provides a code-free way to design graphical data transformation logic that runs on a scaled-out Apache Spark cluster managed by the service. You will also learn to parameterize your pipelines for reusability and schedule them to run based on a specific time or in response to an event, automating your entire data workflow.
The Unified Analytics Powerhouse: Azure Synapse Analytics
Azure Synapse Analytics is Microsoft's flagship service for enterprise analytics, and it is a central component of the Azure data engineering toolset. It is a limitless analytics service that brings together enterprise data warehousing and big data analytics into a single, unified experience. It allows you to query data on your terms, using either serverless on-demand resources for data exploration or provisioned resources for more predictable data warehousing workloads. This integration simplifies the data landscape and reduces the time it takes to get from raw data to actionable insights.
As an aspiring Microsoft Certified: Azure Data Engineer Associate, you must become proficient in the various components of Synapse. This includes understanding how to use dedicated SQL pools (formerly SQL Data Warehouse) for high-performance, petabyte-scale data warehousing, employing best practices for data distribution and indexing. You will also need to master the use of serverless SQL pools to directly query data stored in your data lake using familiar T-SQL syntax. Furthermore, Synapse integrates Apache Spark pools, allowing you to perform code-first big data processing using languages like Python, Scala, and .NET right within the same Synapse workspace.
The Big Data Engine: Azure Databricks
While Azure Synapse Analytics provides an integrated Spark experience, many organizations still rely on Azure Databricks for their most demanding big data and machine learning workloads. Azure Databricks is a first-party Microsoft service that offers a highly optimized and collaborative Apache Spark-based analytics platform. It is renowned for its high performance, ease of use, and collaborative features, such as interactive notebooks that allow data engineers, data scientists, and business analysts to work together in a shared environment. It provides a powerful engine for large-scale data transformation and preparation.
A Microsoft Certified: Azure Data Engineer Associate needs to be comfortable working within the Azure Databricks environment. This involves knowing how to create and manage Spark clusters, how to use notebooks for developing and executing data processing code in Python, Scala, or SQL, and how to read data from and write data to Azure Data Lake Storage. You should understand how to optimize Spark jobs for performance and cost, and how Databricks integrates with other Azure services like Azure Data Factory, which can be used to schedule and orchestrate the execution of your Databricks notebooks as part of a larger data pipeline.
Real-Time Insights: Azure Stream Analytics
Not all data can wait for batch processing. For use cases that require immediate analysis, such as monitoring IoT sensor data, analyzing clickstream data from a website, or detecting fraudulent transactions, you need a real-time stream processing engine. In Azure, the primary service for this is Azure Stream Analytics. It is a fully managed, serverless service that allows you to define a continuous query that runs against a stream of data from sources like Azure Event Hubs or Azure IoT Hub. This allows you to process data with extremely low latency.
Understanding the principles of stream processing is a key competency for a Microsoft Certified: Azure Data Engineer Associate. You will need to learn how to create a Stream Analytics job, define inputs and outputs, and write the query logic using a simple, SQL-like query language. A critical concept in stream processing is windowing, which allows you to perform aggregations over specific time intervals (e.g., counting the number of events every 5 seconds). You must understand different windowing functions like tumbling, hopping, and sliding windows to correctly implement your real-time analytics logic.
Flexible NoSQL Data: Azure Cosmos DB
While much of a data engineer's work involves relational data, modern applications often generate semi-structured or NoSQL data that does not fit neatly into the rows and columns of a traditional database. For these scenarios, Azure offers Azure Cosmos DB, a globally distributed, multi-model database service. It provides turnkey global distribution, elastic scaling of throughput and storage, and guarantees single-digit-millisecond latencies at the 99th percentile. It supports multiple data models, including document, key-value, column-family, and graph databases, through a variety of popular APIs.
As an Azure Data Engineer, you will encounter scenarios where you need to ingest data from or load data into Azure Cosmos DB. You should understand the fundamental concepts of Cosmos DB, such as its resource model (accounts, databases, containers) and its use of request units (RUs) for managing throughput. While you may not be a database administrator for Cosmos DB, you need to know how to connect to it from services like Azure Data Factory or Azure Databricks to read or write data as part of your data pipelines. This knowledge is crucial for building end-to-end solutions that incorporate operational application data.
Data Governance and Cataloging: Microsoft Purview
As data platforms grow in size and complexity, it becomes increasingly difficult to understand what data is available, where it came from, and whether it can be trusted. This is where data governance and cataloging come into play. Microsoft Purview is a unified data governance service that helps you manage and govern your on-premises, multicloud, and software-as-a-service (SaaS) data. It allows you to create a holistic, up-to-date map of your data landscape with automated data discovery, sensitive data classification, and end-to-end data lineage. This service provides a business glossary to define common terms.
While data governance can be a specialized role, a Microsoft Certified: Azure Data Engineer Associate should be familiar with the role Purview plays in the data ecosystem. You should understand how to scan data sources like Azure Data Lake Storage and Azure Synapse Analytics to automatically populate the data catalog. You should also appreciate the importance of data lineage, which Purview can visualize, showing how data moves and transforms through your pipelines. This visibility is critical for impact analysis, troubleshooting, and ensuring data quality and compliance across your entire data estate.
Securing Your Data Platform
Security is not an afterthought; it is a critical component that must be designed into every data solution from the beginning. The Azure platform provides a wide range of security services and features to help you protect your data. As an Azure Data Engineer, you are responsible for implementing these controls across your data platform. This starts with identity and access management, using Azure Active Directory to authenticate users and services, and implementing the principle of least privilege through role-based access control (RBAC). This ensures that users and applications only have access to the data they absolutely need.
Your security responsibilities also extend to data protection. This includes encrypting data both at rest (while it is stored in services like ADLS Gen2) and in transit (as it moves between services). You will also need to secure your network environment, using features like virtual networks and private endpoints to isolate your data services from the public internet. Furthermore, monitoring and threat detection are key. You should be familiar with Azure Monitor and Microsoft Defender for Cloud to track access, detect suspicious activities, and respond to potential security threats in your data environment.
Monitoring and Optimization
Building a data pipeline is only half the battle; ensuring it runs reliably, efficiently, and cost-effectively is an ongoing responsibility. Azure provides a comprehensive suite of monitoring tools, with Azure Monitor being the central service for collecting, analyzing, and acting on telemetry from your cloud environment. As a Microsoft Certified: Azure Data Engineer Associate, you must know how to use Azure Monitor to track the performance and health of your Azure Data Factory pipelines, Synapse Analytics jobs, and Databricks clusters. You can create alerts to be notified proactively when issues arise.
Optimization is the next step after monitoring. By analyzing the performance metrics you collect, you can identify bottlenecks and inefficiencies in your data solutions. This could involve rewriting a slow-running SQL query in Synapse, repartitioning your data in a Spark job to improve parallelism, or scaling up the resources for a data factory integration runtime during peak load. Cost optimization is also a major factor. You will need to understand the pricing models for each Azure service and make design choices that deliver the required performance at the lowest possible cost.
Integrating Services for End-to-End Solutions
The true power of the Azure platform comes from the seamless integration between its various data services. A Microsoft Certified: Azure Data Engineer Associate must be an expert at combining these services to build cohesive, end-to-end data solutions. A typical workflow might involve using Azure Data Factory to ingest raw log files from an on-premises server into Azure Data Lake Storage. This event could then trigger an Azure Databricks job that cleanses and transforms the raw data, enriching it with customer information from Azure SQL Database.
The processed data could then be loaded into a dedicated SQL pool in Azure Synapse Analytics for dashboarding and reporting by business analysts. Simultaneously, another part of the pipeline could feed a subset of this data into Azure Cosmos DB to serve a real-time customer-facing application. Throughout this entire process, Microsoft Purview would scan and catalog the data assets, and Azure Monitor would track the health and performance of every component. Your role is to be the master architect, selecting the right tool for each job and weaving them together into a powerful and reliable data platform.
Understanding the DP-203 Exam
The single exam required to earn the Microsoft Certified: Azure Data Engineer Associate certification is the Exam DP-203: Data Engineering on Microsoft Azure. This exam is the definitive test of your ability to design and implement data solutions using core Azure data services. It replaces the older two-exam path (DP-200 and DP-201), combining both implementation and design concepts into one comprehensive assessment. The exam is designed for data engineers who have a solid understanding of data processing languages like SQL, Python, or Scala, and hands-on experience building data solutions on Azure.
Passing the DP-203 exam signifies to the industry that you possess the necessary skills to handle the entire lifecycle of data engineering on Azure. This includes designing and implementing data storage, developing data processing solutions, ensuring data security and compliance, and optimizing and monitoring data platforms. The exam is not just a test of theoretical knowledge; it includes question types like case studies and hands-on labs that require you to apply your skills to solve real-world problems. A thorough and practical preparation strategy is therefore essential for success.
Exam Objective 1: Design and Implement Data Storage
This is the largest and most foundational domain of the DP-203 exam, typically accounting for 40-45% of the questions. This section tests your ability to choose the right Azure storage solution for a given scenario and implement it effectively. You will be expected to have a deep knowledge of Azure Data Lake Storage Gen2, including how to design its structure, implement partitioning strategies, and manage its lifecycle. You must also master its security model, using a combination of RBAC and ACLs to enforce fine-grained permissions.
This domain also covers other storage solutions. You will need to understand the use cases for Azure Blob Storage and the differences between its access tiers (Hot, Cool, Archive). Knowledge of Azure Synapse Analytics is critical, specifically how to design a physical data warehouse structure, including the selection of appropriate table distribution types (hash, round-robin, replicated) and indexing strategies. You will also be tested on your ability to work with Azure Cosmos DB, understanding its different APIs and consistency levels, and knowing when to use it over other relational or non-relational storage options.
Exam Objective 2: Design and Develop Data Processing
The second major domain focuses on the heart of data engineering: processing and transforming data. This section, which makes up 25-30% of the exam, evaluates your skills in using Azure's primary data processing services. A significant portion will be dedicated to Azure Data Factory. You must be able to design and build pipelines, use the Mapping Data Flow feature for code-free transformations, and manage the Integration Runtimes that provide the compute for your pipeline activities. This includes knowing how to orchestrate the execution of other services like Azure Databricks or Synapse notebooks.
Your expertise with Azure Synapse Analytics will also be heavily tested here. You need to demonstrate your ability to ingest and transform data using T-SQL in both serverless and dedicated SQL pools, and you should be proficient with PolyBase and the COPY command for loading data. Furthermore, your skills with Apache Spark in either Azure Synapse Analytics or Azure Databricks are crucial. You must be able to write Spark code (in Python or Scala) to transform dataframes, handle semi-structured data like JSON, and work with Spark's Structured Streaming capabilities for real-time data processing.
Exam Objective 3: Design and Implement Data Security
Security is a paramount concern in any data platform, and this domain, comprising 10-15% of the exam, ensures you have the necessary skills to protect your data. The questions will focus on designing and implementing a layered security strategy for your entire data estate. This begins with securing the data stores themselves. You will need to know how to implement transparent data encryption (TDE) for databases and enable encryption for data at rest in Azure Data Lake Storage. You must also be able to implement column-level security and row-level security in Azure Synapse Analytics to restrict access to sensitive data.
This section also covers network security and access management. You should understand how to use virtual networks, network security groups, and private endpoints to isolate your data services and prevent public access. A key topic is managing authentication and authorization. You will be expected to know how to use Azure Active Directory identities, including managed identities for Azure resources, to provide secure, password-less access between services. You should also be familiar with Azure Key Vault for securely storing and managing secrets, keys, and certificates used by your data pipelines.
Exam Objective 4: Monitor and Optimize Data Solutions
The final domain, accounting for 10-15% of the exam, covers the operational aspects of managing a data platform. A Microsoft Certified: Azure Data Engineer Associate must be able to ensure that their solutions are reliable, performant, and cost-effective. This section tests your ability to use Azure Monitor to collect logs and metrics from your data services. You must know how to analyze this telemetry to troubleshoot pipeline failures, diagnose performance bottlenecks, and set up alerts for proactive notification of issues. This includes monitoring query performance in Azure Synapse Analytics and optimizing slow-running queries.
Optimization is a key theme of this domain. You will be tested on your ability to optimize data storage, such as implementing data partitioning in a data lake or choosing the correct indexing strategy in a data warehouse. You will also need to know how to optimize data processing jobs in Spark, for example, by caching data or managing data skew. The exam will expect you to understand how to handle data recovery and ensure high availability for your data solutions, including knowledge of disaster recovery strategies for services like Azure SQL Database and Synapse Analytics.
Effective Study Strategies
To succeed on the DP-203 exam, you need a multi-faceted study approach that combines theoretical learning with hands-on practice. Start with the official Microsoft Learn path for DP-203. This free, self-paced learning resource is structured around the exam objectives and provides detailed explanations, examples, and short knowledge-check quizzes. It is the best starting point to get a comprehensive overview of all the topics covered on the exam. Reading the official Microsoft documentation for each of the core services is also highly recommended for gaining a deeper understanding of their features and configurations.
Next, supplement your theoretical knowledge with practical experience. There is no substitute for getting your hands dirty in the Azure portal. Set up a free or pay-as-you-go Azure subscription and work through labs and tutorials. Build your own end-to-end data pipelines. Ingest data into a data lake, transform it with Azure Data Factory and Azure Databricks, and load it into Azure Synapse Analytics. The more you use the tools, the more comfortable you will become with their nuances. This hands-on experience is critical for answering the practical, scenario-based questions on the exam.
Leveraging Practice Exams and Courses
Once you have a solid grasp of the concepts and some hands-on experience, practice exams are an invaluable tool for your final preparation. They help you get accustomed to the format and timing of the actual exam and identify your weak areas. When you get a question wrong, do not just look at the correct answer; take the time to research why that answer is correct and why the other options are incorrect. This process will significantly deepen your understanding of the material. Look for high-quality practice tests from reputable providers that offer detailed explanations for each question.
Consider enrolling in an instructor-led training course or a video-based course. These resources can provide a more structured learning experience and offer insights and tips from experienced professionals who have already passed the exam. A good instructor can help clarify complex topics and provide real-world context that makes the material easier to understand and remember. Combining these different learning methods—official documentation, hands-on labs, practice exams, and structured courses—will give you the comprehensive preparation needed to confidently sit for and pass the DP-203 exam.
During the Exam: Tips for Success
On exam day, it is important to manage your time effectively. The exam has a set number of questions and a time limit, so be mindful of the clock. If you encounter a difficult question, it is often best to make an educated guess, mark it for review, and move on. You can always come back to it later if you have time. Read each question carefully, paying close attention to keywords and requirements. The questions are often designed to test your ability to select the best solution among several possible options, so a thorough understanding of the scenario is key.
The DP-203 exam may include different question formats, including multiple-choice, drag-and-drop, and case studies. For case studies, you will be presented with a detailed business and technical scenario and will need to answer several questions related to it. Take the time to read the entire case study before you start answering the questions. Some exams may also feature a hands-on lab section where you are given access to a live Azure environment and tasked with completing a series of tasks. For these, follow the instructions precisely and use your practical experience to navigate the portal and complete the required configurations.
Conclusion
Embarking on the path to become a Microsoft Certified: Azure Data Engineer Associate is a decision to build a career at the forefront of the data revolution. This journey requires dedication to learning foundational concepts, mastering a powerful suite of cloud services, and validating your skills through a rigorous certification exam. The rewards for this effort are immense: a challenging and fulfilling career, excellent compensation, and the opportunity to be the architect of the systems that power modern, data-driven organizations. You are not just learning a job; you are learning how to transform raw data into insight and value.
The five parts of this guide have provided a comprehensive roadmap for your journey. We have explored the why, the what, and the how of becoming an Azure Data Engineer. From understanding the core responsibilities and foundational skills to deep-diving into the specific Azure services and preparing for the DP-203 exam, you now have a clear path forward. The final steps are up to you. Embrace the learning process, get hands-on experience, and confidently pursue your certification. The future of data is being built today, and as a Microsoft Certified: Azure Data Engineer Associate, you will be one of its principal architects.
Microsoft Certified: Azure Data Engineer Associate certification practice test questions and answers, training course, study guide are uploaded in ETE files format by real users. Study and pass Microsoft Microsoft Certified: Azure Data Engineer Associate certification exam dumps & practice test questions and answers are the best available resource to help students pass at the first attempt.



