- Home
- Snowflake Certifications
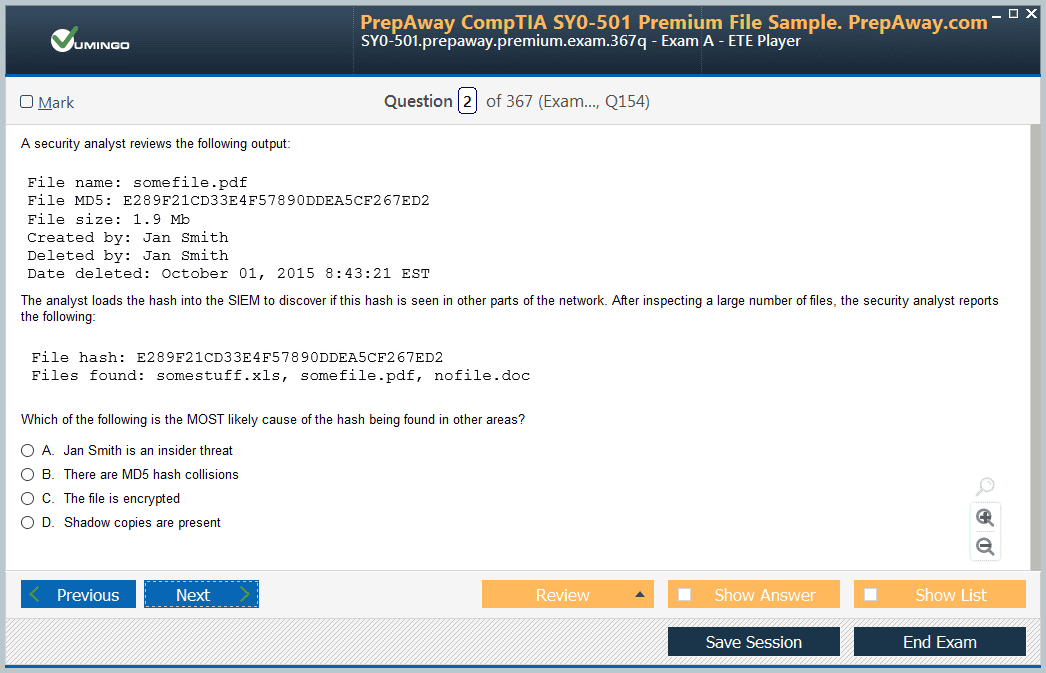
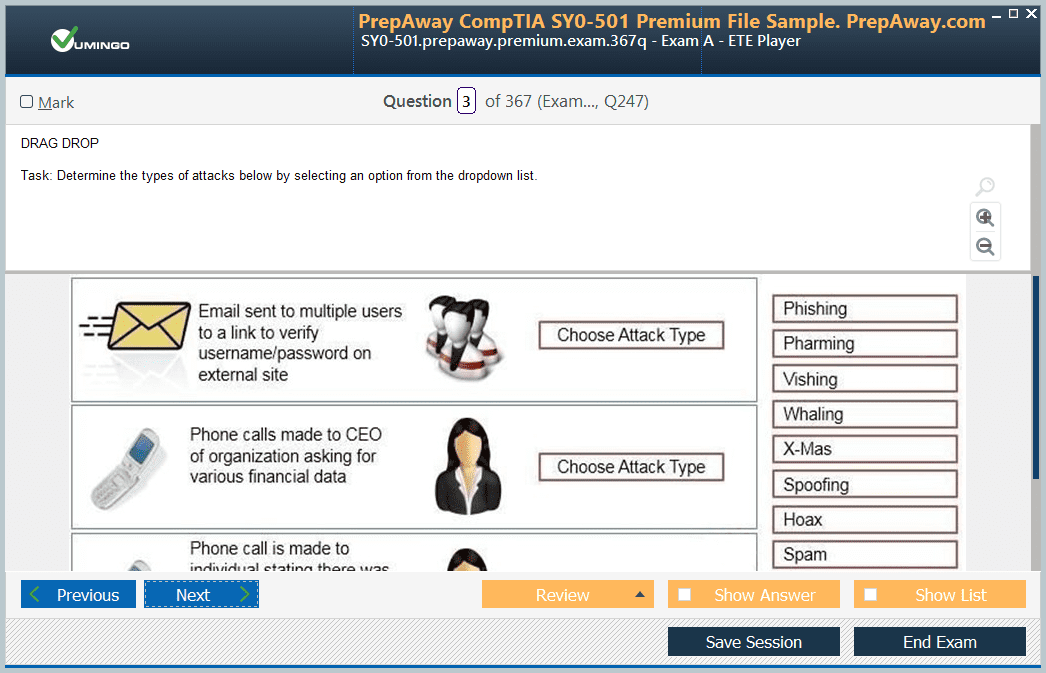
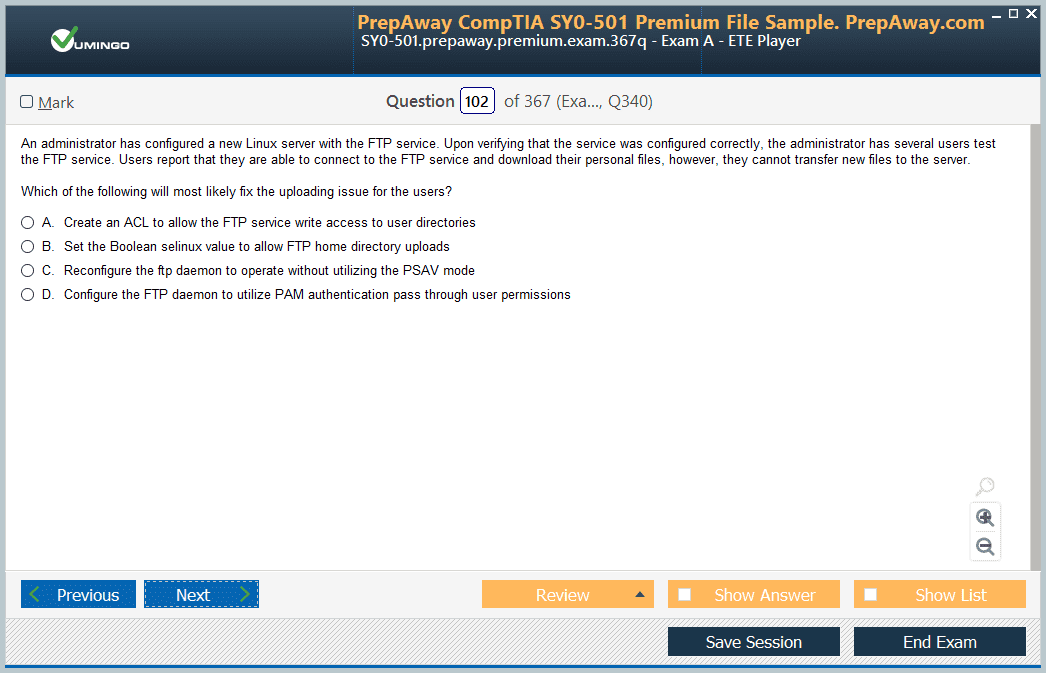
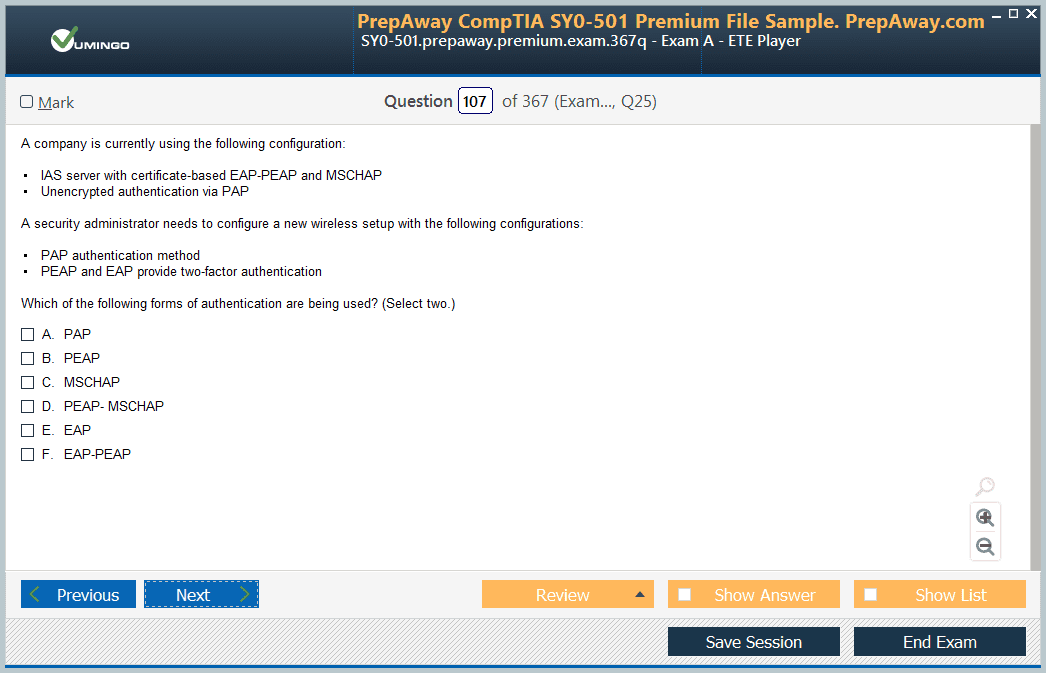
- SnowPro Advanced Data Engineer SnowPro Advanced Data Engineer Dumps
Pass Snowflake SnowPro Advanced Data Engineer Exam in First Attempt Guaranteed!
Get 100% Latest Exam Questions, Accurate & Verified Answers to Pass the Actual Exam!
30 Days Free Updates, Instant Download!


SnowPro Advanced Data Engineer Premium File
- Premium File 162 Questions & Answers. Last Update: Jul 03, 2026
Whats Included:
- Latest Questions
- 100% Accurate Answers
- Fast Exam Updates
Last Week Results!
All Snowflake SnowPro Advanced Data Engineer certification exam dumps, study guide, training courses are Prepared by industry experts. PrepAway's ETE files povide the SnowPro Advanced Data Engineer SnowPro Advanced Data Engineer practice test questions and answers & exam dumps, study guide and training courses help you study and pass hassle-free!
Your Roadmap to Becoming a SnowPro Advanced Data Engineer
The SnowPro Advanced Data Engineer certification is one of the most rigorous credentials offered for professionals who specialize in building and optimizing data solutions within the Snowflake ecosystem. Unlike introductory exams that primarily measure familiarity with platform basics, this certification goes deeper into architectural knowledge, practical design considerations, and the ability to troubleshoot and optimize solutions. It is aimed at experienced engineers who not only use Snowflake but also design pipelines, manage large-scale ingestion strategies, and ensure systems meet both performance and governance requirements.
This exam requires candidates to demonstrate knowledge that comes from real practice rather than theoretical study alone. It is not enough to memorize definitions or workflows. The exam tests how engineers analyze scenarios, design efficient approaches, and apply the platform’s features in a way that balances functionality, performance, and cost. Candidates are expected to know how to make trade-offs, recognize limitations, and configure Snowflake for reliability at scale.
Before attempting this certification, Snowflake advises candidates to have multiple years of experience as practitioners. This recommendation reflects the fact that the exam covers advanced patterns of data engineering that require more than surface-level exposure. Engineers preparing for the exam must be able to understand the consequences of architectural decisions, the way features interact with each other, and the practical challenges that arise in production environments.
The structure of the exam is organized into five domains, each representing a major aspect of Snowflake’s functionality as it relates to engineering responsibilities. The domains are weighted differently, which signals where most of the focus should be placed during preparation. Data movement and transformation together make up the majority of the exam, while performance optimization, storage, and security each play a significant role. This balance reflects the reality of modern data engineering in Snowflake: moving and transforming data are central, but they must be supported by secure, optimized, and reliable environments.
Breaking Down the Exam Domains
The five domains define the core areas of assessment. Data movement accounts for a significant portion of the exam, which is logical because it represents the foundation of how data reaches Snowflake and becomes usable. Performance optimization follows as another important category, ensuring candidates can diagnose and improve workloads. Storage and data protection test the ability to ensure resilience and recovery strategies, while security focuses on governance and proper role usage. Finally, data transformation emphasizes the capability to prepare data for consumption using advanced features and techniques.
Each domain is designed to test more than simple configuration knowledge. For example, in data movement, the exam does not simply ask whether a particular ingestion method exists but requires candidates to understand when it should be applied, what the trade-offs are, and how it fits within the larger ecosystem. This design ensures the certification measures advanced thinking rather than memorization.
Data Movement as a Core Skill
Data movement is the first and largest domain of the exam. It addresses how information flows into Snowflake and how engineers ensure these flows are reliable, scalable, and efficient. Preparing for this domain means understanding both traditional batch ingestion and modern continuous streaming approaches. It also requires familiarity with internal and external staging concepts and the considerations behind choosing one over another.
A key challenge for engineers is recognizing when to prioritize batch processes for efficiency and when to design streaming solutions for immediacy. Batch processes may be more cost-effective and easier to manage when working with large but infrequent datasets, while streaming ensures near real-time updates for operational use cases. The exam expects candidates to demonstrate knowledge of these distinctions and the ability to troubleshoot pipelines when they fail or underperform.
File formats are another essential aspect of this domain. Engineers are tested on their understanding of how Snowflake processes structured and semi-structured data such as CSV, JSON, Avro, or Parquet. This includes the ability to explain how these formats behave during loading, how metadata is handled, and how to ensure that ingestion works smoothly even when source files contain variations or errors. Engineers should also understand how to design pipelines that account for schema changes, unexpected data types, or malformed records.
Connectors also play a role in this domain. Snowflake integrates with many third-party systems and services through specialized connectors that enable data to flow from external platforms into the warehouse. Candidates are expected to be able to describe the role of these connectors, how they are configured, and when they should be used in preference to other ingestion approaches. Understanding connectors is essential because many enterprise data architectures rely on them to keep analytics environments synchronized with operational systems.
An equally important element in this domain is troubleshooting. Data engineers must know how to identify ingestion failures, validate that loads occurred correctly, and trace issues back to their root causes. The exam tests knowledge of monitoring mechanisms, diagnostic techniques, and the logical steps required to restore pipelines when problems arise. This skill goes beyond executing commands and reflects the daily responsibilities of engineers working with production systems.
Continuous Data Pipelines and Reliability
Modern organizations increasingly demand real-time or near real-time data availability, and Snowflake provides mechanisms for building continuous pipelines to meet this demand. This is another area heavily represented in the exam. Candidates must understand how Snowflake streams and tasks function together to support event-driven processing, incremental updates, and automated workflows.
Streams allow engineers to capture changes made to tables in near real time, providing a mechanism for implementing change data capture patterns. Tasks enable the scheduling and automation of queries or transformations, allowing engineers to design end-to-end workflows that execute without manual intervention. The exam requires not only an understanding of what these features are but also how to design robust systems with them, how to handle dependencies, and how to manage failures gracefully.
Another challenge is distinguishing between pipeline types. Some pipelines may rely on batch ingestion followed by transformation, while others may combine continuous loading with incremental processing. The exam tests the ability to analyze scenarios and select the correct approach based on performance requirements, data volumes, and business needs. This is where practical experience with real systems becomes invaluable.
Reliability is always a critical concern in continuous pipelines. Engineers are expected to know how to ensure that pipelines do not duplicate records, how to monitor ingestion performance, and how to design recovery processes if failures occur. This knowledge requires attention to both technical details and architectural best practices, ensuring pipelines are not only functional but also resilient.
Integrating Security into Data Engineering
Security represents a smaller but equally significant portion of the exam. Candidates must demonstrate understanding of Snowflake’s role-based access control system, the proper use of predefined roles, and how security policies align with organizational governance. Engineers must also understand how to manage data sharing securely, ensuring that sensitive information is protected while still enabling collaboration across teams.
The exam may test the ability to determine when and how to apply masking policies, how to configure row access policies, or how to design architectures that minimize risk exposure. Security responsibilities in data engineering are about ensuring not only that data flows smoothly but also that it remains protected from unauthorized access at every stage. This requires balancing ease of use with strict adherence to governance requirements.
Performance Optimization and Efficient Design
Performance optimization is another critical domain and one where practical experience makes a difference. Engineers are expected to recognize the causes of slow-running queries, identify resource bottlenecks, and recommend solutions that maximize efficiency. This includes understanding how Snowflake caching works, when to leverage materialized views, and how warehouse sizing affects performance and cost.
Monitoring continuous pipelines also falls under this domain. Engineers must know how to evaluate whether pipelines are running as intended, whether resources are sufficient, and how to adjust configurations for optimal throughput. Optimization is not just about speeding up queries but also about designing solutions that scale effectively as data volumes grow.
The exam requires a mindset of critical evaluation. Candidates must be able to analyze a given scenario and recommend adjustments that achieve performance goals without unnecessarily increasing costs. This requires both technical knowledge of Snowflake’s features and the judgment to know which solution fits best in practice.
Storage and Data Protection in Snowflake
Another significant part of the SnowPro Advanced Data Engineer certification relates to how data is stored, protected, and recovered within Snowflake. Storage is not only about keeping data but also about ensuring its durability, availability, and resilience against failures. Candidates must understand how Snowflake’s architecture separates storage from compute and what advantages this brings to engineering solutions. Storage in Snowflake is automatically compressed, encrypted, and distributed across availability zones, but engineers must still be able to explain how data is managed, how failures are handled, and what recovery options exist in different scenarios.
One area of focus is time travel. This feature allows engineers to query historical versions of data and recover tables or schemas from previous states. It provides protection against accidental deletions or data corruption, making it a critical concept for engineers to understand in detail. Preparing for the exam requires knowing how time travel works, the limits on retention, and how it differs from other recovery mechanisms.
Another important feature is fail-safe. Fail-safe ensures that after the time travel window expires, Snowflake can still recover historical data for a short period. The exam expects candidates to understand how fail-safe functions, what responsibilities engineers have in relation to it, and how it supports business continuity in rare situations. Together, time travel and fail-safe highlight how Snowflake offers multiple layers of protection, and engineers must be able to evaluate when and how these features are useful in real-world pipelines.
Cloning is another storage feature covered in the exam. Zero-copy cloning enables the creation of replicas of tables, schemas, or even databases without physically duplicating data. Engineers are expected to understand how cloning can be used for testing, development, or recovery scenarios. They must also know the impact of cloning on costs and storage management.
An advanced engineer must also be aware of data retention policies, lifecycle management, and the interaction between different protection mechanisms. The exam tests not just whether candidates know that these features exist but also whether they can design reliable solutions by applying them appropriately. For example, combining time travel with cloning can enable safe experimentation without affecting production data.
Advanced Data Transformation Concepts
Data transformation is another major domain in the certification. It covers how raw data is shaped, cleaned, and prepared for analytics or operational use cases. This domain makes up a large portion of the exam because transformation is often the heart of data engineering in Snowflake. Candidates must show deep understanding of SQL-based transformations, best practices for structuring queries, and how to use Snowflake-specific features to achieve efficient data preparation.
Tasks and streams play a major role in transformation workflows. Engineers are expected to know how these objects work together to automate transformations in a reliable way. Tasks can be scheduled or event-driven, while streams provide change data capture, enabling transformations that only process new or changed records. Mastery of these features requires knowledge of how to design chains of tasks, how to manage dependencies, and how to monitor execution.
Materialized views are another concept tested in the exam. Engineers must understand when to use them to optimize repeated queries, how they improve performance, and what limitations they bring. Knowledge of when a materialized view should be refreshed and how it interacts with changing datasets is also essential. This goes hand in hand with performance optimization, as materialized views can dramatically reduce query costs when used correctly.
The exam also requires familiarity with semi-structured data processing. Snowflake provides functions to work with JSON, Avro, and other flexible formats. Engineers must be able to explain how to parse, query, and transform this data into relational structures. More importantly, they must be able to design transformations that handle variability in the data without introducing errors or inefficiencies.
Another transformation feature is stored procedures and user-defined functions. These allow engineers to encapsulate logic and reuse it across pipelines. The exam may test knowledge of when to use stored procedures instead of tasks or views, how to maintain them, and how they fit into larger architectures. Engineers must understand the trade-offs of procedural logic compared to SQL queries and how each approach affects maintainability.
Data transformation also touches on governance. Engineers need to ensure that transformations do not strip away important context or violate compliance requirements. For example, applying masking policies before making transformed data available to analysts ensures sensitive information is protected. Understanding how to combine governance with transformation workflows is a skill tested by the certification.
Preparing for Complex Scenarios
The SnowPro Advanced Data Engineer exam is scenario-based, meaning that it tests the ability to apply knowledge to complex, realistic situations. Candidates are not simply asked to recall terminology but are presented with use cases that require analyzing trade-offs and designing solutions. For example, a scenario might describe a business requirement for near real-time analytics alongside cost efficiency. The engineer must decide whether to use Snowpipe, streams and tasks, or a combination of both, justifying the decision based on performance and cost.
To succeed, candidates need to practice thinking in terms of trade-offs. One solution might maximize performance but increase cost, while another might be more cost-efficient but slower. The exam tests whether engineers can find the right balance for the given situation. This reflects the reality of working with Snowflake, where engineers must often choose between competing priorities.
Another common scenario involves troubleshooting. The exam may describe a pipeline that has stopped ingesting data or a transformation that produces incorrect results. Candidates must determine what went wrong and propose a fix. This requires understanding not only features but also diagnostic methods, such as using system views to trace queries, monitoring warehouse usage, or checking stage file statuses.
Complex scenarios also involve integrating multiple domains. For example, designing a secure transformation workflow may require knowledge of streams and tasks, role-based access controls, and masking policies all at once. This integration of topics is why the exam is considered advanced and why preparation must be comprehensive.
Strategies for Effective Preparation
Preparing for the SnowPro Advanced Data Engineer certification requires both study and practice. Reading documentation or guides provides theoretical understanding, but hands-on experimentation builds the intuition needed for the exam. Candidates should create their own Snowflake environments where they can practice loading data, designing transformations, and monitoring pipelines. This experimentation reveals nuances that cannot be learned from reading alone.
A structured preparation plan is often the most effective. One approach is to dedicate time to each exam domain in sequence, ensuring that all areas are covered in depth. For example, a candidate might start with data movement, practicing different ingestion methods, then move on to transformation, performance, storage, and security. At the end of the cycle, they can review all domains together to build connections between them.
Practice questions can be useful but should be treated as self-assessment tools rather than memorization exercises. They reveal weak areas that require more focus. Reviewing those weak areas by experimenting in Snowflake is often the best way to strengthen understanding.
It is also valuable to practice explaining concepts in plain language. The exam requires not just technical knowledge but the ability to reason through scenarios clearly. Being able to describe why a particular design choice is best for a given problem ensures deeper comprehension.
Another effective strategy is to focus on troubleshooting. Since the exam emphasizes problem-solving, candidates should practice identifying and fixing pipeline issues. This might involve deliberately creating ingestion errors, misconfigured tasks, or incorrect transformations in a practice environment, then working through how to diagnose and resolve them. This builds the mindset of analysis and resolution that is crucial for the exam.
Building the Right Mindset
Beyond technical knowledge, success in the SnowPro Advanced Data Engineer certification requires adopting the mindset of an architect. Engineers must think not only about immediate solutions but also about long-term maintainability, scalability, and governance. The exam challenges candidates to step into this role by testing their ability to evaluate designs, predict potential issues, and apply best practices consistently.
An advanced engineer must always consider performance and cost together, design for resilience rather than quick fixes, and ensure that data remains secure without hindering accessibility for those who need it. This holistic perspective is what distinguishes advanced certification holders from those at the introductory level.
When preparing, candidates should focus on connecting the details of Snowflake features to this broader mindset. For example, understanding how streams and tasks work is important, but understanding how to design a robust pipeline with them that will scale over time is even more valuable. Similarly, knowing how to use time travel is useful, but knowing how to integrate it into a disaster recovery strategy is essential for real-world success.
Integrating Domains for Real Exam Success
The SnowPro Advanced Data Engineer certification is unique in that it does not test knowledge in isolation. While the exam is divided into domains such as data movement, transformation, optimization, storage, and security, the questions often require candidates to integrate these areas into a single solution. This integration reflects the way real data engineering projects are handled, where tasks rarely exist in a vacuum. A pipeline that loads data must also be optimized for performance, secured against unauthorized access, and protected for recovery in case of failure. Understanding this holistic approach is essential for achieving success in the certification.
Candidates need to prepare by practicing how to connect concepts across domains. For example, loading semi-structured data into Snowflake requires knowledge of file formats, stages, and COPY commands, but it also requires thinking ahead about how that data will be transformed and queried. If the data will be transformed regularly, then performance considerations such as clustering or materialized views may become relevant. If the data contains sensitive information, masking or access policies must be considered from the start. Practicing this kind of connected reasoning is critical preparation for the advanced exam.
Another way integration plays a role is in troubleshooting. An ingestion problem might initially appear to be a data movement issue, but upon investigation it could be related to task scheduling, role-based permissions, or warehouse sizing. Engineers who prepare for the exam should build the habit of analyzing issues from multiple perspectives instead of limiting their thinking to a single domain.
Deepening Understanding of Semi-Structured Data
Semi-structured data is increasingly common in real-world environments, and the exam reflects this reality. Engineers must be able to design ingestion, storage, and transformation workflows that handle JSON, Avro, Parquet, and other formats seamlessly. The ability to parse nested structures, flatten arrays, and extract fields dynamically is essential for handling these data types efficiently.
Preparing for this aspect of the exam requires not only practicing the functions Snowflake provides for working with semi-structured data but also understanding the performance implications of using them. Large nested structures can be expensive to query if not handled carefully, and engineers must know when to normalize data into relational tables and when to preserve it in its original format for flexibility.
Candidates should also understand schema evolution in semi-structured data. Unlike relational tables, which require strict schema definitions, semi-structured files often evolve over time. New fields may be added, existing ones may change type, or unexpected variations may appear. Engineers are expected to design transformations and queries that handle these changes gracefully without causing failures. This requires thinking carefully about how queries are written, how defaults are applied, and how missing values are managed.
Semi-structured data also interacts with performance optimization. Engineers must know how to minimize repeated parsing, how to use materialized views on frequently queried fields, and how to balance flexibility with efficiency. The exam tests this deeper knowledge by presenting scenarios where the naive solution may work but at an unacceptably high cost. Candidates who prepare for these scenarios by practicing with large datasets and experimenting with optimization techniques will be better equipped to succeed.
Governance and Policy Enforcement
Another important dimension of the certification is governance. Data engineers do not work in isolation; they operate within organizations where compliance, security, and governance are mandatory. The exam emphasizes the ability to implement Snowflake features that enforce governance policies while still enabling efficient workflows.
Candidates should be comfortable with role-based access control and understand how to design hierarchies of roles that align with organizational responsibilities. Engineers must ensure that least-privilege principles are respected, meaning that users and services have only the access they need and nothing more. The exam may test knowledge of how to configure roles for tasks, pipelines, and data sharing scenarios.
Masking policies and row access policies are also important. Masking allows sensitive fields to be protected while still enabling broader access to datasets, and row access policies restrict visibility based on user attributes or roles. Engineers must be able to explain how these features work, when to use them, and how to integrate them with transformation or sharing processes.
Data sharing is another governance-related area that engineers should prepare for. Snowflake enables secure sharing of data across accounts, and candidates must know how to configure shares in a way that maintains both usability and protection. The exam may test the ability to reason through scenarios where sensitive and non-sensitive data need to be shared selectively, requiring careful design of views, policies, and role assignments.
Advanced Optimization Strategies
Performance optimization is more than adjusting warehouse sizes. The exam challenges candidates to understand the full range of techniques available in Snowflake for ensuring queries and pipelines run efficiently. This includes knowledge of caching, clustering, pruning, micro-partitioning, and the design of transformations that minimize unnecessary computation.
One of the most important concepts is micro-partitioning. Snowflake automatically divides data into micro-partitions, and understanding how queries can take advantage of pruning to skip irrelevant partitions is critical for performance. Engineers preparing for the exam should know how clustering keys can improve pruning, when they are beneficial, and when they add unnecessary overhead.
Materialized views are another optimization strategy tested in the exam. Engineers should know how to select queries that benefit from materialization, how refreshes are handled, and what limitations exist. Understanding the trade-offs between storage costs and performance improvements is essential, as the exam often frames questions around balancing efficiency and expense.
Warehouse sizing and scaling strategies also appear in exam scenarios. Engineers must know when to scale up for more compute power, when to scale out for concurrency, and how to balance auto-suspension and auto-resume settings to minimize costs without sacrificing responsiveness.
Another optimization area involves monitoring and diagnostics. Engineers must know how to analyze query profiles, identify bottlenecks, and adjust designs accordingly. The exam may present scenarios where pipelines are underperforming, and candidates must determine whether the issue lies in warehouse size, query design, clustering, or transformations.
Building Exam-Ready Expertise
While studying the features of Snowflake is important, success in the SnowPro Advanced Data Engineer certification requires developing expertise through practice and problem-solving. The exam measures whether candidates can reason through advanced scenarios and apply their knowledge to realistic challenges.
Candidates should invest significant time in building their own practice environments and experimenting with different ingestion methods, transformation techniques, and optimization strategies. Working through realistic projects such as designing a continuous pipeline for semi-structured data or optimizing queries on large datasets builds the intuition that is tested in the exam.
Another way to prepare is to focus on troubleshooting exercises. Engineers should deliberately create failing pipelines, misconfigured tasks, or inefficient queries and then work through how to diagnose and fix them. This not only builds technical skills but also strengthens the analytical thinking required for scenario-based questions.
Developing strong documentation and explanation habits also helps. The exam often requires candidates to reason clearly about why one design is better than another. Practicing the ability to justify decisions with clear reasoning ensures that the underlying concepts are well understood.
Finally, building exam readiness requires adopting the mindset of an architect. Engineers must think about long-term scalability, governance, and reliability. The exam is not about quick fixes but about designing systems that will stand up to real-world demands. Preparing with this mindset ensures that candidates not only pass the certification but also grow into more capable professionals.
The Value of the Certification
The SnowPro Advanced Data Engineer certification is not simply a test of knowledge but a recognition of expertise. Achieving it demonstrates that an engineer can design, optimize, and manage advanced Snowflake solutions in a way that aligns with organizational needs. It validates the ability to handle complex challenges, balance competing priorities, and integrate features into robust architectures.
For many professionals, the process of preparing for the exam is as valuable as the certification itself. The structured study, practice, and reflection required to succeed deepen understanding and strengthen practical skills. By mastering the domains of data movement, transformation, optimization, storage, and security, candidates build confidence not only in passing the exam but also in applying their skills to real projects.
The certification represents a benchmark of advanced competence in Snowflake engineering. It signals the ability to think critically, solve complex problems, and apply best practices consistently. For engineers who want to grow their careers, it is both a challenge and an opportunity to prove their expertise in one of the most advanced areas of modern data engineering.
Mastering End-to-End Pipeline Design
A critical aspect of the SnowPro Advanced Data Engineer certification is understanding how to design end-to-end data pipelines that are reliable, secure, and scalable. The exam evaluates whether candidates can integrate ingestion, transformation, optimization, and governance into a complete workflow. This requires knowledge that goes beyond isolated features and tests the ability to orchestrate multiple components into a single functioning system.
End-to-end design begins with data movement. Engineers must consider how data will be ingested into Snowflake, whether through batch loading, streaming, or connectors. Each method has implications for performance, cost, and reliability. For example, batch loading might be efficient for large, periodic transfers, while continuous ingestion is better suited for time-sensitive data. Understanding these trade-offs is vital.
Once data arrives, engineers must design transformations that prepare it for analytics or downstream systems. This involves using streams and tasks to automate workflows, materialized views to optimize performance, and stored procedures or functions to encapsulate logic. The exam expects candidates to think carefully about how these transformations interact with the ingestion layer and how to maintain efficiency over time.
Pipelines must also be monitored and maintained. Snowflake provides views and tools for tracking performance, errors, and usage. Engineers must know how to implement monitoring strategies that catch issues early and how to build recovery processes when failures occur. This focus on reliability is central to the exam’s design, as it reflects real-world challenges.
Finally, governance must be integrated into pipelines. Data must remain secure at every stage, with masking and row access policies applied where needed. Role-based access must be carefully designed to ensure that users and services have the right level of permissions. The exam tests whether candidates can design pipelines that not only deliver data but also respect organizational governance and compliance.
Scenario-Based Reasoning
The SnowPro Advanced Data Engineer exam uses scenario-based questions to assess how well candidates can apply knowledge in realistic situations. This means that success requires more than recalling commands or definitions. Candidates must read a situation, identify the requirements, and decide on the best approach.
For example, a scenario might describe a company that receives continuous streams of JSON data from applications and needs to transform it for analytics. The correct solution may involve using Snowpipe for ingestion, streams to track changes, and tasks to run incremental transformations. At the same time, the solution might need to include role-based security and monitoring of warehouse usage. The ability to connect these requirements and recommend the right combination of features is what the exam measures.
Another scenario might describe a query running slowly on a large dataset. Candidates would need to identify that clustering keys could improve pruning, or that a materialized view could cache results for repeated queries. The key is not only knowing the technical details but also understanding which strategy is appropriate given the context.
These scenarios often involve multiple domains at once. Troubleshooting a pipeline could require examining ingestion methods, transformation logic, warehouse sizing, and security roles. Engineers preparing for the exam must practice thinking broadly and connecting knowledge across domains.
Building Resilient Architectures
Resilience is a central theme in the exam. Engineers are expected to design systems that continue functioning despite failures, unexpected changes, or growth in data volumes. This requires knowledge of Snowflake’s features for data protection, monitoring, and recovery.
One element of resilience is time travel. Engineers must know how to use it to recover from accidental deletions or errors in transformations. Cloning is another feature that supports resilience, enabling quick creation of test environments or backups without incurring the overhead of copying data. Fail-safe provides yet another layer of protection, ensuring that even when time travel expires, recovery remains possible.
Resilience also involves monitoring and alerting. Engineers must be able to describe how to track pipeline health, monitor warehouse activity, and detect anomalies in query performance. Building systems that can recover automatically, such as tasks that retry on failure, is an important skill for the exam.
Scalability is closely linked to resilience. A pipeline that works for small datasets may fail when volumes grow. Engineers must design systems that scale efficiently by leveraging features like warehouse scaling, clustering, and partition pruning. The exam may test whether candidates can identify potential scalability issues in a given design and propose improvements.
Transformation at Scale
Transformation is one of the most heavily weighted domains in the exam, and engineers must show advanced understanding of how to prepare large datasets efficiently. At scale, simple solutions often become too expensive or slow, and engineers must apply Snowflake’s features to keep pipelines efficient.
Materialized views, for example, allow repeated queries to be served quickly, but they come with refresh costs and limitations. Engineers must know when the benefits outweigh the trade-offs. Similarly, clustering keys can improve query performance, but if chosen poorly they may add more cost than value.
Semi-structured data transformation is also critical. JSON, Avro, and Parquet files may contain deeply nested structures that are expensive to process repeatedly. Engineers must know how to flatten or restructure data efficiently and how to design queries that minimize unnecessary parsing. This requires balancing flexibility with performance.
Stored procedures and user-defined functions also play a role in transformation. They allow reusable logic and complex workflows, but engineers must consider maintainability and performance. The exam may test knowledge of when to use these features compared to simpler SQL-based solutions.
Optimization as a Continuous Process
The exam emphasizes that optimization is not a one-time task but a continuous responsibility. Engineers must know how to monitor workloads, analyze query performance, and adjust designs over time. This reflects the real-world reality that data, queries, and business needs change constantly.
Candidates must understand how Snowflake caching works, when it provides benefits, and when queries must still scan data. They must know how to size warehouses for efficiency, when to scale up versus scale out, and how to balance cost and performance.
Monitoring is essential for ongoing optimization. Engineers should know how to use query history, execution details, and warehouse usage views to identify bottlenecks. The exam tests the ability to analyze these details and recommend improvements.
Another optimization strategy is managing concurrency. Engineers must understand how Snowflake’s multi-cluster warehouses handle concurrent workloads and when to use them. Balancing concurrency with cost efficiency is often tested in scenario questions.
Final Preparation Strategies
Preparing for the SnowPro Advanced Data Engineer certification requires a focused approach. Since the exam is scenario-based, candidates should practice reasoning through real-world problems rather than relying only on definitions. Setting up a practice environment in Snowflake and experimenting with ingestion, transformation, and optimization is the most effective preparation method.
Candidates should also study system views and monitoring tools. These provide insights into query execution, pipeline performance, and warehouse usage, all of which are relevant to exam questions. Practicing how to analyze these details builds the diagnostic skills needed for troubleshooting scenarios.
Reviewing each domain systematically is helpful, but connecting the domains is even more important. Candidates should practice designing complete workflows that include ingestion, transformation, optimization, governance, and recovery. This builds the integration skills that are central to the exam.
It is also useful to document and explain design decisions during preparation. Writing out why a particular feature was chosen for a solution ensures that the reasoning is clear and reinforces understanding. This practice mirrors the exam, where candidates must evaluate scenarios and select the most appropriate option.
Achieving Certification
The SnowPro Advanced Data Engineer certification demonstrates advanced mastery of Snowflake’s platform. It shows that an engineer can design and manage systems that move, transform, and secure data at scale while balancing performance and cost. Achieving this certification requires not just knowledge of individual features but also the ability to integrate them into reliable architectures.
For professionals, the certification provides recognition of expertise and validates skills that are valuable in complex data environments. The process of preparing for the exam strengthens practical abilities, sharpens problem-solving skills, and builds confidence in handling advanced scenarios.
The certification is both a challenge and an achievement. By mastering the exam domains and practicing with real-world scenarios, engineers prove their ability to handle the advanced responsibilities of data engineering in Snowflake. It is a mark of readiness to design resilient, scalable, and secure solutions that support organizational success.
Advanced Security and Governance in Snowflake
The SnowPro Advanced Data Engineer exam goes deep into the concepts of security and governance because a well-designed system must not only process and transform data but also protect it at every stage. Candidates are expected to understand how Snowflake implements security controls across data storage, computation, and user access. This involves knowing how encryption works, how access policies are defined, and how sensitive data can be masked or restricted at query time.
Snowflake encrypts data automatically at rest and in transit, but engineers must still understand the details to answer questions in the exam. Knowledge of key management, automatic re-encryption, and how data is secured at different stages of its lifecycle is critical. Beyond encryption, engineers must also be able to explain and configure role-based access controls that define what users, applications, or services can see and do. The exam tests the ability to design role hierarchies that support least privilege access without making administration overly complex.
Row access policies and masking policies are another important part of governance. Engineers need to understand how these can be applied to protect sensitive columns or rows, ensuring that users only see the data they are authorized to view. This goes beyond simple permissions and requires careful planning to avoid performance penalties or misconfigurations. Candidates should also be aware of how to test and monitor these policies to confirm they work as intended in real-world pipelines.
Data sharing also requires careful governance. Snowflake allows secure data sharing across accounts, but this must be controlled to prevent accidental exposure. Engineers preparing for the exam must understand how shares are created, how access is managed, and how secure views or masking can be layered on top of shared data. These details are tested in the exam because they are critical in real-world implementations where organizations exchange data regularly.
Designing for Cost Efficiency
The SnowPro Advanced Data Engineer exam includes questions about cost management because engineers are expected to design solutions that balance performance with efficiency. Candidates need to understand how compute, storage, and data transfer costs interact and how design choices can influence long-term expense.
One key concept is warehouse management. Engineers must know when to use a single large warehouse versus multiple smaller ones, and when to enable auto-suspend or auto-resume. The ability to right-size warehouses for different workloads is central to cost control. The exam often tests whether candidates can identify wasteful practices such as keeping warehouses running unnecessarily or choosing sizes that are not aligned with the workload.
Storage costs also matter. While Snowflake’s storage is relatively inexpensive, inefficient practices like unnecessary materialized views, poorly managed clustering, or duplicate datasets can increase costs significantly. Engineers should understand how to monitor storage usage, how to manage retention periods for time travel, and how to avoid unnecessary data duplication through cloning.
Data transfer costs can be more subtle but are equally important. When data is moved across regions or cloud providers, costs may rise. Engineers must understand how to minimize unnecessary transfers by keeping pipelines localized and by using Snowflake features like external tables strategically. These considerations are often built into scenario questions in the exam, where the best solution is not only the technically correct one but also the most cost-efficient.
Monitoring and Observability
Another area tested in the SnowPro Advanced Data Engineer exam is monitoring and observability. Engineers must be able to track system performance, diagnose bottlenecks, and implement solutions for long-term stability. This involves understanding Snowflake’s system views, information schema, and account usage tables.
Monitoring query performance is a major focus. Candidates must know how to analyze execution plans, identify which parts of a query are consuming resources, and determine whether clustering, caching, or restructuring the SQL would improve results. The exam may present scenarios where a query is running slowly and require the candidate to recommend changes based on query history or performance metrics.
Warehouse monitoring is also important. Engineers must know how to track credit usage, concurrency issues, and scaling behavior. For example, if multiple workloads are competing for resources, a multi-cluster warehouse may be needed. The exam tests knowledge of how to identify such cases and recommend the right scaling strategy.
Pipeline monitoring is another dimension. Snowflake streams and tasks can fail or stall, and engineers must know how to monitor these processes. The exam expects knowledge of how to detect and recover from failures, how to track task execution history, and how to troubleshoot data ingestion or transformation issues.
Beyond technical monitoring, observability extends into auditing and compliance. Engineers must know how to track who accessed which data, when changes occurred, and how these logs can be used for governance or troubleshooting. The ability to design pipelines that are both observable and auditable is tested because it is critical in environments that handle sensitive or regulated data.
Advanced Transformation Workflows
Transformation is one of the most complex areas of the SnowPro Advanced Data Engineer certification. Candidates are expected to design workflows that process large and complex datasets efficiently, reliably, and in a way that supports downstream analytics.
One focus is the management of semi-structured data. JSON, Avro, and Parquet files are common in modern data pipelines, and engineers must know how to extract, flatten, and transform these efficiently. The exam tests knowledge of functions for handling semi-structured data and strategies for avoiding performance issues when parsing large nested structures.
Incremental processing is another important topic. Rather than reprocessing entire datasets repeatedly, pipelines should process only the new or changed data. Engineers must know how to use streams to track changes and tasks to run scheduled transformations. The exam evaluates whether candidates can design efficient incremental workflows that scale.
Materialized views and clustering are also part of transformation design. Engineers must know how to apply these features to optimize query performance and when not to use them because of cost or limitations. The exam may include scenarios where candidates must decide whether clustering or materialized views are appropriate solutions.
Stored procedures and user-defined functions are another area of focus. Engineers must know how to encapsulate logic in a way that improves maintainability and reusability without sacrificing performance. The exam may present scenarios where a procedure is required to automate a transformation pipeline and test whether candidates know the best way to implement it.
Exam Preparation Through Practical Experience
The SnowPro Advanced Data Engineer exam is not about memorizing definitions but about applying knowledge in practical scenarios. The most effective preparation strategy is to spend time working directly in a Snowflake environment and building end-to-end pipelines. Candidates should practice loading different file types, designing transformation workflows, monitoring query performance, and securing data with policies.
Hands-on experimentation is especially important for understanding trade-offs. For example, candidates can practice designing a pipeline with clustering keys, monitor performance improvements, and measure costs. They can then experiment with materialized views and compare results. This kind of practical knowledge is what the exam is designed to test.
Studying Snowflake’s documentation is useful for understanding features, but applying those features in practice is what cements knowledge. Candidates should set up sample use cases, such as processing clickstream data, integrating semi-structured logs, or sharing data securely with another account. These exercises prepare engineers to answer the scenario-based questions in the exam confidently.
It is also helpful to review system views regularly and become comfortable analyzing warehouse usage, query execution details, and storage consumption. Many exam questions present scenarios that require interpreting this information, so familiarity with the system tables is a major advantage.
The Value of the Certification
Earning the SnowPro Advanced Data Engineer certification validates a professional’s ability to design and manage complex data systems in Snowflake. It demonstrates not only technical knowledge but also the ability to apply best practices for performance, security, governance, and cost efficiency. The exam is designed to reflect real-world challenges, so those who pass have proven they can handle advanced responsibilities in production environments.
The certification also builds confidence. Preparing for the exam requires exploring features in detail, understanding trade-offs, and practicing troubleshooting. This process strengthens practical skills that are immediately useful in day-to-day engineering work. Engineers who complete the certification are better prepared to design resilient, efficient, and secure systems that support business goals.
Finally, the certification represents a commitment to mastering modern data engineering. Snowflake is widely used for cloud data platforms, and being certified at the advanced level shows that an engineer is capable of working on challenging projects and contributing to enterprise-scale data strategies. For many professionals, the process of preparing for and passing the exam is as valuable as the credential itself, because it deepens understanding and improves problem-solving skills.
Conclusion
The SnowPro Advanced Data Engineer certification is more than just a technical assessment; it is a validation of deep, practical expertise in building, optimizing, and governing complex data ecosystems within Snowflake. Unlike introductory-level exams that measure familiarity, this certification challenges professionals to demonstrate an advanced understanding of design trade-offs, performance tuning, governance enforcement, and transformation at scale. Preparing for it requires not only studying theoretical concepts but also applying them in real-world scenarios to build pipelines that are reliable, secure, and cost-efficient.
One of the most important lessons reinforced through preparation is the interconnectedness of Snowflake’s features. Data engineers are not simply expected to ingest data or optimize queries in isolation but to create systems where ingestion, transformation, optimization, and governance work together seamlessly. This holistic perspective reflects how Snowflake is used in production environments, where decisions in one area directly influence outcomes in another. Candidates who succeed in the exam show they can step back and evaluate entire architectures rather than focusing narrowly on one feature at a time.
Another critical takeaway is the importance of scalability and resilience. The exam consistently tests whether engineers can design pipelines that continue to function as data grows, users increase, or unexpected failures occur. Features such as time travel, cloning, materialized views, clustering, streams, and tasks all contribute to building solutions that scale without losing efficiency or reliability. Engineers who prepare thoroughly come away with a stronger ability to anticipate problems and design architectures that are both robust and adaptable.
Security and governance form another cornerstone of the certification. In modern data engineering, protecting data is as important as moving and transforming it. The exam ensures that certified professionals understand role-based access, masking policies, row-level security, and secure data sharing, proving that they can safeguard sensitive information while enabling productive access for authorized users. This focus on governance reflects the growing importance of compliance, privacy, and accountability in data engineering roles.
Ultimately, achieving the SnowPro Advanced Data Engineer certification is a professional milestone that demonstrates readiness to handle the most challenging aspects of cloud data engineering. It validates the ability to build pipelines that are not only functional but also optimized, governed, secure, and sustainable over time. The journey of preparing for the exam enhances both technical and strategic thinking, ensuring that certified professionals are well-equipped to design solutions that support long-term business success. For engineers committed to advancing their expertise, this certification represents both recognition and growth in their professional journey.
Snowflake SnowPro Advanced Data Engineer practice test questions and answers, training course, study guide are uploaded in ETE Files format by real users. Study and Pass SnowPro Advanced Data Engineer SnowPro Advanced Data Engineer certification exam dumps & practice test questions and answers are to help students.
- SnowPro Core
- SnowPro Advanced Architect
- SnowPro Specialty Gen AI GES-C01
- SnowPro Advanced Data Engineer
- SnowPro Advanced Data Scientist - SnowPro Advanced Data Scientist DSA-C03
- SnowPro Advanced Administrator ADA-C02
- SnowPro Core COF-C03
- SnowPro Advanced Administrator - SnowPro Advanced Administrator ADA-C01
Why customers love us?
What do our customers say?
The resources provided for the Snowflake certification exam were exceptional. The exam dumps and video courses offered clear and concise explanations of each topic. I felt thoroughly prepared for the SnowPro Advanced Data Engineer test and passed with ease.
Studying for the Snowflake certification exam was a breeze with the comprehensive materials from this site. The detailed study guides and accurate exam dumps helped me understand every concept. I aced the SnowPro Advanced Data Engineer exam on my first try!
I was impressed with the quality of the SnowPro Advanced Data Engineer preparation materials for the Snowflake certification exam. The video courses were engaging, and the study guides covered all the essential topics. These resources made a significant difference in my study routine and overall performance. I went into the exam feeling confident and well-prepared.
The SnowPro Advanced Data Engineer materials for the Snowflake certification exam were invaluable. They provided detailed, concise explanations for each topic, helping me grasp the entire syllabus. After studying with these resources, I was able to tackle the final test questions confidently and successfully.
Thanks to the comprehensive study guides and video courses, I aced the SnowPro Advanced Data Engineer exam. The exam dumps were spot on and helped me understand the types of questions to expect. The certification exam was much less intimidating thanks to their excellent prep materials. So, I highly recommend their services for anyone preparing for this certification exam.
Achieving my Snowflake certification was a seamless experience. The detailed study guide and practice questions ensured I was fully prepared for SnowPro Advanced Data Engineer. The customer support was responsive and helpful throughout my journey. Highly recommend their services for anyone preparing for their certification test.
I couldn't be happier with my certification results! The study materials were comprehensive and easy to understand, making my preparation for the SnowPro Advanced Data Engineer stress-free. Using these resources, I was able to pass my exam on the first attempt. They are a must-have for anyone serious about advancing their career.
The practice exams were incredibly helpful in familiarizing me with the actual test format. I felt confident and well-prepared going into my SnowPro Advanced Data Engineer certification exam. The support and guidance provided were top-notch. I couldn't have obtained my Snowflake certification without these amazing tools!
The materials provided for the SnowPro Advanced Data Engineer were comprehensive and very well-structured. The practice tests were particularly useful in building my confidence and understanding the exam format. After using these materials, I felt well-prepared and was able to solve all the questions on the final test with ease. Passing the certification exam was a huge relief! I feel much more competent in my role. Thank you!
The certification prep was excellent. The content was up-to-date and aligned perfectly with the exam requirements. I appreciated the clear explanations and real-world examples that made complex topics easier to grasp. I passed SnowPro Advanced Data Engineer successfully. It was a game-changer for my career in IT!


