- Home
- Veritas Certifications
- VCS-323 Administration of Veritas Backup Exec 16 Dumps
Pass Veritas VCS-323 Exam in First Attempt Guaranteed!


VCS-323 Premium File
- Premium File 85 Questions & Answers. Last Update: Jul 14, 2026
Whats Included:
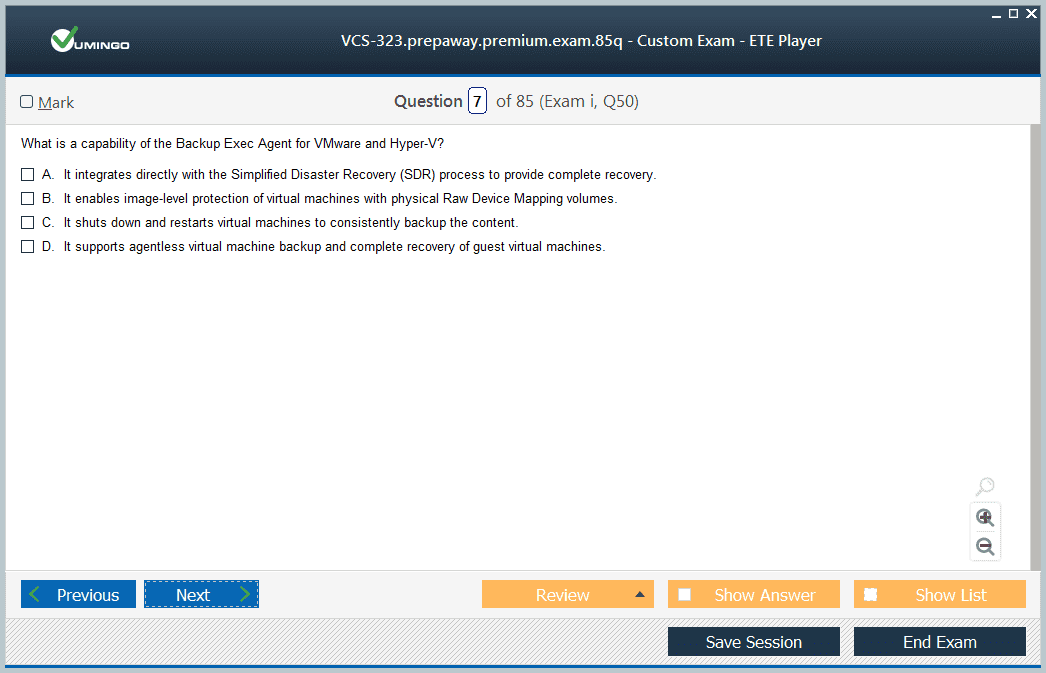
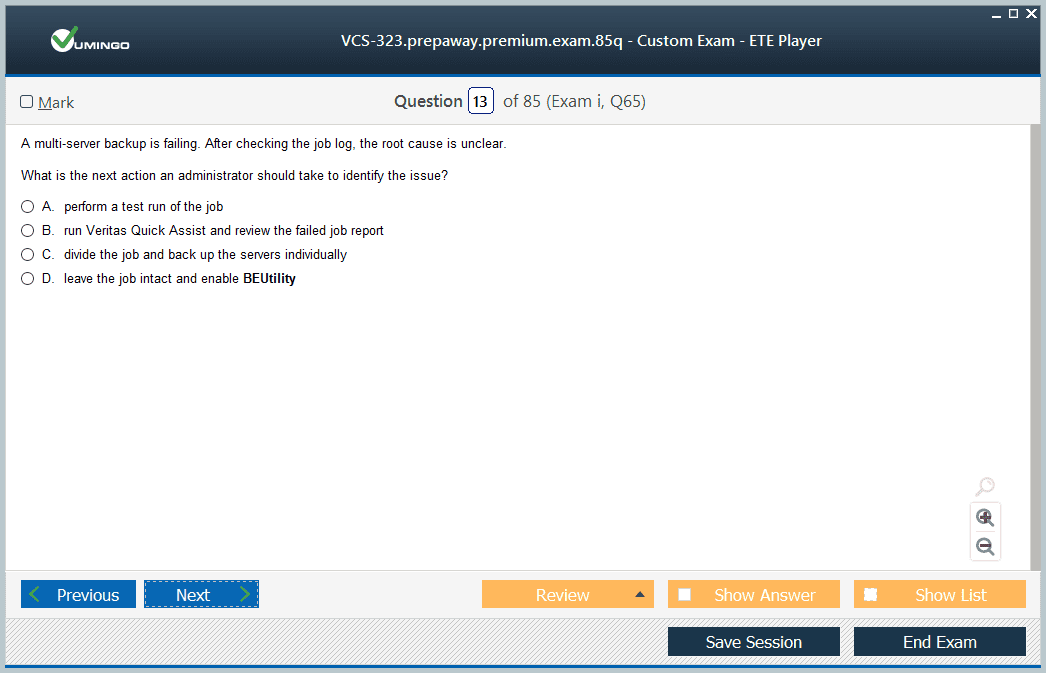
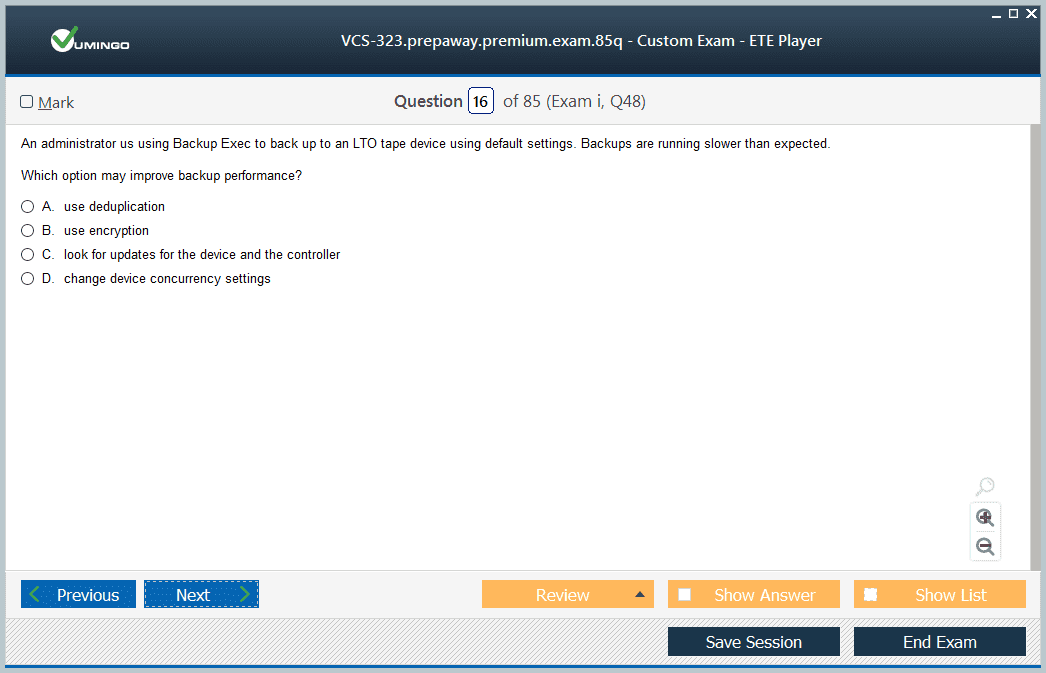
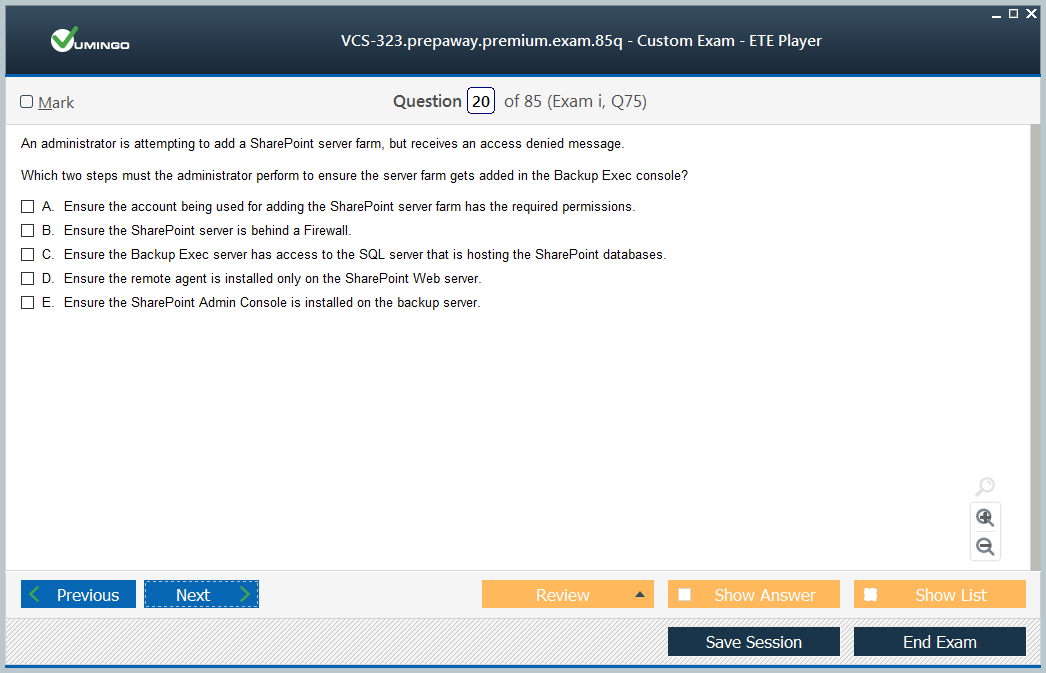
- Latest Questions
- 100% Accurate Answers
- Fast Exam Updates
Last Week Results!
Files coming soon.
All Veritas VCS-323 certification exam dumps, study guide, training courses are Prepared by industry experts. PrepAway's ETE files povide the VCS-323 Administration of Veritas Backup Exec 16 practice test questions and answers & exam dumps, study guide and training courses help you study and pass hassle-free!
Mastering Cluster Resilience and High Availability for Veritas VCS-323
Understanding the architecture of high-availability clusters is fundamental for anyone preparing for the Veritas VCS-323 exam. Candidates should focus on the components that constitute a cluster, including nodes, resource groups, and interconnects that provide redundancy and fault tolerance. A well-designed cluster ensures that applications remain operational even in the event of hardware or software failures. Nodes must communicate reliably to maintain a consistent view of resources and system state. Key architectural considerations include quorum mechanisms, heartbeat monitoring, and distributed decision-making processes, which collectively prevent data inconsistencies and ensure uninterrupted service. Exam candidates should also explore the implications of cluster size, resource dependencies, and network latency on overall system performance.
Resource Lifecycle Management
Managing resources effectively within a cluster requires an understanding of their complete lifecycle, from creation to retirement. Resources can include applications, databases, network services, and storage volumes, each with unique requirements for initialization, monitoring, and failover. Candidates should study how to configure resources, define dependencies, and establish start and stop sequences that maintain service continuity. Resource management policies dictate how clusters respond to failures, ensuring that critical services are restored quickly while non-essential services are deprioritized. Monitoring tools provide real-time insight into resource health, allowing administrators to proactively address performance bottlenecks and prevent cascading failures. A comprehensive grasp of resource lifecycle management ensures reliable operation and reduces downtime in complex clustered environments.
High Availability and Failover Mechanisms
Failover mechanisms are a core component of cluster reliability. Candidates should examine how clusters detect failures and automatically reallocate resources to healthy nodes. Failover strategies can be automatic, where the system responds without administrator intervention, or manual, requiring explicit action. Understanding the triggers that initiate failover is essential, including hardware failures, application crashes, or network partitioning. Recovery processes may involve restarting services, synchronizing data, and restoring network connections to maintain consistency. Handling complex scenarios such as split-brain situations, partial node failures, and multi-tier dependencies requires careful configuration. Mastering these mechanisms enables administrators to design clusters capable of maintaining service availability under diverse operational conditions.
Monitoring and Alerting Frameworks
Continuous monitoring of cluster health is essential for maintaining performance and preemptively addressing potential issues. Candidates should focus on monitoring techniques for node health, resource status, and inter-node communication. Alerting frameworks ensure that administrators receive timely notifications of anomalies, allowing rapid intervention before issues escalate. Effective monitoring requires setting appropriate thresholds, configuring event logs, and establishing notification protocols that reach relevant operational teams. Advanced monitoring may include trend analysis, predictive modeling, and capacity forecasting, which support proactive maintenance and optimize resource allocation. Properly designed monitoring and alerting frameworks enhance the reliability of clustered environments and minimize unplanned downtime.
Configuration and Policy Implementation
Advanced cluster configuration involves defining policies that dictate resource behavior, failover priorities, and interdependencies. Candidates should understand how to establish startup sequences, control recovery actions, and configure node-specific settings to align with operational requirements. Policies ensure that resources are managed consistently and that failover occurs in a controlled, predictable manner. Administrators must also balance performance, security, and compliance considerations when implementing configuration changes. Policy-driven management allows clusters to adapt to changing workloads and supports operational continuity without manual intervention. Mastering configuration and policy implementation is crucial for ensuring both stability and efficiency within a clustered environment.
Troubleshooting and Diagnostic Methodologies
Troubleshooting clustered systems requires a structured approach to identify and resolve underlying problems affecting service availability. Candidates should study methods for analyzing log files, reviewing event histories, and evaluating system metrics to pinpoint the root cause of failures. Common issues include resource contention, network partitioning, misconfigured dependencies, and application-specific failures. Understanding how these factors interact enables administrators to implement corrective measures that prevent recurrence. Root cause analysis not only resolves immediate problems but also informs preventive strategies and system improvements. Effective troubleshooting enhances overall cluster reliability and strengthens the ability to maintain continuous service delivery.
Strategic Planning and Continuous Optimization
Sustaining high-availability cluster performance requires ongoing strategic planning and continuous optimization. Candidates should focus on assessing existing infrastructure, forecasting growth, and aligning cluster capabilities with organizational goals. Continuous optimization includes reviewing performance metrics, refining policies, and adapting configurations to evolving workloads and technology requirements. Administrators should implement a structured process for evaluating system performance, identifying areas for improvement, and applying best practices to enhance resilience and scalability. Incorporating strategic planning into cluster management ensures that environments remain robust, capable of meeting service level objectives, and prepared to handle unforeseen challenges while maintaining operational efficiency.
Advanced Cluster Communication
Effective cluster operation depends on reliable communication between nodes. Candidates preparing for the Veritas VCS-323 exam should understand the mechanisms used for heartbeat signals, node-to-node messaging, and quorum management. Heartbeat networks allow nodes to detect failures quickly and maintain a consistent view of cluster membership. Redundant communication paths prevent single points of failure and ensure that even if one channel is disrupted, nodes can still coordinate to maintain service availability. Understanding message serialization, latency impact, and fault-tolerant communication protocols enables administrators to design clusters that remain robust under varying network conditions.
Resource Dependency and Grouping
Clusters often manage complex applications that rely on multiple interdependent resources. Candidates should focus on how resources are grouped and how dependencies are configured to ensure proper startup and shutdown sequences. Correctly defining dependencies prevents service interruptions and ensures that critical components are available before dependent services are initiated. Administrators must consider both application-specific requirements and infrastructure constraints when organizing resources. By mastering resource dependency management, clusters can achieve predictable behavior during normal operation, failover events, and recovery procedures, reducing downtime and maintaining consistent service delivery.
Policy-Driven Failover Strategies
Implementing policy-driven failover ensures that clusters respond to failures in a controlled, predictable manner. Candidates should study how policies determine failover triggers, order of resource reallocation, and conditions for recovery. Policies may prioritize high-criticality services or designate specific nodes for resource ownership during failover. Understanding the interaction between multiple policies, including preemption rules and escalation procedures, enables administrators to configure clusters that align with business objectives while minimizing service disruption. Mastery of policy-driven failover ensures that clusters respond intelligently to failures, maintaining application continuity and system stability.
Monitoring for Proactive Management
Monitoring is not limited to detecting failures; it is also essential for proactive management and optimization. Candidates should examine how real-time metrics and historical data are used to anticipate potential problems and plan maintenance activities. Monitoring encompasses node health, resource performance, network status, and inter-node communication. Alerting mechanisms provide timely notifications of anomalies, enabling administrators to intervene before minor issues escalate. Advanced monitoring strategies include predictive analytics, trend analysis, and capacity forecasting, which support informed decision-making and long-term cluster reliability. Proactive monitoring minimizes downtime and ensures consistent application performance across the environment.
Advanced Configuration Techniques
Clusters require detailed configuration to meet specific operational requirements. Candidates should focus on techniques for fine-tuning resource behavior, adjusting failover parameters, and optimizing inter-node communication. Advanced configuration also includes customizing thresholds, timeout intervals, and recovery actions to match workload patterns and application criticality. Administrators must consider the trade-offs between responsiveness, resource utilization, and stability when applying configuration changes. Mastering advanced configuration techniques allows clusters to operate efficiently, respond dynamically to failures, and maintain high levels of availability while accommodating evolving operational demands.
Diagnostic and Troubleshooting Approaches
Effective troubleshooting begins with systematic diagnostics to isolate underlying issues. Candidates should explore methods for analyzing logs, reviewing event sequences, and correlating performance metrics to identify root causes. Common cluster issues include network partitioning, resource contention, misconfigured dependencies, and application failures. Understanding the interaction between different cluster components allows administrators to implement corrective actions that prevent recurrence. Continuous diagnostic processes not only resolve immediate problems but also provide insight into potential system improvements. Proficient troubleshooting ensures reliable operation, enhances cluster resilience, and supports consistent service delivery under diverse conditions.
Capacity Planning and Resource Optimization
Sustaining high availability requires ongoing capacity planning and resource optimization. Candidates should focus on assessing current utilization, forecasting growth, and allocating resources effectively to prevent bottlenecks. Capacity planning encompasses node processing power, memory, storage, network bandwidth, and cluster communication channels. Administrators must account for peak loads, planned maintenance, and unexpected spikes in demand. Optimizing resource allocation ensures that clusters maintain performance under varying conditions and that failover mechanisms operate efficiently. Mastery of capacity planning and optimization contributes to scalable, resilient, and high-performing cluster environments capable of meeting organizational objectives.
Integration with Virtualized Environments
Clusters often operate within virtualized infrastructures, presenting additional considerations for high availability. Candidates should study how clusters interact with hypervisors, virtual network configurations, and shared storage systems. Virtualization introduces potential points of failure that require careful management, such as virtual machine migration, snapshot management, and resource contention among multiple instances. Understanding these interactions allows administrators to apply cluster policies effectively, ensuring seamless failover, consistent performance, and minimal service disruption. Integrating clusters with virtualized environments enhances flexibility and supports dynamic, scalable infrastructure deployments.
Security and Compliance Considerations
High-availability clusters must maintain robust security without compromising performance. Candidates should examine how encryption, access control, authentication, and auditing impact cluster operations. Policies should balance security requirements with operational efficiency, ensuring that sensitive data remains protected while maintaining service continuity. Security-conscious configuration and monitoring practices prevent unauthorized access, mitigate vulnerabilities, and ensure compliance with organizational policies. Integrating security into cluster management supports both reliability and regulatory adherence, enabling safe and efficient operation across diverse environments.
Continuous Improvement and Best Practices
Continuous improvement ensures clusters evolve to meet changing business requirements and technological advancements. Candidates should focus on reviewing performance trends, refining policies, and implementing lessons learned from incidents. Best practices include optimizing failover sequences, enhancing monitoring frameworks, and adjusting resource allocation strategies. Regular evaluation of system performance and ongoing refinement of configurations enable clusters to maintain high availability, adapt to workload fluctuations, and address emerging operational challenges. Incorporating continuous improvement into cluster management ensures that systems remain resilient, scalable, and aligned with organizational goals over time.
Orchestration and Automation
Automating cluster operations streamlines management and reduces the potential for human error. Candidates should study orchestration techniques for resource provisioning, failover execution, and monitoring integration. Automation allows clusters to respond dynamically to changing conditions, enforce consistent policies, and maintain service continuity with minimal manual intervention. Orchestration frameworks can coordinate complex actions across multiple nodes, ensuring that resources are allocated efficiently and failures are addressed promptly. Mastery of orchestration and automation enhances operational efficiency, supports scalability, and ensures predictable cluster behavior in dynamic environments.
Multi-Site Coordination and Redundancy
For distributed clusters, coordination across multiple sites ensures uniform service availability and fault tolerance. Candidates should understand strategies for data replication, inter-site failover, and synchronization of monitoring and management systems. Redundancy planning prevents service interruptions in the event of site-specific failures and supports load balancing across locations. Administrators must continuously monitor inter-site performance and adjust policies to maintain consistent application responsiveness. Effective multi-site coordination strengthens cluster resilience, supports disaster recovery strategies, and ensures uninterrupted service for geographically dispersed users.
Performance Tuning and Optimization
Optimizing cluster performance requires continuous tuning of resources, network communication, and application interactions. Candidates should examine techniques for reducing latency, improving throughput, and minimizing resource contention. Performance tuning includes adjusting monitoring intervals, optimizing heartbeat mechanisms, and refining failover procedures to reduce recovery times. By analyzing system metrics and identifying bottlenecks, administrators can apply targeted improvements that enhance efficiency and reliability. Effective performance tuning ensures that clusters deliver consistent, high-quality service even under heavy workloads or complex operational conditions.
Cluster Node Roles and Responsibilities
A deep understanding of node roles is essential for ensuring cluster reliability. Candidates preparing for the Veritas VCS-323 exam should focus on the distinctions between primary and secondary nodes, witness nodes, and failover targets. Each node type has specific responsibilities, from resource ownership and service hosting to monitoring and arbitration. Primary nodes typically manage active workloads, while secondary nodes remain on standby to assume control during failover events. Witness nodes help prevent split-brain scenarios by participating in quorum decisions. By mastering node roles and their interrelations, administrators can design clusters that maintain consistent performance and availability even during complex failure conditions.
Resource Group Structuring
Structuring resource groups effectively is critical for predictable cluster behavior. Candidates should examine how resources with interdependencies are grouped, ensuring that startup and shutdown sequences follow logical order. Proper structuring avoids conflicts, prevents cascading failures, and ensures that dependent applications are always initialized in the correct sequence. Administrators should also consider resource priority and criticality to determine failover order and recovery policies. A well-designed resource group structure allows clusters to respond dynamically to failures while maintaining overall system stability and operational continuity.
Communication and Heartbeat Mechanisms
Reliable inter-node communication forms the backbone of high-availability clusters. Candidates should study the configuration of heartbeat networks, message protocols, and timeout settings. Heartbeat signals are transmitted at regular intervals to indicate node health and availability. Redundant communication paths prevent false failure detection and ensure that clusters continue to operate even when one path fails. Understanding latency, packet loss, and protocol overhead allows administrators to fine-tune communication for optimal performance. Effective heartbeat and communication mechanisms are crucial for fast, accurate failover decisions and maintaining a consistent cluster state.
Dependency Management and Service Sequencing
Managing dependencies is vital for ensuring that resources and services start and stop in the correct order. Candidates should understand how to define dependencies between applications, storage volumes, and network services. Sequencing ensures that dependent services are only started after their prerequisites are active, reducing the risk of application errors or data inconsistencies. Administrators must also manage complex multi-tier dependencies, including database backends, application servers, and frontend services. Mastering dependency management and sequencing allows clusters to maintain predictable, stable operation during normal activity, planned maintenance, and failover events.
Policy-Based Failover Control
Failover policies provide structured guidance for cluster responses to failures. Candidates should study how to configure policies that define triggers, resource allocation, node preference, and escalation procedures. Policies may prioritize critical applications or designate specific nodes to assume control in different scenarios. By implementing policy-driven failover, clusters respond consistently and intelligently to unexpected conditions, minimizing downtime and maintaining application continuity. Understanding the interaction between multiple policies and potential conflicts allows administrators to optimize failover behavior and ensure that clusters behave predictably under stress.
Monitoring, Logging, and Alerting
Continuous monitoring and logging provide visibility into cluster operations. Candidates should focus on the collection and analysis of metrics related to node performance, resource health, and inter-node communication. Logging captures events for diagnostic purposes, while alerting mechanisms notify administrators of deviations from expected behavior. Monitoring should extend beyond failure detection to include proactive performance assessment, trend analysis, and capacity planning. Properly implemented monitoring and alerting frameworks allow administrators to intervene before minor issues escalate and ensure sustained service reliability.
Configuration Management and Optimization
Cluster configuration must balance stability, responsiveness, and performance. Candidates should explore techniques for tuning recovery intervals, setting resource thresholds, and optimizing communication paths. Configuration management includes version control, backup of settings, and the ability to roll back changes if necessary. Administrators must also ensure that configurations support redundancy, prevent conflicts, and align with organizational objectives. Continuous optimization involves reviewing metrics, refining settings, and adapting policies to evolving workloads, ensuring that clusters remain efficient and resilient.
Troubleshooting Complex Scenarios
Clusters often encounter complex failure scenarios requiring structured troubleshooting. Candidates should study methods for isolating issues, correlating log entries, and evaluating system metrics. Common problems include node partitioning, resource contention, misconfigured dependencies, and cascading application failures. Effective troubleshooting identifies root causes and enables administrators to implement corrective actions that prevent recurrence. Incorporating lessons learned into configuration and policy adjustments supports continuous improvement and strengthens overall cluster reliability.
Capacity Planning and Load Management
Proper capacity planning ensures that clusters maintain high availability under varying workloads. Candidates should focus on analyzing current resource utilization, projecting future growth, and allocating nodes, processing power, memory, and storage accordingly. Load management includes distributing resources evenly, prioritizing critical services, and preparing for peak demand. By anticipating resource needs and adjusting allocation dynamically, administrators prevent bottlenecks, reduce latency, and ensure smooth failover operations. Effective capacity planning supports scalable and resilient cluster environments.
Integration with Virtual and Hybrid Environments
Clusters increasingly operate in virtualized and hybrid infrastructures, introducing unique challenges. Candidates should understand the interaction between cluster nodes, hypervisors, virtual networks, and shared storage. Virtual machine migration, dynamic resource allocation, and multi-tenant environments must be considered when designing failover and recovery policies. Integrating clusters with these environments ensures seamless failover, consistent performance, and minimal service disruption. Mastery of virtual and hybrid integration expands cluster flexibility and supports evolving infrastructure strategies.
Security in Cluster Operations
Maintaining security while optimizing availability is essential. Candidates should examine how encryption, access control, authentication, and auditing intersect with cluster management. Policies must protect sensitive data while allowing clusters to perform automated failover and resource allocation. Ensuring that monitoring, logging, and communication channels are secure prevents unauthorized access and maintains compliance. Integrating security best practices into cluster operations preserves both system integrity and high availability.
Continuous Improvement and Operational Excellence
Continuous improvement ensures clusters remain aligned with operational requirements and technological developments. Candidates should focus on evaluating system performance, refining failover policies, optimizing resource allocation, and learning from incidents. Periodic review of configurations, monitoring frameworks, and communication protocols ensures that clusters adapt to changing workloads and evolving threats. Emphasizing operational excellence fosters resilient, scalable, and high-performing cluster environments capable of sustaining long-term organizational objectives.
Cluster Topologies and Network Design
Understanding cluster topologies is critical for designing resilient high-availability systems. Candidates preparing for the Veritas VCS-323 exam should focus on star, ring, and mesh configurations, examining how node interconnections impact communication reliability and failover behavior. Network design must account for latency, redundancy, and fault tolerance, ensuring that heartbeat signals and inter-node messages are delivered consistently. Properly planned topologies reduce the risk of split-brain scenarios, improve recovery times, and support scalable cluster growth. Evaluating the trade-offs between simplicity, performance, and resilience enables administrators to implement network designs that meet operational requirements while maintaining continuous service availability.
Resource Monitoring and Health Checks
Continuous monitoring of resource health is essential for ensuring reliable cluster operations. Candidates should study how to implement automated health checks for applications, services, storage volumes, and network interfaces. These checks provide real-time visibility into system performance and enable proactive intervention before failures impact service delivery. Administrators must configure monitoring intervals, thresholds, and alert mechanisms to detect anomalies accurately without generating excessive noise. Advanced monitoring strategies include trend analysis, capacity planning, and predictive alerts that anticipate potential issues. Mastery of resource monitoring allows clusters to maintain operational stability and enhances administrators' ability to make informed decisions during high-stress conditions.
Failover Planning and Execution
Failover planning encompasses strategies that determine how and when resources transition between nodes. Candidates should examine triggers for failover events, including node crashes, application failures, network interruptions, or hardware faults. Executing failover requires understanding the order in which services restart, dependencies are respected, and data consistency is preserved. Administrators must ensure that failover actions are deterministic, predictable, and minimize downtime. Exploring both automatic and manual failover mechanisms provides insight into designing clusters capable of handling complex scenarios while maintaining service continuity. By mastering failover planning, candidates can create robust systems resilient to both anticipated and unexpected disruptions.
Resource Dependency Analysis
Resource dependency analysis is fundamental for preventing cascading failures and maintaining operational continuity. Candidates should focus on identifying relationships among applications, databases, network interfaces, and storage volumes. Properly defined dependencies ensure that essential services start before dependent components and stop in reverse order during maintenance or failure events. Administrators must evaluate multi-tier architectures, considering how failures in one component affect downstream services. By analyzing and managing dependencies, clusters operate predictably, recover quickly from failures, and avoid scenarios where one failed resource triggers multiple service outages.
Policy Implementation and Governance
Policy implementation establishes rules for resource allocation, failover behavior, and recovery procedures. Candidates should study how policies define critical resource prioritization, node preference during failover, and escalation sequences for repeated failures. Governance frameworks ensure that clusters adhere to operational standards, enforce best practices, and maintain alignment with organizational objectives. Administrators must design policies that balance availability, performance, and compliance considerations, ensuring consistent and repeatable behavior across all cluster operations. Mastering policy implementation enhances predictability, reduces administrative overhead, and ensures high service reliability under diverse operating conditions.
Advanced Configuration Techniques
Advanced configuration techniques allow clusters to handle complex workloads and dynamic environments efficiently. Candidates should focus on customizing startup sequences, adjusting monitoring thresholds, fine-tuning recovery intervals, and optimizing network communication paths. Configuration management also involves maintaining backups, version control, and rollback procedures to prevent errors from affecting operational stability. Administrators must consider both resource-specific requirements and overarching cluster behavior when applying changes. Mastering advanced configuration ensures that clusters remain flexible, efficient, and capable of maintaining high availability despite evolving operational demands.
Diagnostic Strategies and Troubleshooting
Effective diagnostics are essential for resolving issues quickly and maintaining cluster integrity. Candidates should study methods for correlating log entries, analyzing event sequences, and evaluating performance metrics to identify root causes. Common challenges include node partitioning, misconfigured dependencies, resource contention, and communication failures. A structured approach to troubleshooting allows administrators to implement targeted corrective actions, prevent recurrence, and improve overall cluster resilience. Understanding these strategies enables proactive problem-solving, reduces downtime, and maintains continuous service delivery under varied operational conditions.
Capacity Management and Load Balancing
Capacity management ensures that clusters can handle fluctuating workloads while maintaining high performance. Candidates should focus on evaluating CPU, memory, storage, and network utilization across nodes. Load balancing distributes workloads efficiently, preventing overutilization of specific nodes and minimizing latency. Administrators must anticipate peak usage, planned maintenance, and unexpected demand surges to allocate resources effectively. Proper capacity management enhances cluster responsiveness, ensures predictable failover behavior, and supports long-term scalability and stability.
Integration with Cloud and Hybrid Systems
Clusters increasingly operate in cloud and hybrid environments, introducing additional considerations for resource management and failover. Candidates should understand interactions between nodes, virtual networks, storage abstractions, and cloud services. Migration, elasticity, and multi-tenant environments require careful planning to maintain high availability. Integration strategies should ensure seamless failover, consistent performance, and minimal service disruption. Mastery of cloud and hybrid integration allows administrators to extend cluster capabilities, support dynamic workloads, and maintain operational efficiency in complex infrastructures.
Security and Compliance in Cluster Operations
Security is a critical aspect of high-availability cluster management. Candidates should study how encryption, authentication, access control, and auditing intersect with cluster operations. Policies must protect sensitive data while allowing clusters to perform automated failover and resource allocation. Administrators must balance security requirements with operational efficiency to maintain availability without introducing unnecessary risk. Integrating security and compliance into cluster operations ensures both resilience and adherence to organizational policies, supporting safe and reliable service delivery.
Orchestration, Automation, and Scalability
Orchestration and automation enhance cluster management by reducing manual intervention, minimizing human error, and ensuring consistent execution of policies. Candidates should explore how automated workflows handle resource provisioning, failover, monitoring, and recovery. Scalable orchestration frameworks support multiple nodes, distributed sites, and complex dependencies. Administrators can configure dynamic responses to changing workloads, optimize resource allocation, and maintain predictable behavior under stress. Mastery of orchestration and automation ensures operational efficiency, high availability, and consistent performance across diverse environments.
Performance Optimization and Continuous Improvement
Optimizing cluster performance involves continuous analysis of resource utilization, failover efficiency, and communication pathways. Candidates should study techniques for tuning recovery times, reducing latency, and improving throughput. Continuous improvement includes reviewing incident history, refining policies, and adjusting configurations to meet evolving workloads. Administrators must balance performance enhancements with system stability, ensuring that optimization does not compromise reliability. A commitment to continuous improvement fosters resilient, high-performing clusters capable of supporting long-term organizational objectives.
High-Availability Strategies
Developing effective high-availability strategies is a cornerstone for candidates preparing for the Veritas VCS-323 exam. Understanding how to maintain uninterrupted service despite hardware failures, application crashes, or network disruptions is essential. Strategies encompass proactive monitoring, resource prioritization, failover planning, and continuous optimization. Administrators must evaluate which applications are mission-critical and design clusters to ensure those services are always available. By combining redundancy, predictive monitoring, and policy-driven responses, high-availability strategies provide both resilience and operational predictability, allowing organizations to sustain consistent service delivery even under adverse conditions.
Node Communication and Heartbeat Networks
Reliable communication between cluster nodes is fundamental for synchronized operation. Candidates should focus on configuring heartbeat networks, ensuring redundant communication paths, and optimizing message protocols. Heartbeat signals indicate node health and cluster membership, allowing the system to detect failures and initiate failover promptly. Administrators need to consider latency, network congestion, and potential communication failures when designing heartbeat mechanisms. Mastery of node communication ensures that clusters can react swiftly and accurately to disruptions, reducing downtime and preventing false failure detection that could compromise system stability.
Resource Grouping and Dependency Mapping
Effective clustering requires careful grouping of resources and mapping dependencies. Candidates should examine techniques for organizing applications, services, storage volumes, and network interfaces to maintain operational coherence. Dependencies ensure that resources start and stop in the correct sequence, preventing service interruptions or cascading failures. Administrators must assess multi-tier application architectures, considering how upstream failures impact downstream services. Proper grouping and dependency mapping enable clusters to perform coordinated failover, maintain data consistency, and ensure reliable service restoration in both planned and unplanned scenarios.
Policy-Driven Failover and Recovery
Policy-driven failover defines how resources transition between nodes during failures. Candidates should study methods for configuring policies that prioritize critical services, designate node ownership, and implement escalation procedures. Policies must account for repeated failures, preemption, and recovery timing to ensure predictable cluster behavior. Administrators should balance responsiveness with stability, preventing unnecessary failovers that could disrupt service. Mastery of policy-driven failover allows clusters to respond intelligently to dynamic conditions, maintain application continuity, and minimize operational impact during incidents.
Monitoring, Alerts, and Proactive Management
Continuous monitoring is critical for anticipating and addressing potential issues before they affect service delivery. Candidates should focus on configuring metrics collection for resource health, node performance, network latency, and storage utilization. Alerting mechanisms provide timely notifications of anomalies, enabling proactive intervention. Advanced monitoring strategies incorporate trend analysis, predictive alerts, and performance benchmarking. Proactive management allows administrators to adjust configurations, redistribute workloads, and resolve potential problems before they escalate, ensuring clusters maintain high availability and optimal performance over time.
Configuration Management and Optimization
Clusters rely on meticulous configuration to ensure consistent behavior under varying conditions. Candidates should explore techniques for fine-tuning resource thresholds, recovery intervals, monitoring sensitivity, and communication paths. Configuration management includes maintaining version control, documenting changes, and implementing rollback procedures. Optimizing cluster settings requires balancing performance, reliability, and operational flexibility. By mastering configuration management, administrators can ensure that clusters remain robust, adaptable, and capable of handling complex workloads without compromising service continuity.
Diagnostic and Troubleshooting Frameworks
Effective troubleshooting relies on systematic diagnostics to identify and resolve issues efficiently. Candidates should study approaches for analyzing logs, correlating events, and evaluating performance metrics to pinpoint root causes. Common issues include network partitioning, resource contention, dependency misconfigurations, and application failures. A structured troubleshooting framework enables administrators to implement corrective actions, prevent recurrence, and enhance overall cluster resilience. By integrating diagnostics into regular operations, clusters can maintain consistent performance and minimize the impact of unplanned disruptions.
Capacity Planning and Resource Allocation
Ensuring that clusters handle workloads efficiently requires strategic capacity planning. Candidates should focus on assessing CPU, memory, storage, and network utilization, forecasting future demand, and allocating resources appropriately. Load balancing strategies distribute workloads evenly, preventing bottlenecks and ensuring that failover operations are effective. Administrators must consider peak usage periods, maintenance schedules, and unexpected demand spikes when planning capacity. Proper resource allocation supports scalability, maintains performance under stress, and strengthens the overall resilience of the cluster environment.
Integration with Virtualized and Hybrid Infrastructures
Clusters often operate within virtualized or hybrid environments, introducing additional considerations for high availability. Candidates should examine interactions with hypervisors, virtual networks, and shared storage systems. Virtual machine migration, resource contention, and multi-tenant environments require careful planning to ensure seamless failover and minimal service disruption. Understanding these interactions allows administrators to implement clusters that maintain performance, support dynamic workloads, and integrate with broader infrastructure strategies. Effective integration enhances operational flexibility, scalability, and reliability across diverse environments.
Security and Compliance in Clusters
Security is a vital component of cluster management. Candidates should study how encryption, authentication, access control, and auditing affect high-availability operations. Policies must protect sensitive data while allowing clusters to perform automated failover, monitoring, and recovery. Administrators need to balance security requirements with operational efficiency to maintain availability without introducing unnecessary risk. By incorporating security and compliance considerations into cluster management, systems remain resilient, reliable, and aligned with organizational standards.
Automation, Orchestration, and Workflow Management
Automation and orchestration improve cluster efficiency by reducing manual intervention, minimizing errors, and ensuring consistent execution of policies. Candidates should explore how workflows automate resource provisioning, failover execution, monitoring integration, and recovery processes. Orchestration supports coordination across multiple nodes, sites, and complex dependencies, enabling dynamic responses to changing workloads. Mastery of automation and orchestration allows administrators to maintain high availability, optimize resource utilization, and implement scalable, resilient systems capable of handling evolving operational demands.
Performance Tuning and Continuous Improvement
Optimizing cluster performance involves ongoing analysis of workloads, communication pathways, and failover efficiency. Candidates should study techniques for minimizing latency, enhancing throughput, and reducing resource contention. Continuous improvement includes reviewing historical performance, refining policies, and adjusting configurations to address emerging challenges. Administrators must ensure that performance tuning does not compromise system stability, maintaining both efficiency and reliability. A focus on continuous improvement allows clusters to evolve with organizational needs, supporting sustained high availability and optimal service delivery.
Multi-Site and Disaster Recovery Considerations
Clusters deployed across multiple sites require careful planning for disaster recovery and inter-site coordination. Candidates should focus on strategies for replicating data, synchronizing resources, and implementing failover across geographically distributed nodes. Redundant pathways, site-specific policies, and coordinated monitoring ensure that services remain available even during site-level disruptions. Administrators must continuously test recovery procedures, evaluate inter-site performance, and refine policies to maintain resilience. Effective multi-site planning strengthens disaster recovery capabilities, enhances system reliability, and ensures uninterrupted service for critical applications.
Advanced Cluster Architectures
Understanding advanced cluster architectures is critical for designing resilient, high-performing systems. Candidates preparing for the Veritas VCS-323 exam should explore configurations that optimize fault tolerance, resource utilization, and scalability. Multi-tier clusters, multi-site deployments, and hybrid infrastructures introduce complexities that require careful planning. Administrators must evaluate node placement, redundancy strategies, and communication pathways to prevent single points of failure. Advanced architectures also consider resource interdependencies, failover sequences, and workload distribution to ensure clusters operate predictably under varying conditions. Mastery of these architectures allows organizations to achieve continuous service availability while accommodating growth and evolving operational requirements.
Resource Allocation and Prioritization
Effective resource allocation ensures that mission-critical applications receive priority access to computing, storage, and network resources. Candidates should focus on strategies for defining resource criticality, establishing failover hierarchies, and managing dependencies. Administrators must balance competing demands while preventing resource contention that could degrade performance. By implementing dynamic allocation policies, clusters can respond intelligently to changing workloads, maintain service continuity, and optimize overall system efficiency. Resource prioritization also involves continuous monitoring and adjustment to align with organizational objectives and maintain high availability.
High-Precision Monitoring and Predictive Analytics
Monitoring is central to cluster reliability, but advanced environments benefit from high-precision monitoring and predictive analytics. Candidates should study techniques for tracking detailed metrics, identifying patterns, and forecasting potential failures. Predictive analytics use historical data to anticipate resource bottlenecks, communication issues, and service degradation. Administrators can leverage these insights to adjust configurations proactively, optimize failover policies, and prevent service interruptions. High-precision monitoring enables a proactive approach to cluster management, minimizing downtime and ensuring sustained operational performance.
Failover and Recovery Optimization
Optimizing failover and recovery processes reduces downtime and ensures consistent service continuity. Candidates should explore approaches for fine-tuning recovery intervals, sequencing dependent resources, and minimizing service disruption during transitions. Administrators must also consider the impact of simultaneous failures, resource contention, and multi-site coordination. Advanced optimization includes balancing speed with stability, ensuring that rapid failover does not compromise resource integrity or data consistency. Mastery of failover and recovery optimization enhances cluster resilience and provides predictable, reliable system behavior under diverse failure scenarios.
Dependency Analysis and Service Coordination
Complex clusters often involve multiple interdependent applications and services. Candidates should focus on analyzing these dependencies, defining explicit startup and shutdown sequences, and coordinating service interactions. Administrators must account for both direct and indirect dependencies, including storage layers, network services, and application backends. Proper dependency analysis prevents cascading failures, ensures data consistency, and supports seamless failover operations. Coordinating services effectively also simplifies troubleshooting and improves the predictability of cluster behavior during planned maintenance or unexpected disruptions.
Policy-Driven Management and Governance
Policies define the rules governing cluster behavior, including failover triggers, resource allocation, escalation procedures, and node preferences. Candidates should examine the design and implementation of policy frameworks that enforce operational standards and maintain alignment with organizational objectives. Administrators must ensure policies accommodate both normal operation and failure scenarios, providing consistency and repeatability in cluster responses. Policy-driven management reduces human error, enforces best practices, and enhances overall system reliability, ensuring clusters respond intelligently to dynamic conditions.
Configuration and Version Control
Maintaining consistent configuration across cluster nodes is critical for predictable behavior. Candidates should explore methods for version control, backup, rollback, and auditing of cluster configurations. Administrators must ensure that changes are implemented systematically, documented accurately, and tested before deployment. Configuration management also involves tuning parameters such as monitoring intervals, recovery thresholds, communication timeouts, and resource limits. Effective configuration and version control provide stability, facilitate troubleshooting, and support continuous improvement efforts.
Troubleshooting Complex Failure Scenarios
Clusters encounter a range of failure scenarios that require structured troubleshooting. Candidates should focus on identifying root causes, correlating log data, analyzing event sequences, and applying corrective actions. Typical issues include network partitioning, misconfigured dependencies, resource contention, and cascading service failures. Administrators must develop strategies for isolating problems, implementing temporary workarounds, and applying permanent solutions. Comprehensive troubleshooting ensures minimal disruption, preserves data integrity, and enhances long-term cluster resilience.
Capacity Planning and Dynamic Load Management
Clusters must accommodate varying workloads while maintaining performance and availability. Candidates should study approaches for assessing current utilization, forecasting growth, and allocating resources dynamically. Load management distributes workloads evenly, prioritizes critical services, and mitigates bottlenecks. Administrators must plan for peak demand, maintenance windows, and unexpected load surges. Dynamic capacity planning ensures clusters remain scalable, responsive, and capable of maintaining high availability under fluctuating conditions, supporting both short-term operational needs and long-term growth objectives.
Integration with Hybrid and Virtual Environments
Clusters increasingly operate within hybrid and virtualized infrastructures, presenting additional challenges. Candidates should understand the interactions between physical nodes, virtual machines, hypervisors, and cloud services. Considerations include resource migration, latency, redundancy, and failover across virtual environments. Integration strategies must ensure seamless operation, predictable failover, and consistent performance. Administrators skilled in hybrid and virtual integration can leverage these environments for flexible resource allocation, improved efficiency, and extended cluster capabilities while maintaining high availability.
Security and Compliance Considerations
Securing clusters involves protecting data, communications, and operational processes while preserving availability. Candidates should explore encryption, access controls, authentication mechanisms, and auditing strategies. Policies must balance operational efficiency with security requirements, ensuring automated failover and monitoring continue without introducing vulnerabilities. Compliance with organizational standards and regulatory requirements is integral to cluster operations. Integrating security considerations ensures that high availability is maintained alongside robust protection of critical resources.
Orchestration, Automation, and Operational Efficiency
Automation and orchestration streamline cluster management by reducing manual tasks, improving consistency, and optimizing workflow execution. Candidates should study how automated processes handle resource provisioning, monitoring, failover, and recovery. Orchestration coordinates activities across nodes, sites, and dependencies, enabling responsive, scalable, and efficient operations. Administrators can implement dynamic adjustments to workloads, optimize resource utilization, and ensure consistent execution of policies. Mastery of orchestration and automation enhances operational efficiency, reliability, and resilience across complex environments.
Performance Tuning and Continuous Optimization
Maintaining optimal cluster performance requires ongoing tuning and analysis. Candidates should examine strategies for minimizing latency, enhancing throughput, and reducing contention among resources. Continuous optimization involves reviewing performance metrics, adjusting configurations, and refining policies to accommodate evolving workloads. Administrators must balance performance improvements with system stability, ensuring clusters remain resilient and reliable. Continuous optimization supports sustained high availability, predictable failover behavior, and long-term operational excellence.
Multi-Site Coordination and Disaster Recovery
Clusters deployed across multiple locations require careful planning for disaster recovery and inter-site coordination. Candidates should study replication strategies, resource synchronization, and failover procedures across distributed sites. Redundant pathways, site-specific policies, and coordinated monitoring ensure uninterrupted service even during site-level disruptions. Administrators must regularly test recovery plans, evaluate inter-site performance, and refine strategies to maintain resilience. Effective multi-site coordination enhances disaster recovery capabilities and supports uninterrupted availability for critical applications.
Comprehensive Cluster Strategy
A comprehensive cluster strategy requires understanding the interrelation of resources, nodes, and policies to maintain high availability. Candidates preparing for the Veritas VCS-323 exam should focus on designing strategies that encompass proactive monitoring, failover planning, capacity management, and policy enforcement. Effective strategies integrate resource prioritization, dependency mapping, and predictive analytics to anticipate failures before they impact service continuity. Administrators must consider both hardware and software components, evaluating redundancy, communication pathways, and recovery mechanisms. By implementing a holistic approach, clusters operate predictably, resiliently, and efficiently, ensuring consistent service delivery under varying operational conditions.
Advanced Resource Monitoring and Analytics
Advanced resource monitoring goes beyond basic health checks to include real-time performance metrics, trend analysis, and predictive alerts. Candidates should explore techniques for tracking CPU, memory, network, and storage utilization at granular levels. Monitoring frameworks must balance sensitivity with noise reduction, ensuring that alerts are actionable and meaningful. Predictive analytics leverage historical data to forecast potential bottlenecks, identify emerging risks, and guide proactive adjustments. Administrators skilled in advanced monitoring can preempt failures, optimize resource distribution, and maintain high performance while minimizing downtime across the cluster.
Failover Optimization Techniques
Failover optimization focuses on reducing downtime while preserving service integrity during transitions. Candidates should examine methods for sequencing resource recovery, adjusting thresholds for failover triggers, and managing dependencies across complex multi-tier applications. Optimization involves balancing speed and stability, ensuring that rapid failover does not compromise data consistency or overload remaining nodes. Administrators must also plan for simultaneous or cascading failures, implementing policies that prioritize mission-critical services. Mastering failover optimization allows clusters to respond dynamically, maintain service continuity, and minimize the impact of unexpected disruptions.
Resource Dependency and Coordination
Resource dependency and coordination ensure that cluster operations are predictable and reliable. Candidates should study the mapping of interdependent applications, services, and storage layers, ensuring that critical resources are available before dependent services start. Administrators must manage both explicit and implicit dependencies, accounting for complex multi-tier architectures. Effective coordination prevents cascading failures, reduces recovery time, and enhances operational predictability. By mastering dependency analysis, clusters maintain integrity and continuity, even in intricate and high-demand environments.
Policy Design and Enforcement
Policies govern how clusters respond to operational events, manage resource allocation, and execute recovery procedures. Candidates should focus on designing policies that enforce node preferences, escalation sequences, and resource prioritization. Administrators must balance automated policy execution with oversight to prevent unnecessary failovers or resource conflicts. Policies also facilitate compliance with organizational standards and operational best practices. Properly designed and enforced policies ensure that clusters maintain high availability, respond consistently to failures, and operate efficiently under dynamic conditions.
Configuration Management and Consistency
Configuration management maintains consistency across nodes and resources, supporting predictable cluster behavior. Candidates should study techniques for version control, configuration backups, rollback procedures, and systematic documentation. Administrators must ensure that changes are tested, validated, and deployed methodically to avoid inconsistencies or errors that could compromise cluster operations. Configuration management also includes tuning performance parameters, adjusting monitoring sensitivity, and optimizing communication settings. Mastery in this area ensures stability, simplifies troubleshooting, and enhances the reliability of the cluster over time.
Troubleshooting and Problem Resolution
Effective troubleshooting identifies root causes, mitigates impacts, and restores services rapidly. Candidates should explore methods for analyzing logs, correlating events, and isolating failures in complex environments. Common challenges include network partitioning, resource contention, misconfigured dependencies, and cascading service interruptions. Administrators must apply structured approaches to resolve issues efficiently while preventing recurrence. Comprehensive problem resolution enhances operational continuity, supports predictive maintenance, and strengthens overall cluster resilience.
Capacity Planning and Workload Management
Capacity planning and workload management ensure that clusters handle peak demand and evolving workloads without degradation. Candidates should focus on evaluating current utilization, forecasting future requirements, and implementing dynamic resource allocation. Load balancing strategies distribute workloads evenly, reduce bottlenecks, and prioritize critical applications during high-demand periods. Administrators must plan for unexpected spikes, maintenance activities, and resource failures to maintain high availability. Proper capacity planning guarantees clusters remain scalable, responsive, and capable of delivering consistent performance across all operational conditions.
Hybrid Environment and Virtualization Integration
Clusters increasingly operate within hybrid and virtualized infrastructures, introducing additional considerations. Candidates should study interactions between physical nodes, virtual machines, hypervisors, and cloud services. Integration strategies must ensure that failover, monitoring, and recovery procedures function seamlessly across virtualized layers. Administrators must account for resource migration, network latency, and multi-tenant environments while maintaining performance and high availability. Effective integration allows clusters to leverage flexible infrastructure options while ensuring resilience and operational consistency.
Security, Compliance, and Operational Integrity
Securing cluster operations is critical to maintaining both availability and integrity. Candidates should explore encryption, authentication, access control, and auditing mechanisms as part of comprehensive cluster management. Policies must balance operational efficiency with security requirements, ensuring automated processes such as failover and resource monitoring remain functional without introducing vulnerabilities. Compliance with organizational and regulatory standards is essential. Incorporating security measures enhances cluster reliability, protects sensitive data, and ensures safe, continuous service delivery.
Orchestration, Automation, and Efficiency
Automation and orchestration streamline cluster management, reducing manual intervention and promoting consistency. Candidates should study workflows that manage resource provisioning, monitoring, failover, and recovery tasks automatically. Orchestration coordinates actions across nodes, sites, and dependencies, enabling adaptive responses to changing workloads and operational conditions. Administrators can implement dynamic policies, optimize resource utilization, and ensure consistent behavior across distributed environments. Mastery of automation and orchestration enhances operational efficiency, reduces human error, and strengthens high availability.
Performance Tuning and Continuous Improvement
Performance tuning involves optimizing communication, resource allocation, and failover processes to maintain efficiency. Candidates should focus on minimizing latency, maximizing throughput, and reducing resource contention. Continuous improvement incorporates performance reviews, policy adjustments, and configuration refinements to address evolving operational requirements. Administrators must ensure that tuning activities maintain stability and reliability. Emphasizing continuous improvement supports long-term cluster performance, predictable failover behavior, and operational excellence.
Disaster Recovery and Multi-Site Resilience
Clusters spanning multiple locations require careful disaster recovery planning. Candidates should examine replication strategies, inter-site synchronization, and failover mechanisms to maintain service during site-level disruptions. Redundant pathways, site-specific policies, and coordinated monitoring ensure high availability and operational continuity. Administrators must regularly test recovery procedures, evaluate inter-site performance, and update strategies as workloads evolve. Multi-site resilience strengthens disaster recovery capabilities and supports uninterrupted access to critical services under a wide range of conditions.
Strategic Cluster Management
Strategic cluster management combines all operational facets—architecture, resource allocation, monitoring, failover, policies, configuration, troubleshooting, capacity planning, hybrid integration, security, orchestration, performance tuning, and disaster recovery—into a coherent framework. Candidates should focus on developing management practices that optimize availability, efficiency, and reliability. Administrators implement proactive policies, continuously monitor performance, and refine configurations to anticipate and mitigate risks. Strategic management ensures clusters deliver uninterrupted service, adapt to changing demands, and maintain operational excellence over the long term.
Comprehensive Cluster Resilience
Achieving comprehensive cluster resilience requires integrating architecture design, resource management, failover mechanisms, and operational governance into a unified framework. Candidates preparing for the Veritas VCS-323 exam should focus on strategies that ensure continuous service availability even under complex failure conditions. Administrators must evaluate node distribution, redundancy configurations, communication pathways, and interdependent resources. Resilient clusters anticipate failures, maintain operational integrity, and recover predictably, providing uninterrupted access to critical applications and data. Understanding the interplay between components enables administrators to design clusters that balance performance, reliability, and scalability effectively.
Cluster resilience extends beyond hardware and network redundancies. It encompasses software orchestration, automated monitoring, and predictive resource allocation to address potential points of failure before they impact service. For example, administrators must consider how an unexpected spike in workload could strain one node and propagate delays across dependent services. By analyzing historical performance data and current system metrics, clusters can implement adaptive measures such as dynamic load balancing, proactive failover triggers, and temporary resource redistribution. These strategies reduce downtime risk and support consistent user experiences.
Another dimension of cluster resilience is fault isolation. Administrators must design clusters to contain failures within specific nodes or subsystems without cascading to the broader environment. This involves segmenting resources, establishing redundancy paths, and implementing intelligent routing mechanisms for network and storage traffic. When combined with automated alerting and incident response workflows, fault isolation ensures that operational disruptions are minimized and recovery times are reduced. Candidates should understand both the conceptual frameworks for fault containment and the practical steps for implementing them in complex environments.
Communication between nodes is critical for maintaining cluster stability. Synchronous replication, heartbeat monitoring, and quorum-based decision systems help nodes remain aware of each other’s status and respond rapidly to failures. Administrators must configure these systems to balance responsiveness with network overhead, ensuring that excessive monitoring does not impair cluster performance. Additionally, communication protocols should account for latency variations, packet loss, and potential network partitions, providing robust mechanisms for data consistency and coordinated action. Effective communication design is essential for predictable cluster behavior under stress.
Cluster resilience also relies on systematic recovery procedures. Administrators should define and test recovery workflows that include resource reallocation, service restart sequences, and integrity verification of applications and data. Automated recovery processes reduce human error and ensure that responses occur within predefined timelines. Testing these procedures under simulated failure conditions provides insights into potential gaps and allows teams to refine configurations for maximum reliability. Candidates should be familiar with both planning and validation aspects of recovery strategies to ensure practical resilience.
Integration of monitoring and analytics enhances resilience by providing continuous visibility into cluster health. Real-time dashboards, alert thresholds, and predictive analytics allow administrators to detect anomalies, resource contention, or emerging failures before they impact critical services. Predictive insights, generated from historical patterns and machine learning algorithms, guide decisions on workload distribution, maintenance windows, and failover strategies. This data-driven approach allows for proactive management rather than reactive troubleshooting, significantly improving uptime and reliability.
Resource prioritization is another key element. Not all services have equal criticality, and clusters must allocate resources dynamically to maintain performance for high-priority applications. Administrators implement policies to throttle non-critical workloads, adjust memory and CPU allocations, and ensure network bandwidth is reserved for essential services. Effective prioritization maintains service quality even during partial failures or high-demand periods, preventing minor disruptions from escalating into major outages.
Redundancy strategies form the foundation of resilience. Administrators must design clusters with multiple layers of redundancy, including hardware, network paths, storage replication, and virtualized nodes. This multi-layered approach ensures that a single failure does not compromise overall availability. Redundancy planning involves identifying potential single points of failure, designing failover mechanisms, and regularly validating that redundant systems are operational and properly synchronized.
Operational governance reinforces resilience by providing structured policies and procedures for maintenance, updates, and incident response. Administrators establish rules for patch management, configuration changes, and escalation paths to maintain consistency and predictability. Governance frameworks reduce human error, ensure compliance with internal standards, and create a disciplined environment for ongoing cluster management. Candidates should understand how operational governance supports both proactive and reactive resilience measures.
Automation enhances resilience by enabling clusters to respond rapidly and consistently to failures. Automated orchestration can handle node restarts, resource reallocation, service failover, and dependency resolution without manual intervention. By defining policy-driven automation rules, administrators reduce response times and maintain consistent operations even during unexpected events. Automation also allows for controlled simulations and testing, helping teams validate resilience strategies and refine workflows continuously.
Capacity planning is essential for sustained resilience. Administrators must forecast workloads, monitor utilization, and ensure that clusters have sufficient headroom to handle spikes in demand. Effective capacity planning prevents resource exhaustion, avoids performance degradation, and supports seamless scaling. By aligning resource allocation with expected operational requirements, administrators maintain resilience under variable conditions and ensure that clusters continue to meet service level expectations.
Clusters operating across hybrid or virtualized environments introduce additional complexity. Administrators must manage resource allocation, failover, and synchronization across physical and virtual layers. Integration strategies should address latency, data consistency, and cross-layer dependencies. Properly managed hybrid clusters benefit from increased flexibility and scalability while maintaining high availability, provided that administrators carefully plan for inter-layer interactions and potential points of failure.
Security is a vital component of resilience. Administrators must implement encryption, access controls, authentication mechanisms, and audit trails to protect cluster resources from unauthorized access or tampering. Security policies should be integrated with operational procedures to ensure that automated monitoring, failover, and maintenance processes do not introduce vulnerabilities. By combining security with operational resilience, clusters can maintain service continuity without compromising integrity or compliance requirements.
Disaster recovery planning extends resilience to multi-site deployments. Administrators must implement replication strategies, synchronized backups, and coordinated failover procedures across geographic locations. Multi-site clusters must account for latency, network partitions, and varying infrastructure capabilities to ensure continuous service delivery. Testing and validation of disaster recovery processes are critical to confirm that services can be restored quickly and consistently during site-level failures or catastrophic events.
Strategic operational management integrates all aspects of resilience into a coherent framework. Administrators implement policies, monitor system health, analyze predictive metrics, and refine configurations to anticipate risks and optimize performance. By maintaining a holistic view of cluster operations, teams can ensure high availability, operational efficiency, and adaptability under dynamic conditions. Strategic management allows organizations to leverage cluster capabilities fully, providing predictable and reliable access to critical applications and data.
Continuous improvement reinforces cluster resilience by analyzing incidents, refining processes, and updating configurations. Lessons learned from operational experience inform policy adjustments, monitoring enhancements, and automation improvements. By adopting a culture of continuous evaluation and optimization, administrators ensure that clusters evolve to meet emerging challenges and maintain high service levels over time.
In summary, comprehensive cluster resilience encompasses architecture, resource management, monitoring, failover optimization, dependency mapping, policy governance, configuration standardization, troubleshooting, capacity planning, hybrid integration, security, automation, disaster recovery, and strategic operational management. Candidates preparing for the Veritas VCS-323 exam should develop expertise across these dimensions to design, implement, and maintain clusters that deliver continuous, reliable, and scalable service under a wide range of operational conditions. This holistic approach ensures that clusters not only survive failures but adapt, recover, and maintain optimal performance consistently.
Conclusion
Achieving mastery of Veritas cluster management through the VCS-323 framework requires a holistic understanding of both the technical components and operational strategies that underpin high availability. The exam emphasizes not just the deployment of cluster systems but also the sustainable management and optimization of these environments to ensure continuous service delivery under varying conditions. Candidates are expected to demonstrate proficiency across a spectrum of concepts, including architecture design, resource management, monitoring, failover, dependency mapping, policy enforcement, configuration management, and disaster recovery.
A cornerstone of cluster reliability lies in comprehensive architecture planning. Administrators must be adept at designing nodes, networks, and storage systems that provide redundancy, fault isolation, and predictable failover behavior. This planning involves evaluating inter-node communication, replication mechanisms, and distributed resource allocation strategies that ensure no single point of failure compromises operational continuity. A well-designed cluster is not only resilient to component failures but also capable of dynamic adaptation under high-load or unexpected scenarios.
Resource management forms another critical pillar. The ability to dynamically allocate CPU, memory, storage, and network bandwidth according to service priority is essential to maintaining consistent performance. Administrators must balance competing workloads, implement prioritization policies, and prevent contention or bottlenecks. Effective resource management is closely tied to monitoring and predictive analytics, which enable proactive adjustments to prevent service degradation. Candidates must understand how to integrate real-time metrics with historical analysis to anticipate issues and optimize performance preemptively.
Failover optimization and dependency mapping are central to maintaining uninterrupted service. Clusters often support interdependent applications where the failure of one service can cascade into broader outages if not properly managed. Administrators must sequence startup and shutdown operations, define recovery intervals, and implement policies that prioritize mission-critical services. Mastery of failover sequences ensures that clusters respond predictably to failures, minimizing downtime and maintaining data integrity. Dependency mapping further enhances predictability by identifying both direct and indirect relationships between applications, storage, and network resources.
Governance, policy enforcement, and configuration standardization establish a disciplined operational environment. By maintaining consistent configurations, version control, and auditing procedures, administrators reduce the risk of human error and unexpected failures. Policies dictate how clusters respond to failures, handle maintenance activities, and prioritize resources under varying workloads. Effective governance ensures that clusters operate in a controlled, repeatable manner, supporting both reliability and compliance requirements.
Monitoring, analytics, and automation extend resilience beyond static designs. Predictive insights guide administrators in making informed decisions, while automation handles repetitive tasks such as resource allocation, failover, and recovery sequences. Orchestration coordinates these processes across nodes and sites, enabling adaptive responses that optimize uptime. Candidates must understand how to leverage monitoring and automation to maintain cluster health, optimize workloads, and respond efficiently to failures without compromising stability or performance.
Integration with hybrid and virtual infrastructures introduces additional complexity but provides scalability and flexibility. Administrators must plan for cross-layer failover, latency management, and resource coordination between physical and virtual nodes. Multi-site deployments require robust disaster recovery planning, including replication, synchronized backups, and tested failover procedures. Security and compliance considerations are essential throughout, ensuring that high availability does not come at the expense of data integrity or regulatory adherence.
Finally, strategic operational management binds these elements together into a cohesive, resilient, and efficient framework. Administrators must continuously monitor cluster health, refine configurations, optimize resource usage, and plan for future demands. By adopting a proactive, data-driven, and systematic approach, clusters can withstand failures, scale with organizational needs, and maintain uninterrupted service.
In conclusion, preparation for the Veritas VCS-323 exam demands more than memorization of procedures; it requires a deep understanding of the interplay between cluster components, operational best practices, and strategic management principles. Candidates must develop the skills to design, implement, and maintain clusters that are resilient, efficient, and adaptable. Mastery of these concepts ensures that organizations can rely on their clusters for continuous, high-performance service delivery, reinforcing the critical role of cluster administrators in sustaining operational excellence.
Veritas VCS-323 practice test questions and answers, training course, study guide are uploaded in ETE Files format by real users. Study and Pass VCS-323 Administration of Veritas Backup Exec 16 certification exam dumps & practice test questions and answers are to help students.
Why customers love us?
What do our customers say?
The resources provided for the Veritas certification exam were exceptional. The exam dumps and video courses offered clear and concise explanations of each topic. I felt thoroughly prepared for the VCS-323 test and passed with ease.
Studying for the Veritas certification exam was a breeze with the comprehensive materials from this site. The detailed study guides and accurate exam dumps helped me understand every concept. I aced the VCS-323 exam on my first try!
I was impressed with the quality of the VCS-323 preparation materials for the Veritas certification exam. The video courses were engaging, and the study guides covered all the essential topics. These resources made a significant difference in my study routine and overall performance. I went into the exam feeling confident and well-prepared.
The VCS-323 materials for the Veritas certification exam were invaluable. They provided detailed, concise explanations for each topic, helping me grasp the entire syllabus. After studying with these resources, I was able to tackle the final test questions confidently and successfully.
Thanks to the comprehensive study guides and video courses, I aced the VCS-323 exam. The exam dumps were spot on and helped me understand the types of questions to expect. The certification exam was much less intimidating thanks to their excellent prep materials. So, I highly recommend their services for anyone preparing for this certification exam.
Achieving my Veritas certification was a seamless experience. The detailed study guide and practice questions ensured I was fully prepared for VCS-323. The customer support was responsive and helpful throughout my journey. Highly recommend their services for anyone preparing for their certification test.
I couldn't be happier with my certification results! The study materials were comprehensive and easy to understand, making my preparation for the VCS-323 stress-free. Using these resources, I was able to pass my exam on the first attempt. They are a must-have for anyone serious about advancing their career.
The practice exams were incredibly helpful in familiarizing me with the actual test format. I felt confident and well-prepared going into my VCS-323 certification exam. The support and guidance provided were top-notch. I couldn't have obtained my Veritas certification without these amazing tools!
The materials provided for the VCS-323 were comprehensive and very well-structured. The practice tests were particularly useful in building my confidence and understanding the exam format. After using these materials, I felt well-prepared and was able to solve all the questions on the final test with ease. Passing the certification exam was a huge relief! I feel much more competent in my role. Thank you!
The certification prep was excellent. The content was up-to-date and aligned perfectly with the exam requirements. I appreciated the clear explanations and real-world examples that made complex topics easier to grasp. I passed VCS-323 successfully. It was a game-changer for my career in IT!


