Pass Amazon AWS Certified Developer - Associate Certification Exam in First Attempt Guaranteed!
Get 100% Latest Exam Questions, Accurate & Verified Answers to Pass the Actual Exam!
30 Days Free Updates, Instant Download!


AWS Certified Developer - Associate DVA-C02 Premium Bundle
- Premium File 620 Questions & Answers. Last update: Jun 22, 2026
- Training Course 430 Video Lectures
- Study Guide 1091 Pages
AWS Certified Developer - Associate DVA-C02 Premium Bundle
- Premium File 620 Questions & Answers
Last update: Jun 22, 2026 - Training Course 430 Video Lectures
- Study Guide 1091 Pages
Purchase Individually

Premium File

Training Course

Study Guide
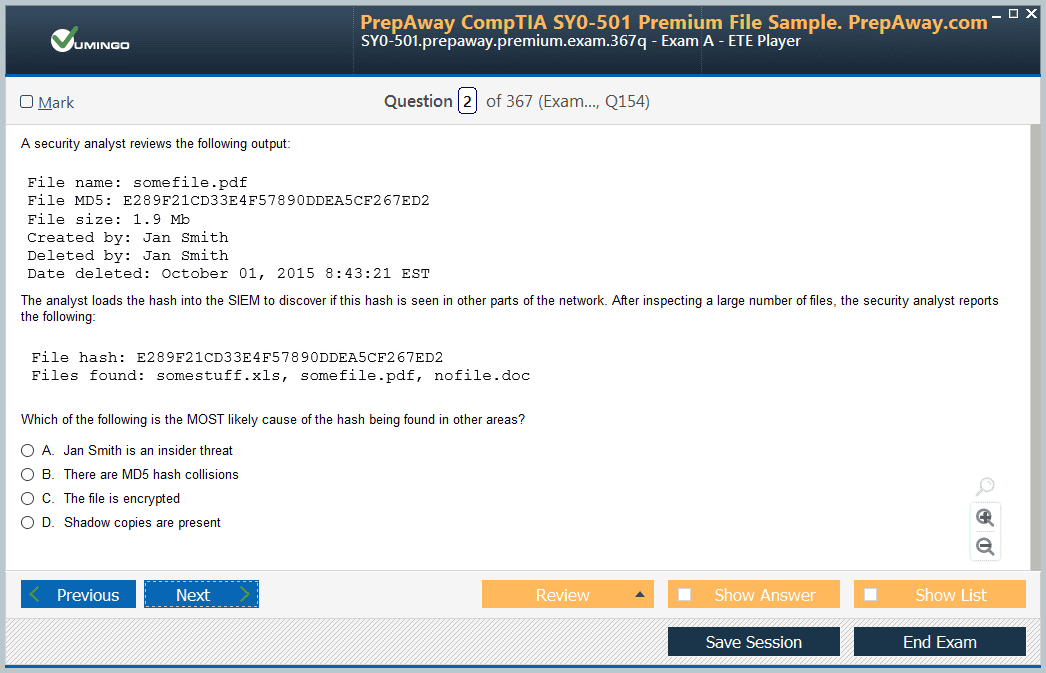
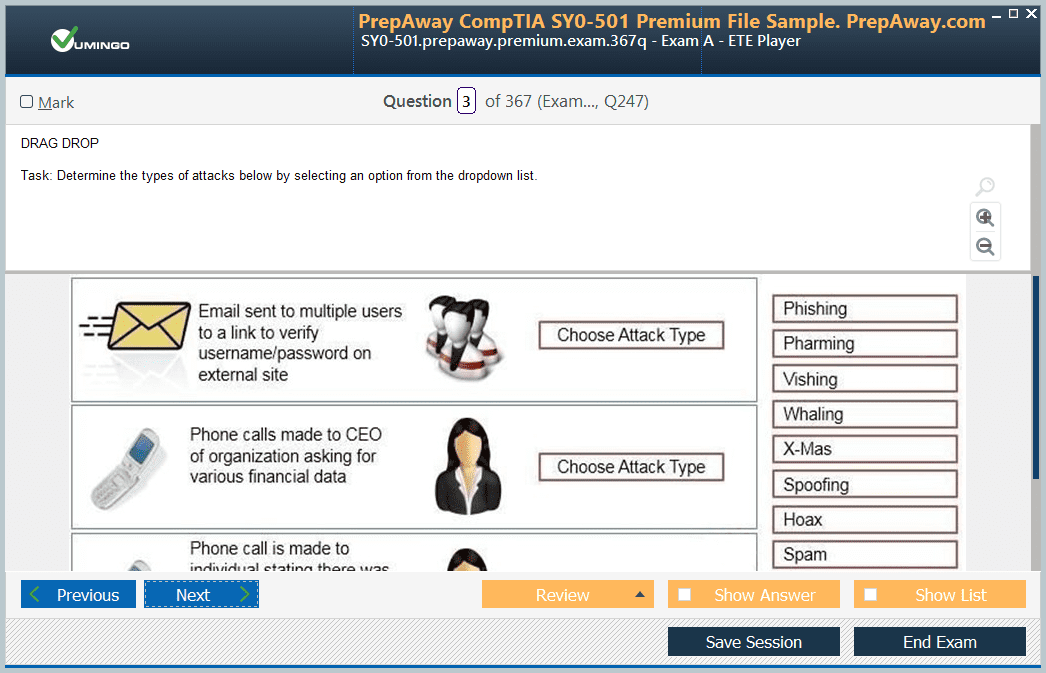
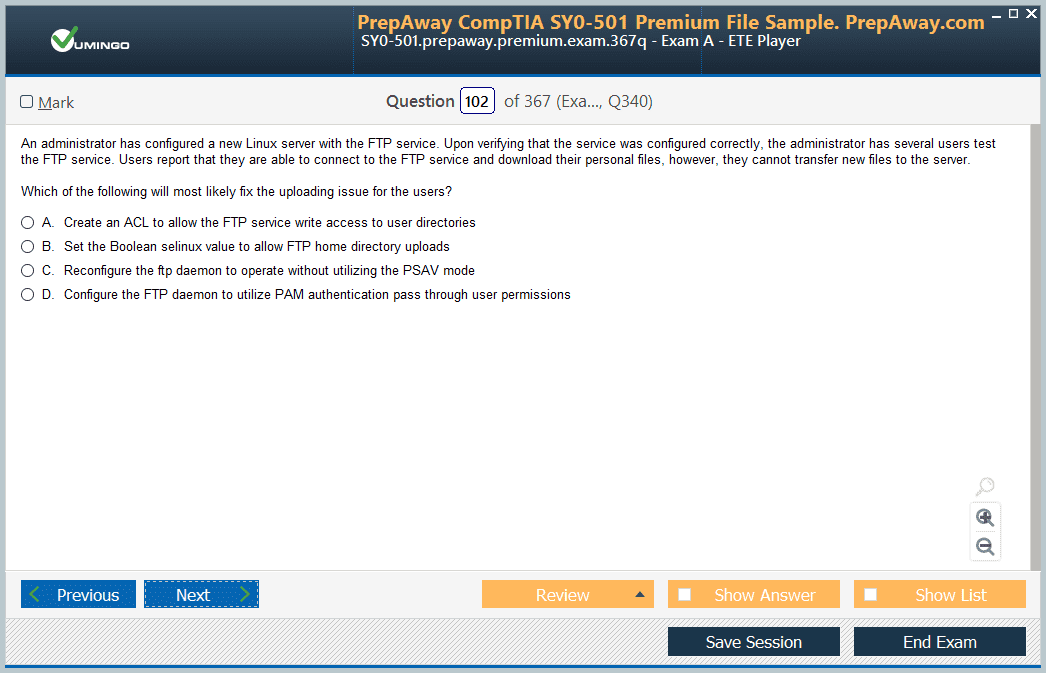
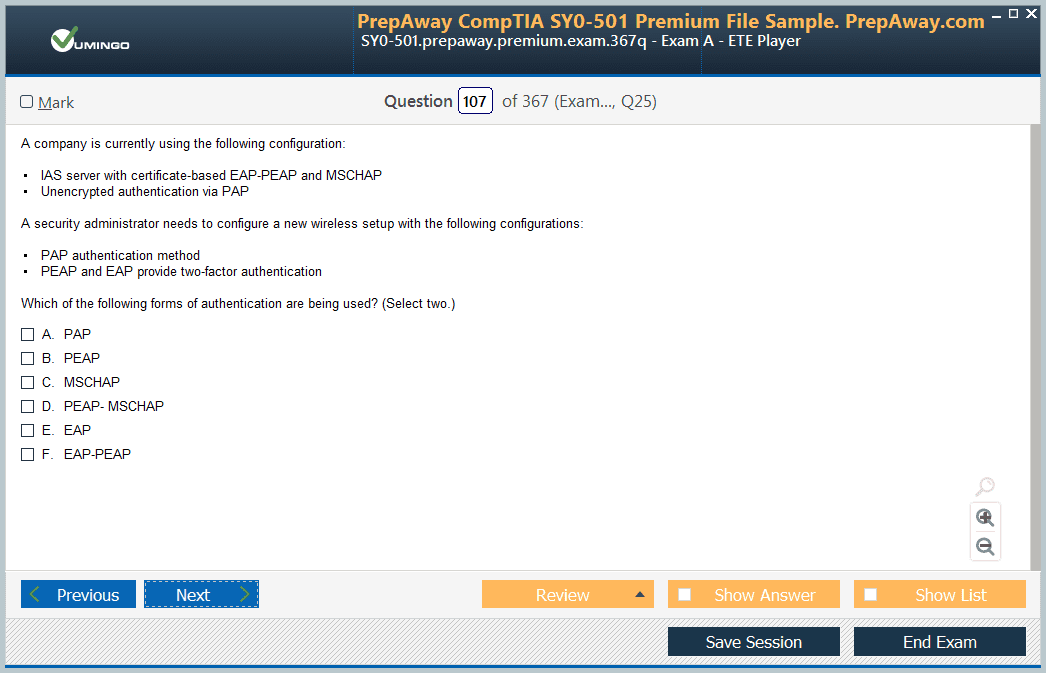








AWS Certified Developer - Associate DVA-C02 Exam - AWS Certified Developer - Associate DVA-C02
| Download Free AWS Certified Developer - Associate DVA-C02 Exam Questions |
|---|
Amazon AWS Certified Developer - Associate Certification Practice Test Questions and Answers, Amazon AWS Certified Developer - Associate Certification Exam Dumps
All Amazon AWS Certified Developer - Associate certification exam dumps, study guide, training courses are prepared by industry experts. Amazon AWS Certified Developer - Associate certification practice test questions and answers, exam dumps, study guide and training courses help candidates to study and pass hassle-free!
How to Succeed in the AWS Certified Developer Associate Exam
Earning the AWS Certified Developer Associate credential is a significant milestone for any professional seeking to validate their expertise in cloud application development. The DVA-C02 exam is crafted to assess both theoretical knowledge and practical experience, focusing on the ability to design, deploy, and manage applications within the AWS environment. The certification demonstrates a comprehensive understanding of core AWS services, best practices for cloud architecture, and the capacity to implement robust solutions in real-world scenarios. For aspirants, the journey is not just about memorizing services but about cultivating the insight to integrate multiple tools to solve complex development challenges.
A successful preparation strategy begins with selecting resources that provide both conceptual clarity and hands-on engagement. The AWS Certified Developer Associate online course is highly recommended as a foundational tool. This program offers more than fifteen hours of guided video content, covering introductory concepts, core services, command-line interactions, serverless computing, continuous integration and deployment tools, security, and advanced AWS services. The course design gradually builds proficiency, ensuring learners gain confidence in navigating the AWS ecosystem while reinforcing practical application through interactive exercises.
Preparing for the AWS Certified Developer Associate Journey
Once the conceptual foundation is established, it is crucial to transition into practice tests. The exams simulate real-world scenarios and often present nuanced options that test deeper comprehension rather than surface knowledge. Repeated attempts help to solidify understanding and improve test-taking strategies, with the goal of achieving a high accuracy rate before attempting the official certification. This combination of structured learning and assessment forms the backbone of effective exam preparation.
Essential Topics to Master for the Exam
Certain AWS services and concepts frequently appear in scenario-based questions, making them indispensable for anyone aiming to clear the certification on the first attempt. Serverless computing, particularly with Lambda, is one of the most prominent areas. Candidates should understand Lambda functions, including versioning, aliases, and how it integrates with other services such as API Gateway, DynamoDB, and S3. Questions often revolve around designing efficient, event-driven architectures and implementing Lambda in combination with deployment tools like CodeDeploy and SAM.
Key management and encryption are another focal point. Understanding encryption at rest and in transit, the role of master keys, envelope keys, and data keys is critical. Scenarios may involve securing data during transfer between services, implementing default S3 encryption, or integrating Lambda functions with KMS to handle sensitive information. The exam tests not just the technical setup but also the comprehension of secure practices and how encryption mechanisms interact across multiple services.
Database services, especially DynamoDB, are a major emphasis. Candidates need to be familiar with concepts such as read and write capacity units, secondary indexes, projection expressions, and caching with DAX or ElastiCache. Integrating DynamoDB with Lambda or S3 to manage session data, implementing TTL, handling throughput exceptions, and optimizing queries are typical topics. Understanding these elements in combination with other services helps to demonstrate practical knowledge rather than theoretical familiarity.
Elastic Beanstalk and CloudFormation introduce questions about application deployment and infrastructure orchestration. Elastic Beanstalk requires familiarity with deployment strategies such as rolling, immutable, and all-at-once updates. Understanding how to retain RDS instances while modifying environments or deploying new application versions is often tested. CloudFormation, on the other hand, examines the candidate’s ability to manage templates, orchestrate multiple resources, and ensure correct versioning, sometimes in conjunction with Lambda or CodeDeploy. These services test an applicant’s ability to automate and scale deployments reliably.
Continuous integration and delivery tools, including CodeDeploy, CodeBuild, CodeCommit, and CodePipeline, play a significant role. The exam evaluates understanding of configuration files, error handling, rollback procedures, and pipeline orchestration. Candidates should be adept at managing builds, automating deployments, and troubleshooting failures within the pipeline. These tools are essential for demonstrating an ability to maintain efficient development workflows in cloud-native environments.
Messaging and caching services such as SQS and ElastiCache are tested through scenario-based questions. Understanding visibility timeouts, long and short polling mechanisms, FIFO and standard queues, and combining SQS with EC2 for scalable architectures is vital. ElastiCache, with Redis and Memcached, emphasizes caching strategies, performance optimization, and integration with RDS or DynamoDB. Candidates are often asked to design solutions that maximize efficiency and responsiveness while maintaining consistency.
API Gateway, S3, and content delivery mechanisms are frequently assessed in practical contexts. API Gateway questions often involve multiple stages, CORS handling, caching, and integration with Lambda functions. S3 is tested through scenarios involving bucket policies, encryption, data optimization, and interaction with services like Kinesis or CloudFront. Understanding how CloudFront caching works, including edge locations and time-to-live configurations, is critical for designing performant architectures.
Compute, load balancing, and scaling services such as EC2, Elastic Load Balancer, and Auto Scaling are examined to assess infrastructure management skills. Candidates should know how to configure SSL, perform health checks, manage traffic routing, and integrate with Route53. Hands-on experience in deploying instances, setting up autoscaling groups, and ensuring high availability is often implied in scenario questions.
Containerization and orchestration using ECS, Docker images, and integration with CodeDeploy form another significant area. Candidates are expected to understand deployment on EC2 instances, container lifecycle management, and designing solutions that maintain operational consistency across services. Questions may present complex scenarios requiring thoughtful selection of deployment strategies and resource allocation.
Identity management, including IAM roles, policies, and secure resource access, is a recurring theme. Understanding how to grant permissions effectively, avoid over-provisioning, and leverage roles instead of access keys in application scenarios demonstrates an awareness of security best practices. Candidates may also encounter questions about creating shared policies for multiple users or services, requiring a nuanced understanding of access control.
Specialized services like Kinesis, Cognito, Step Functions, RDS, and SNS also appear in practical problem-solving questions. Kinesis involves real-time data processing, streaming, and integration with Lambda and S3. Cognito focuses on authentication, data synchronization, and user role management, including handling unauthenticated users. Step Functions assess the ability to orchestrate complex workflows, while RDS questions typically explore integration with other AWS services. SNS tests understanding of notifications and event-driven architectures.
Candidates should also be aware of which topics are not included in the exam. Networking-heavy subjects such as VPC configurations, VPNs, and routing tables, along with low-level EC2 concepts like EBS volumes, availability zones, and disaster recovery strategies, are generally excluded. Prioritizing development-focused, hands-on services over intricate infrastructure details ensures that preparation is efficient and aligned with exam requirements.
Success in the AWS Certified Developer Associate exam hinges on a blend of structured learning, consistent practice, and experiential understanding. It is essential to not only absorb concepts but also apply them to simulate real-world development and deployment scenarios. The certification measures the ability to think holistically about cloud applications, anticipate integration challenges, and employ AWS services to deliver reliable solutions. This approach transforms preparation from rote memorization into genuine expertise, equipping candidates with the confidence to navigate complex architectures.
Engaging deeply with interactive labs and scenario-based exercises reinforces this knowledge. This practical exposure cultivates an understanding that extends beyond the exam, preparing candidates for the demands of real-world cloud development environments.
In a methodical, experience-driven approach is the key to mastering the AWS Certified Developer Associate exam. By focusing on high-impact services, integrating hands-on exercises, leveraging practice tests, and understanding the practical interplay of AWS services, aspirants can achieve proficiency and confidence. The exam rewards not only knowledge but the ability to apply that knowledge in designing, deploying, and managing cloud applications efficiently and securely.
Understanding Serverless Architectures and Lambda Integration
A cornerstone of the AWS Certified Developer Associate examination lies in the comprehension and application of serverless architectures. Serverless computing enables developers to construct and deploy applications without provisioning or managing servers, allowing for scalability, cost efficiency, and agility. Central to this paradigm is the Lambda service, which executes code in response to events and can seamlessly interact with a range of AWS services. Candidates are expected to understand the intricacies of Lambda, including function versions, aliases, and environment configurations. Scenarios often require integrating Lambda with storage services, API endpoints, and data streaming solutions, demanding a holistic view of the architecture rather than a piecemeal understanding.
The examination also examines the orchestration of Lambda with deployment tools. Combining Lambda with CodeDeploy or SAM templates requires awareness of deployment hooks, version control, and rollback strategies. Candidates should be able to determine how different deployment patterns affect the operational continuity of applications, especially in multi-stage environments. These questions are designed to test both conceptual clarity and the ability to implement practical solutions that can operate reliably under varying workloads and real-world constraints.
Navigating Encryption and Key Management
Another significant area of emphasis in the examination is encryption and key management. The AWS environment provides extensive tools for securing data at rest and in transit, with Key Management Service playing a pivotal role in establishing cryptographic controls. Candidates must understand the different types of keys, including master keys and data keys, and how they interact with storage services like S3 and DynamoDB. Questions frequently present scenarios where data needs to be encrypted before transfer or storage, testing the candidate’s ability to apply the correct encryption strategy in combination with other services. Understanding key rotation, access controls, and integration with serverless workflows is essential to demonstrate both practical proficiency and adherence to security best practices.
Working with Databases and DynamoDB
DynamoDB is a non-relational, high-performance database service that appears prominently in exam scenarios. Candidates should be familiar with its core components, such as tables, partition keys, indexes, and throughput management. Questions often involve calculating read and write capacity units, understanding the implications of secondary indexes, and employing caching mechanisms with ElastiCache to optimize performance. Integrating DynamoDB with Lambda functions for event-driven processing or combining it with S3 for archival purposes demonstrates the candidate’s ability to implement real-world solutions. Additionally, understanding the use of TTL for data expiration, handling throughput exceptions, and implementing efficient query patterns ensures that applications are scalable and responsive.
Deployment with Elastic Beanstalk and CloudFormation
Deploying applications reliably and efficiently is another critical focus of the AWS Certified Developer Associate examination. Elastic Beanstalk simplifies the deployment process by automating the infrastructure management, application updates, and environment configuration. Candidates must understand different deployment strategies, such as rolling, immutable, and all-at-once updates, and how these strategies impact the continuity and stability of running applications. Questions may require knowledge of how to preserve database instances during environment modifications or how to deploy multiple application versions simultaneously, ensuring minimal downtime.
CloudFormation, in contrast, tests the ability to define and provision infrastructure as code. Candidates must be able to create and manage templates that orchestrate multiple services, maintain version control, and integrate with Lambda or CodeDeploy. Understanding the parameters, conditions, and outputs in CloudFormation templates is essential for managing complex environments efficiently. Scenarios often combine deployment and automation challenges, requiring the candidate to make decisions that reflect both operational effectiveness and best practices for infrastructure management.
Continuous Integration and Delivery with AWS Developer Tools
The examination places substantial emphasis on continuous integration and delivery pipelines. Tools such as CodeDeploy, CodeBuild, CodeCommit, and CodePipeline are assessed for their role in automating build, test, and deployment processes. Candidates must understand configuration files, error handling, rollback procedures, and the orchestration of multiple stages within pipelines. Realistic scenarios test the ability to integrate these tools with serverless applications, containerized workloads, and database services. Candidates should be able to troubleshoot pipeline failures, optimize build times, and ensure that deployments are consistent and repeatable. Understanding the interplay between these services demonstrates the candidate’s ability to design robust development workflows and maintain operational reliability.
Messaging and Caching Strategies
Effective application design in AWS often involves messaging and caching mechanisms. Simple Queue Service is a key element of this strategy, providing a scalable messaging system that decouples components and ensures reliable delivery. Candidates should understand the differences between FIFO and standard queues, visibility timeouts, polling mechanisms, and how SQS integrates with other services like EC2 or Lambda. Exam questions often present scenarios requiring the candidate to design messaging solutions that maximize throughput while maintaining data consistency.
Caching services, particularly ElastiCache with Redis or Memcached, are equally critical. Candidates must understand caching strategies, performance tuning, and integration with database services such as DynamoDB or RDS. By leveraging caching effectively, applications can achieve higher responsiveness and reduced latency, an essential consideration in designing scalable, high-performing architectures. Exam questions test both conceptual understanding and the ability to apply caching solutions in practical deployment scenarios.
API Gateway and Storage Services
API Gateway is another area where candidates must demonstrate proficiency. This service enables developers to create, deploy, and manage secure APIs at scale. Questions typically involve designing multi-stage API deployments, handling cross-origin resource sharing, implementing caching, and integrating with Lambda or other backend services. Understanding how API Gateway manages requests, stages, and throttling is essential to answer scenario-based questions effectively.
Storage solutions, particularly S3, are frequently assessed. Candidates must comprehend bucket policies, encryption, access management, and interaction with other AWS services such as CloudFront for content distribution or Kinesis for streaming data. Exam scenarios often require optimizing storage for performance, cost efficiency, or security. Candidates should be able to design workflows that combine multiple services to ensure secure, reliable, and efficient data storage and retrieval.
Compute, Load Balancing, and Scaling
The examination also evaluates knowledge of compute resources, load balancing, and scaling mechanisms. EC2 instances, Elastic Load Balancers, and Auto Scaling groups are examined for their role in designing resilient and highly available applications. Candidates are expected to understand SSL configuration, traffic routing, health checks, and integration with DNS services such as Route53. Questions may involve designing architectures that handle variable workloads while maintaining availability and performance. Practical experience in deploying and scaling compute resources is critical to demonstrating competence in these areas.
Containerization and Orchestration
Containerized applications are an integral part of modern cloud development, and the exam often includes questions related to Elastic Container Service. Candidates must understand Docker image deployment, orchestration, service scaling, and integration with deployment pipelines such as CodeDeploy. Designing containerized solutions that operate reliably across multiple environments is a key competency assessed by the exam. Understanding how containers interact with storage, networking, and compute resources ensures that the candidate can implement solutions that are both efficient and operationally resilient.
Identity and Access Management
Security is a central theme in AWS development, with IAM services forming the backbone of access management. Candidates must understand roles, policies, and the best practices for assigning permissions to users and applications. Scenario-based questions often involve designing access strategies that minimize risk while enabling operational flexibility. Knowledge of role-based access, policy inheritance, and integration with serverless or containerized applications is essential. Candidates should also be aware of how to create shared policies for multiple users or services, demonstrating an understanding of scalable security practices.
Real-Time Data Processing and User Authentication
Services such as Kinesis and Cognito are critical for handling streaming data and user authentication. Kinesis enables real-time data ingestion, processing, and integration with Lambda or storage services. Candidates should be able to design pipelines that handle variable data volumes efficiently and ensure reliable processing. Cognito focuses on user authentication, data synchronization, and role-based access, including the handling of unauthenticated users. Understanding these services in combination with other AWS components demonstrates the ability to design end-to-end solutions that are secure, responsive, and maintainable.
Orchestrating Workflows and Relational Databases
Step Functions provide a mechanism for orchestrating complex workflows, allowing developers to manage sequences of tasks across multiple services. Questions may involve designing multi-step processes that handle failures gracefully, ensuring that workflows are robust and maintainable. Relational databases such as RDS are examined in the context of integration with other services, requiring candidates to design schemas, manage connections, and ensure scalability and performance. Scenario-based questions emphasize practical knowledge and the ability to implement solutions that address business requirements.
Event-Driven Architectures and Notifications
Finally, notification services such as SNS are tested within event-driven architectures. Candidates must understand how to design solutions that disseminate information efficiently, integrate with other services, and trigger downstream workflows. Exam questions often require combining SNS with Lambda, SQS, or database services to implement real-time notifications or automated responses. Demonstrating proficiency in these areas underscores the candidate’s capability to design applications that are responsive, reliable, and aligned with modern cloud development practices.
In preparing for the AWS Certified Developer Associate examination, focusing on these services with a practical, scenario-driven mindset is essential. Success depends on the ability to integrate multiple services effectively, troubleshoot challenges, and implement solutions that reflect real-world operational requirements. By immersing in interactive labs, practice exams, and hands-on experimentation, candidates cultivate the depth of knowledge and confidence necessary to navigate the complexities of the AWS ecosystem and achieve certification.
Gaining Hands-On Experience with AWS Services
Achieving success in the AWS Certified Developer Associate examination requires more than theoretical comprehension. Practical experience with AWS services is essential for developing a deep understanding of how these tools interact and operate in real-world environments. Immersing oneself in hands-on labs allows candidates to experiment with core services such as Lambda, DynamoDB, S3, and EC2, and to observe how each behaves under different conditions. Engaging in such experiential learning fosters the ability to troubleshoot, optimize, and implement solutions efficiently, bridging the gap between knowledge and application.
Interactive labs encourage the creation of real-world workflows that combine multiple services. For instance, integrating Lambda functions with S3 for data processing, automating deployments with CodePipeline, and employing DynamoDB for session management allows candidates to internalize operational dynamics. Through these exercises, aspirants develop the aptitude to anticipate potential bottlenecks, understand service limitations, and design architectures that are both scalable and resilient. By confronting practical challenges early in preparation, candidates gain the confidence needed to approach scenario-based questions with clarity.
Continuous Integration and Delivery in Practice
Continuous integration and delivery pipelines are fundamental to cloud-native development. Developing fluency in tools such as CodeDeploy, CodeBuild, CodeCommit, and CodePipeline requires the creation of automated workflows that manage application building, testing, and deployment. Candidates must practice designing pipelines that accommodate various deployment strategies, manage errors gracefully, and maintain operational continuity. Hands-on exercises provide the opportunity to explore configuration nuances, build specifications, and deployment hooks, enabling a comprehensive understanding of how automation enhances development efficiency.
By simulating real deployment scenarios, candidates gain insight into the complexities of orchestrating services at scale. They learn how to handle failures within pipelines, implement rollback mechanisms, and ensure that each stage integrates seamlessly with others. This practical exposure is invaluable, as the examination frequently presents situations where multiple services interact, and the candidate must determine the optimal deployment strategy. Familiarity with these interactions not only reinforces theoretical knowledge but also enhances problem-solving skills, which are crucial for navigating the exam successfully.
Optimizing Serverless Applications
Serverless computing continues to be a pivotal focus of the examination. Candidates must develop an intuitive understanding of how Lambda functions operate in combination with triggers, APIs, and other services. Practical exercises involving versioning, alias management, and environment variables are essential for demonstrating mastery. Additionally, testing how Lambda integrates with data streams, storage, and messaging services provides insight into designing efficient and maintainable serverless solutions. Real-world experimentation cultivates the ability to construct applications that are responsive, cost-effective, and resilient to varying loads.
Learning to optimize serverless applications also includes understanding execution constraints, cold starts, and error handling. Candidates who experiment with different memory configurations, timeouts, and concurrent execution limits gain a more nuanced comprehension of performance optimization. This knowledge is frequently applied in exam scenarios where candidates must select the most efficient approach for a given architectural challenge. By engaging with these complexities practically, learners are better prepared to analyze and implement solutions that reflect operational excellence.
Leveraging Databases and Caching Mechanisms
DynamoDB and caching services such as ElastiCache play a critical role in designing scalable and high-performing applications. Practical exposure to these services involves creating tables, managing throughput, employing secondary indexes, and implementing caching strategies to reduce latency. Experiments that integrate these services with Lambda or other processing tools allow candidates to observe how data flows through an architecture, identify potential bottlenecks, and implement solutions that maintain efficiency.
Caching strategies are particularly significant, as they improve application responsiveness and reduce load on primary data stores. Working with Redis or Memcached in lab environments teaches candidates how to choose appropriate caching patterns and manage eviction policies effectively. These exercises reinforce the ability to make informed design decisions, a skill that is frequently assessed through scenario-based questions in the examination. Candidates who master these integrations demonstrate an understanding of both performance optimization and practical deployment considerations.
API Gateway and Storage Optimization
API Gateway is often central to building scalable and maintainable architectures. Candidates benefit from practical exercises that involve creating multiple stages, configuring throttling, handling cross-origin requests, and integrating APIs with Lambda or other backend services. Experimentation allows candidates to witness how changes in configuration affect performance, latency, and security, thereby enhancing their ability to design resilient applications.
Storage solutions, particularly S3, also require hands-on engagement. Candidates should practice managing bucket policies, implementing encryption, optimizing object storage, and integrating S3 with services such as CloudFront for content delivery or Kinesis for data ingestion. These exercises help to internalize the nuances of security, access control, and performance optimization. Understanding the interplay between storage and other services equips candidates with the ability to construct architectures that are both reliable and efficient.
Compute, Scaling, and Load Balancing in Real Scenarios
Practical experience with EC2, Elastic Load Balancers, and Auto Scaling groups provides insight into designing applications that maintain high availability and fault tolerance. Candidates should practice configuring SSL, performing health checks, and managing traffic routing to ensure resilient architectures. By simulating variable workloads and observing scaling behavior, candidates learn how to maintain optimal performance under different conditions. These exercises mirror real-world challenges and help aspirants develop the intuition necessary to answer scenario-based examination questions accurately.
Containerization and Orchestration Exercises
Containerized deployments with ECS require candidates to understand how to build, deploy, and manage Docker containers in a cloud environment. Hands-on labs allow candidates to practice orchestrating containers, integrating them with CI/CD pipelines, and managing scaling and updates. Observing the interactions between containers, compute resources, and networking configurations provides a practical understanding of operational considerations. These experiences cultivate the ability to design efficient, maintainable, and resilient containerized architectures, which are frequently tested in the examination.
Identity and Security Practices
Security remains a critical aspect of the examination, with IAM services forming the foundation of access management. Candidates should practice creating roles, managing policies, and implementing access controls across multiple services. Labs that simulate real-world scenarios, such as granting temporary permissions to serverless functions or managing policies for groups of users, help develop practical insight into secure application design. Understanding these security interactions is essential for answering examination questions that assess the ability to balance operational efficiency with risk mitigation.
Streaming Data and User Authentication
Services such as Kinesis and Cognito require experiential learning to fully appreciate their capabilities. Practical exercises with Kinesis involve real-time data ingestion, processing, and integration with Lambda or S3. Candidates learn to manage varying data volumes, design processing pipelines, and ensure reliable delivery. Cognito exercises focus on user authentication, data synchronization, and role management, including scenarios involving unauthenticated users. Engaging with these services practically strengthens the ability to design applications that are secure, responsive, and operationally sound.
Orchestrating Workflows and Notifications
Step Functions provide a mechanism for automating multi-step workflows across different services. Practical exercises allow candidates to construct orchestrated processes, manage failures gracefully, and design scalable solutions. Hands-on experience reinforces the ability to implement complex architectures that are maintainable and efficient. Similarly, SNS exercises involve setting up notifications, integrating with other services, and designing event-driven workflows. These experiences highlight the interplay between messaging, processing, and storage, cultivating the ability to design end-to-end solutions.
Integrating Multiple Services
One of the most valuable outcomes of hands-on preparation is learning to integrate multiple services effectively. Candidates who engage with real-world scenarios, combining serverless functions, database operations, messaging queues, and deployment pipelines, develop the capacity to design cohesive architectures. These integrated exercises help build intuition about dependencies, performance considerations, and fault tolerance. By understanding how services interact, candidates gain confidence in tackling complex, scenario-based questions on the examination.
Developing Problem-Solving Intuition
The examination rewards candidates who can think critically and design solutions under constraints. Practical exercises cultivate problem-solving intuition by presenting scenarios that mimic real operational challenges. Candidates learn to balance trade-offs between performance, cost, and reliability while applying AWS best practices. These experiences encourage analytical thinking, helping candidates approach each examination question with a structured methodology rather than relying on memorization.
Building Confidence Through Repetition
Repetition in practical exercises reinforces understanding and builds confidence. By repeatedly deploying applications, configuring pipelines, and integrating services, candidates develop muscle memory and familiarity with the AWS environment. This repetition ensures that concepts are internalized, scenarios become familiar, and candidates can navigate the examination with composure. The combination of experiential learning and repeated practice creates a robust foundation for both the theoretical and practical aspects of the certification.
Designing Scalable Architectures with AWS Services
Achieving proficiency in the AWS Certified Developer Associate examination requires a nuanced understanding of how to design scalable and resilient architectures. Candidates must learn to conceptualize solutions that integrate multiple AWS services seamlessly, balancing efficiency, cost, and performance. Developing a cloud-native mindset allows aspirants to anticipate bottlenecks, optimize resource utilization, and ensure high availability. Real-world scenarios often present challenges such as fluctuating workloads, integration of serverless functions with databases, and orchestrating pipelines for automated deployments, all of which demand practical foresight and structured thinking.
Serverless functions form the core of many architectures tested in the examination. Lambda enables execution of code in response to events without requiring server management, making it ideal for scalable applications. Candidates should understand how to implement function versions and aliases to maintain operational continuity, manage concurrency, and troubleshoot errors in live environments. Integration with other services like API Gateway, DynamoDB, and S3 is essential, as most scenarios involve coordinating multiple components to achieve the desired functionality. Understanding the implications of these interactions strengthens the ability to design fault-tolerant systems.
Mastering Continuous Integration and Deployment Practices
Continuous integration and deployment pipelines remain a focal point of practical mastery. Tools such as CodeDeploy, CodeBuild, CodeCommit, and CodePipeline facilitate automated workflows that enhance development speed, reliability, and maintainability. Candidates should practice designing pipelines that accommodate complex deployment strategies, manage failures, and roll back changes when necessary. Experiential exercises reveal the intricacies of pipeline orchestration, including the sequence of stages, configuration parameters, and error-handling mechanisms. These practical insights are frequently tested in scenario-based questions, emphasizing the candidate’s ability to execute real-world deployment strategies efficiently.
Understanding the nuances of CI/CD integration also involves simulating interactions between serverless functions, containerized applications, and database services. By deploying multi-service applications within pipelines, candidates can observe dependencies, timing considerations, and potential failure points. This approach fosters the development of a holistic understanding of how automated workflows function within the broader ecosystem, enabling aspirants to select optimal strategies under exam conditions.
Implementing Secure and Efficient Data Management
Data management is a critical dimension of the AWS Certified Developer Associate examination. Services such as DynamoDB, S3, and ElastiCache require practical engagement to understand how to store, retrieve, and secure information efficiently. Candidates must practice managing throughput, designing indexes, and leveraging caching strategies to optimize performance. By integrating these services with serverless functions, candidates learn to construct workflows that are both responsive and cost-effective. Experimenting with TTL settings, query optimization, and exception handling enhances the ability to manage data in scalable architectures.
Encryption and key management remain central to data security. Practical exercises with Key Management Service help candidates understand key hierarchies, access policies, and integration with storage and compute services. Scenarios often involve encrypting data before transfer, applying default encryption on storage services, or using Lambda functions to process sensitive information securely. These hands-on experiences are crucial for internalizing best practices in data protection and preparing for examination questions that assess both technical understanding and practical application.
Orchestrating Workflows with Step Functions
Step Functions enable the orchestration of complex workflows across multiple services, providing candidates the ability to design sequences of tasks with clear execution logic. Experiential learning with Step Functions involves constructing workflows that handle errors gracefully, manage dependencies between services, and optimize execution timing. Candidates should practice integrating Step Functions with serverless functions, messaging services, and database operations to build cohesive and maintainable architectures. Understanding workflow orchestration is essential for addressing examination scenarios that test the ability to design scalable, automated processes.
By experimenting with practical workflows, candidates gain insight into conditional logic, parallel execution, and task coordination. This knowledge is particularly useful when designing solutions that must handle high volumes of transactions, maintain data consistency, and remain resilient under varying operational conditions. Scenario-based questions often require these skills to determine the most effective and efficient approach for complex systems.
Optimizing APIs and Storage Services
API Gateway and S3 are frequently used in tandem to create responsive, scalable, and secure applications. Candidates must understand how to design multiple stages, manage caching, handle cross-origin requests, and integrate APIs with serverless backends. Hands-on experience allows aspirants to observe how configuration choices affect performance, reliability, and security, providing insights that cannot be gained through theory alone.
Similarly, storage optimization is tested through practical exercises involving bucket policies, encryption, access control, and integration with content delivery networks. Candidates should practice implementing workflows that optimize object storage for cost and performance, integrate S3 with streaming services, and employ automated lifecycle management. These exercises reinforce operational knowledge and develop intuition for designing storage solutions that are both effective and sustainable under fluctuating workloads.
Scaling Compute Resources and Load Balancing
Practical mastery of compute services, load balancing, and auto-scaling mechanisms is essential for resilient application design. Candidates should engage with EC2 instances, Elastic Load Balancers, and Auto Scaling groups to understand how these components interact under dynamic conditions. Exercises involving traffic routing, SSL configuration, health checks, and monitoring teach candidates how to maintain availability and reliability in real-world architectures. By observing scaling behavior under variable workloads, aspirants can design systems that remain performant and cost-efficient, reflecting the types of scenario-based challenges presented in the examination.
Leveraging Containers and Orchestration
Containerized workloads using ECS provide candidates with the ability to deploy and manage applications consistently across environments. Practical exercises with container orchestration include building Docker images, deploying containers to ECS clusters, and integrating with CI/CD pipelines. Candidates should explore scaling strategies, updates, and service dependencies to develop a comprehensive understanding of operational considerations. Hands-on experience ensures familiarity with the challenges of containerized architectures and prepares candidates to answer examination questions that require nuanced decision-making in multi-service environments.
Implementing Security and Identity Management
Security is a pervasive consideration in AWS development, and IAM services form the foundation of identity and access management. Candidates should practice creating roles, policies, and secure access configurations across multiple services. Exercises that simulate real-world challenges, such as granting temporary permissions, managing multi-user policies, and securing serverless or containerized applications, develop practical competence. Understanding the balance between operational flexibility and security risk is critical, as examination questions often evaluate the ability to implement secure yet functional solutions in complex scenarios.
Handling Streaming Data and Real-Time Workflows
Kinesis and Cognito are services that require experiential learning to fully grasp their practical application. Kinesis facilitates real-time data ingestion and processing, with exercises involving integration with Lambda and storage services. Candidates should practice managing streams, handling large volumes of data, and ensuring reliable processing. Cognito, on the other hand, focuses on user authentication, data synchronization, and role management. Experiments with user pools, authentication flows, and unauthenticated access help candidates internalize secure, scalable identity management practices that are frequently assessed in the examination.
Notifications and Event-Driven Design
SNS is integral to designing event-driven applications and building responsive workflows. Practical exercises involve integrating notifications with serverless functions, messaging queues, and data stores. Candidates should practice creating workflows that trigger events automatically and deliver information efficiently across services. These exercises reinforce the understanding of how messaging, event processing, and application logic interact, enabling candidates to construct end-to-end solutions that align with both operational requirements and examination expectations.
Integrating Services for Cohesive Architectures
The ability to integrate multiple AWS services is a hallmark of expertise tested in the examination. Candidates who practice combining Lambda, databases, messaging services, APIs, and deployment pipelines develop a comprehensive understanding of architecture design. Experiential learning highlights dependencies, timing considerations, performance trade-offs, and failure handling. Candidates who master these integrations demonstrate the ability to navigate complex scenarios, optimize workflows, and create architectures that are reliable, scalable, and maintainable.
Developing Analytical Problem-Solving Skills
The AWS Certified Developer Associate examination emphasizes analytical problem-solving in realistic scenarios. Hands-on experience cultivates the intuition to approach questions methodically, evaluate alternatives, and select optimal solutions. Practical engagement with services under varying constraints fosters critical thinking, decision-making, and operational judgment. Candidates who combine conceptual knowledge with experiential learning are better equipped to tackle scenario-based questions, as they can draw on prior exposure to similar challenges and apply principles with confidence.
Reinforcing Learning Through Repetition
Repetition and practice are essential for internalizing concepts and building confidence. By repeatedly deploying applications, configuring pipelines, and integrating services, candidates solidify their understanding and develop operational fluency. Hands-on exercises create familiarity with AWS tools and workflows, ensuring that candidates can navigate the examination environment effectively. This repeated engagement with practical scenarios builds competence and assurance, preparing aspirants to apply their knowledge accurately and efficiently under examination conditions.
Consolidating Knowledge Through Review
Success in the AWS Certified Developer Associate examination relies on consolidating both conceptual understanding and practical experience. As candidates approach the final stages of preparation, reviewing core services, workflows, and integrations becomes paramount. A methodical approach to revision allows aspirants to reinforce knowledge gained through video courses, hands-on labs, and practice tests. Repetition solidifies memory, helps identify weak areas, and ensures that operational processes are internalized. By revisiting real-world scenarios and applying principles repeatedly, candidates develop the confidence to handle unfamiliar situations with analytical agility during the examination.
Reviewing serverless architectures is essential, particularly the use of Lambda functions in conjunction with API Gateway, DynamoDB, and S3. Candidates should mentally reconstruct workflows, consider event triggers, and simulate integration scenarios. Understanding function versions, aliases, and deployment nuances ensures readiness to answer questions that assess operational and architectural decision-making. Revisiting encryption, key management, and secure data transfer reinforces the comprehension of best practices for handling sensitive information across services.
Practicing Scenario-Based Questions
The examination emphasizes scenario-driven problem-solving rather than rote memorization. Practicing scenario-based questions equips candidates with the ability to analyze requirements, evaluate alternatives, and select the most appropriate solutions. These exercises often involve multiple AWS services interacting under constraints, requiring critical thinking and holistic understanding. By simulating real operational environments, candidates develop intuition for dependencies, latency considerations, error handling, and scalability concerns. This type of practice also enhances time management, enabling aspirants to approach each question with clarity and efficiency.
Scenario questions frequently explore the orchestration of services, such as integrating Lambda functions with databases, messaging queues, and deployment pipelines. Candidates should visualize how data flows, identify potential bottlenecks, and anticipate how each service responds under load. Practicing these complex scenarios reinforces the ability to make informed decisions and increases confidence in handling unexpected or intricate examination questions. The analytical skills honed through these exercises translate directly into both examination success and real-world cloud development expertise.
Strengthening Hands-On Skills
Practical experience remains indispensable, even at the final stage of preparation. Engaging in hands-on labs and constructing workflows consolidates understanding of core AWS services. By repeatedly deploying applications, configuring pipelines, and integrating serverless functions with databases and storage, candidates internalize operational processes and troubleshooting strategies. Hands-on practice fosters muscle memory, allowing aspirants to approach examination scenarios with composure and precision.
Focusing on interactive exercises that combine multiple services provides insight into real-world challenges. For instance, linking Lambda with S3 for data processing, incorporating caching mechanisms with ElastiCache, and orchestrating workflows with Step Functions ensures that candidates understand service dependencies and operational nuances. These exercises enhance the ability to predict service behavior, design resilient architectures, and optimize performance—skills that are directly tested in scenario-based examination questions.
Optimizing Time and Resources
Effective preparation also requires strategic time management. Candidates should allocate sufficient hours to review core concepts, practice scenario-based questions, and engage in hands-on exercises. Prioritizing high-impact services such as Lambda, DynamoDB, S3, EC2, and CI/CD tools ensures that study efforts focus on areas most likely to appear in the examination. Supplementing this with practical exercises that simulate real-world deployments provides a balanced approach, combining knowledge reinforcement with experiential learning.
Efficient resource allocation includes revisiting practice tests to identify patterns in performance. Analyzing incorrect answers and understanding why particular solutions are optimal cultivates critical thinking. This reflective process allows candidates to avoid repeating mistakes, refine problem-solving strategies, and internalize operational best practices. Maintaining a structured schedule while incorporating these reviews maximizes the effectiveness of preparation and fosters a confident approach on examination day.
Reinforcing Security and Identity Management
Security remains a pervasive consideration throughout preparation. Revisiting IAM configurations, role assignments, and policy structures ensures candidates can implement secure access controls across multiple services. Practicing the application of security principles in different scenarios, including serverless and containerized architectures, reinforces understanding of risk mitigation. Candidates should also consider temporary permissions, cross-service access patterns, and secure data handling to ensure a comprehensive grasp of identity and security management.
Reinforcing security knowledge extends to encryption and key management. Reviewing KMS usage, encryption at rest and in transit, and secure integration with storage and compute services ensures that candidates can answer scenario-based questions confidently. By revisiting practical exercises and visualizing secure workflows, aspirants develop operational intuition that is directly applicable to examination scenarios and real-world development environments.
Integrating Multi-Service Architectures
One of the most valuable skills to consolidate is the ability to integrate multiple services into cohesive architectures. Candidates should practice combining serverless functions, databases, messaging queues, storage services, and deployment pipelines to construct scalable, resilient systems. Understanding service dependencies, failure points, and optimization opportunities allows candidates to design architectures that are operationally sound and cost-efficient. These exercises reinforce problem-solving intuition and enable candidates to tackle complex scenario-based questions with confidence.
Experiential integration also highlights potential bottlenecks and trade-offs. By simulating real-world architectures, candidates gain insight into balancing latency, throughput, and resource allocation. These exercises enhance analytical thinking and operational judgment, preparing aspirants to select the most effective solutions under examination constraints. Integration practice ultimately cultivates both competence and confidence, essential qualities for excelling in the certification assessment.
Refining Knowledge of Messaging and Event-Driven Workflows
Messaging services and event-driven architectures are commonly examined through scenarios that require practical comprehension. Practicing with SQS, SNS, and Kinesis allows candidates to design robust solutions for decoupled systems, real-time data processing, and automated notifications. Hands-on exercises help visualize message flow, determine optimal queue configurations, and implement event-driven triggers. These practical experiences are invaluable for developing the analytical skills necessary to address complex, multi-service questions in the examination.
Kinesis exercises, in particular, emphasize managing streaming data, handling variable workloads, and integrating with Lambda or storage services. SNS exercises involve designing automated notification workflows, integrating with databases, and triggering downstream processes. By engaging with these services in practical settings, candidates internalize operational patterns, anticipate potential issues, and gain the confidence to apply best practices in both examination scenarios and professional projects.
Final Review of CI/CD and Deployment Practices
Continuous integration and deployment pipelines are an area where meticulous review pays dividends. Candidates should revisit the orchestration of CodeDeploy, CodeBuild, CodeCommit, and CodePipeline, paying attention to configuration, error handling, and rollback mechanisms. Practicing these workflows ensures that candidates understand the sequence of stages, service dependencies, and strategies for maintaining operational continuity. This hands-on review reinforces theoretical knowledge and strengthens practical intuition for solving complex deployment scenarios presented in the examination.
By simulating pipeline execution and troubleshooting failures, candidates gain insight into real-world operational considerations. These exercises enhance analytical reasoning and decision-making skills, ensuring that aspirants are equipped to handle scenario-based questions efficiently and accurately. Reviewing CI/CD workflows one final time consolidates understanding, builds confidence, and prepares candidates for both the examination and practical cloud development challenges.
Simulating Examination Conditions
One of the most effective strategies in final preparation is simulating examination conditions. Candidates should complete timed practice tests that mimic the structure, question complexity, and multi-service scenarios of the official examination. This approach develops time management skills, reduces anxiety, and familiarizes aspirants with the question format. Observing performance under timed conditions also helps identify remaining areas of weakness, providing targeted opportunities for improvement in the final stages of preparation.
Simulated exams also reinforce critical thinking under pressure. By practicing how to analyze scenarios quickly, evaluate alternatives, and select optimal solutions, candidates cultivate the ability to respond effectively to unexpected or complex questions. This strategy ensures that aspirants approach the certification assessment with confidence, composure, and operational insight, reducing the likelihood of errors caused by haste or uncertainty.
Leveraging Documentation and Additional Resources
In the final preparation stage, candidates benefit from reviewing official documentation, FAQs, and whitepapers related to core services. These resources provide deeper insight into service behaviors, limitations, and best practices. By supplementing hands-on practice and scenario reviews with authoritative guidance, candidates reinforce conceptual understanding and gain a more nuanced perspective of AWS service interactions. Engaging with documentation also prepares aspirants to navigate questions that test subtle operational knowledge, which often distinguishes high-performing candidates.
Consulting supplementary resources enhances both theoretical and practical readiness. Candidates can explore edge cases, new service features, and integration patterns that may appear in scenario-based questions. By combining experiential learning, practice tests, and documentation review, aspirants create a comprehensive preparation framework that balances depth of understanding with practical skill.
Cultivating Confidence and Mental Readiness
Final preparation is not only about technical knowledge but also about cultivating mental readiness. Candidates should develop strategies to manage stress, maintain focus, and approach each question methodically. Reviewing workflows, rehearsing scenarios mentally, and visualizing the application of services in practical contexts enhances confidence. By internalizing operational patterns and anticipating examination challenges, candidates reduce anxiety and approach the assessment with a calm, analytical mindset.
Confidence also derives from the breadth and depth of preparation. Hands-on practice, scenario-based exercises, and repeated review ensure that candidates are comfortable with service interactions, operational intricacies, and deployment strategies. This assurance allows aspirants to focus on problem-solving during the examination rather than second-guessing conceptual understanding, which is essential for achieving a high score and demonstrating professional competence.
Conclusion
Preparing for the AWS Certified Developer Associate examination demands a harmonious blend of conceptual understanding, practical experience, and strategic review. Success hinges on the ability to design scalable, resilient, and secure architectures while navigating complex, scenario-based challenges that mimic real-world cloud environments. Candidates benefit from immersing themselves in hands-on exercises that integrate multiple services such as Lambda, DynamoDB, S3, EC2, API Gateway, Step Functions, and CI/CD tools. These exercises cultivate problem-solving intuition, operational judgment, and confidence, ensuring that theoretical knowledge is complemented by practical competence.
Reinforcing serverless workflows, orchestrating pipelines, optimizing storage and compute resources, and implementing identity and access management principles are essential components of comprehensive preparation. Engaging with messaging and event-driven services like SQS, SNS, Kinesis, and Cognito further develops the ability to design applications that are responsive, efficient, and secure. Continuous review of practical scenarios, repeated deployment exercises, and simulated examination conditions allow candidates to internalize operational patterns, anticipate potential pitfalls, and approach complex questions methodically.
Strategic allocation of preparation time, combined with repeated practice and consultation of authoritative documentation, ensures a deep understanding of service behaviors, integration patterns, and deployment strategies. By synthesizing experiential learning with conceptual knowledge, aspirants gain the analytical acuity required to evaluate alternatives, optimize workflows, and implement robust solutions under constrained conditions. Confidence and mental readiness are strengthened through repeated engagement, reflective practice, and visualization of real-world application scenarios.
Ultimately, achieving certification reflects mastery over both the technical and practical dimensions of cloud development. Candidates emerge with the capability to build, deploy, and manage applications effectively, demonstrating not only their understanding of core AWS services but also their proficiency in translating that knowledge into operational excellence. The preparation journey equips aspirants with skills that extend beyond the examination, fostering a professional competence that is directly applicable to cloud-native development and real-world problem solving. By integrating comprehensive review, hands-on experimentation, scenario-based analysis, and strategic practice, candidates ensure that they are thoroughly prepared to succeed in the AWS Certified Developer Associate examination and to excel in professional cloud environments.
AWS Certified Developer - Associate certification practice test questions and answers, training course, study guide are uploaded in ETE files format by real users. Study and pass Amazon AWS Certified Developer - Associate certification exam dumps & practice test questions and answers are the best available resource to help students pass at the first attempt.



