- Home
- Amazon Certifications
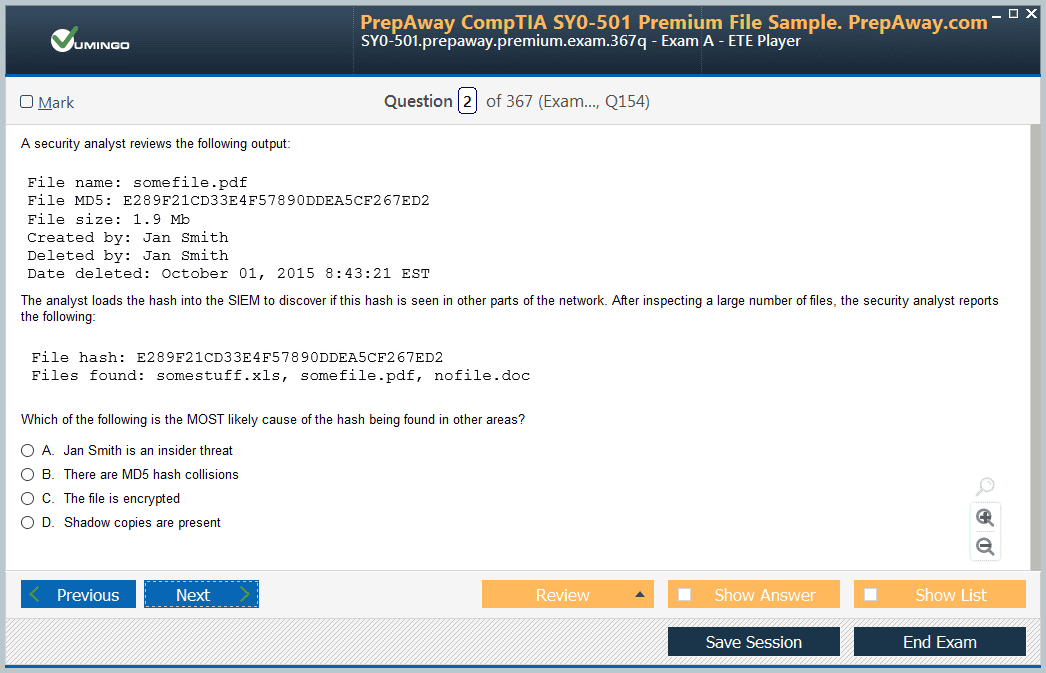
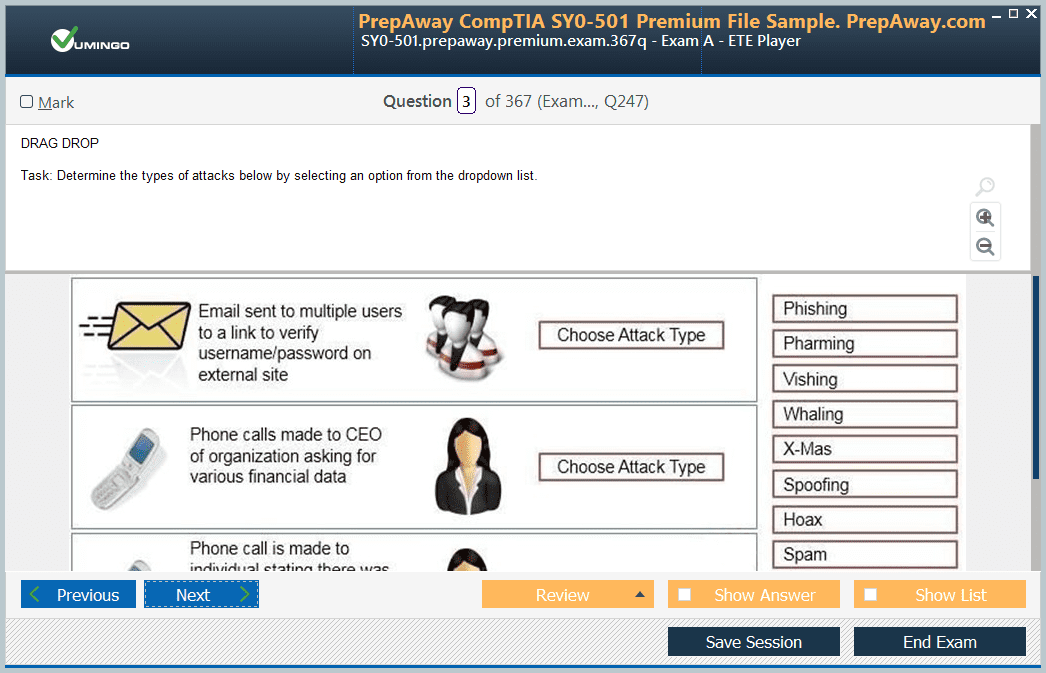
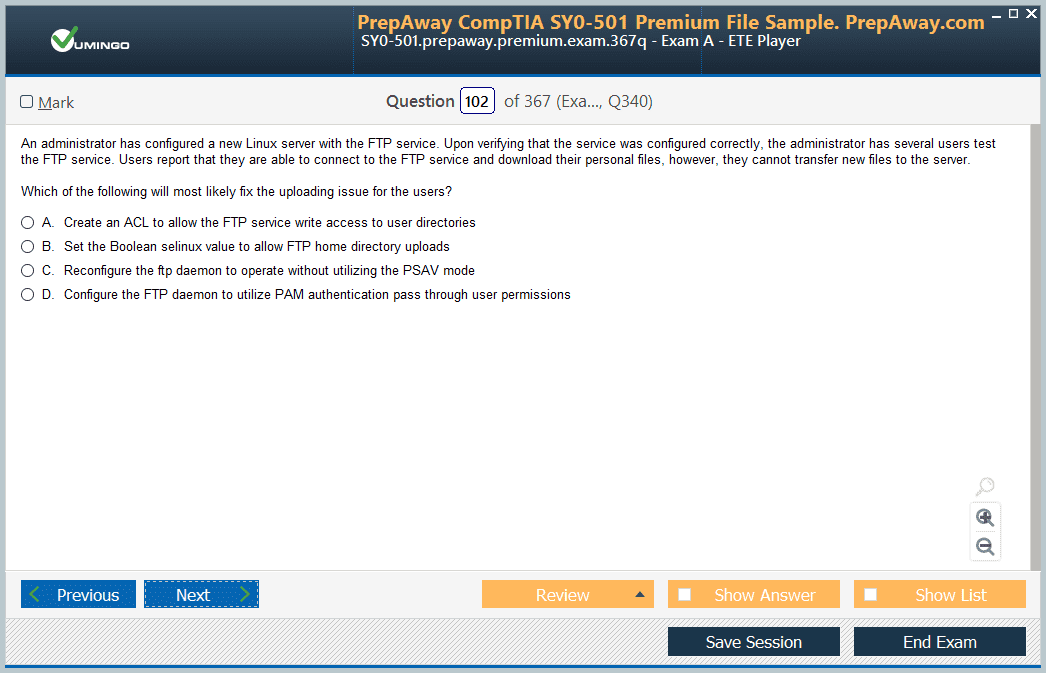
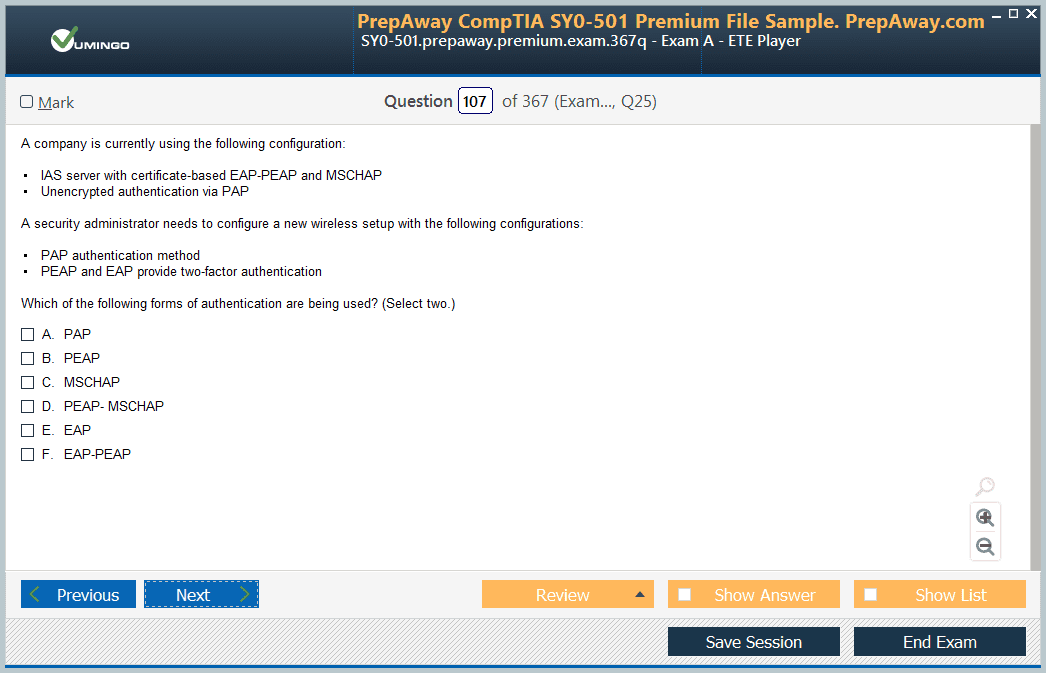
- AWS Certified Data Engineer - Associate DEA-C01 AWS Certified Data Engineer - Associate DEA-C01 Dumps
Pass Amazon AWS Certified Data Engineer - Associate DEA-C01 Exam in First Attempt Guaranteed!
Get 100% Latest Exam Questions, Accurate & Verified Answers to Pass the Actual Exam!
30 Days Free Updates, Instant Download!


AWS Certified Data Engineer - Associate DEA-C01 Premium Bundle
- Premium File 366 Questions & Answers. Last update: Jun 26, 2026
- Training Course 273 Video Lectures
- Study Guide 809 Pages








Last Week Results!

Includes question types found on the actual exam such as drag and drop, simulation, type-in and fill-in-the-blank.

Based on real-life scenarios similar to those encountered in the exam, allowing you to learn by working with real equipment.

Developed by IT experts who have passed the exam in the past. Covers in-depth knowledge required for exam preparation.
All Amazon AWS Certified Data Engineer - Associate DEA-C01 certification exam dumps, study guide, training courses are Prepared by industry experts. PrepAway's ETE files povide the AWS Certified Data Engineer - Associate DEA-C01 AWS Certified Data Engineer - Associate DEA-C01 practice test questions and answers & exam dumps, study guide and training courses help you study and pass hassle-free!
Stream, Store, Scale: DEA-C01 Essentials For Cloud Engineers
Today’s enterprises depend on fast, reliable, and secure data processing pipelines. The DEA‑C01 credential validates mastery in designing data ingestion, transformation, storage, and governance on a cloud platform. The focus extends beyond service familiarity—it emphasizes designing robust ecosystem workflows that align with business objectives, regulatory demands, and performance expectations.
This credential establishes one as an architect who can turn raw data into refined insights, ensuring data flows are modular, resilient, and scalable. Passing the exam demonstrates the ability to combine data engineering best practices with production-grade AWS patterns.
Understanding Domain Distribution And What It Means For Preparation
The exam is structured into four domains with different weightings. Candidates should treat this structure as a strategical compass rather than a checklist. Domain one, covering ingestion and transformation, accounts for more than a third of the exam and therefore deserves the lion’s share of preparation effort. Domains two through four—data store design, operations, and governance—also require deep understanding but are less voluminous in content.
This distribution suggests that proficiency in setting up ETL/ELT pipelines and handling data ingestion formats will deliver the highest ROI during review. A balanced study plan maps effort proportionately across domains while ensuring domain one gets over‑representation in practice.
Exploring Rarely Covered Use Cases In Data Ingestion And Transformation
Most candidates focus on popular ingestion tools—batch ETL, Lambda functions, streaming ingestion—but often miss niche yet critical scenarios. Examples include hybrid ingestion from on‑premise databases, differential ingestion using change data capture, and file normalization workflows.
Understanding intricacies such as handling schema drift in JSON logs, dealing with late‑arriving records in streaming systems, or deduplicating event data using ordering timestamps can be exam differentiators. Preparing these edge cases helps candidates answer scenario questions that involve data integrity, ordering, and fault tolerance.
Designing Storage Architectures For Diverse Use Cases
In the data store management domain, many focus on relational databases or data warehouses but overlook when to use certain storage types. For instance, choosing between columnar, row‑based, or object storage depends not just on cost, but also on query patterns, frequency of access, and expected growth.
Knowledge of partitioning strategies, compaction needs, retention policies, and file format trade‑offs (such as Parquet vs Avro vs CSV) is vital. Candidates should be able to explain when to use managed warehouses versus data lakes, how to optimize performance using compression, and when to implement lifecycle transitions for cost control.
Applying Operational And Support Insight Beyond Monitoring
The operations domain extends beyond simply setting up monitoring dashboards. Advanced candidates demonstrate fault tolerance engineering, recovery procedures, data drift detection, and retraining triggers in pipelines.
Examples include setting up alert logic based on ingestion lag, configuring rollback strategies when transformation fails, and ensuring replayability of pipeline runs. Understanding how to manage data health using automated validation and remediation workflows is often underrepresented but frequently tested.
Addressing Security And Governance From A Policy-first Perspective
Data governance goes beyond encryption and access control. It involves metadata management, lineage tracing, and auditability. Candidates should understand how to implement data catalogs, tag-sensitive fields, enforce encryption in transit and at rest, and ensure compliance with retention or privacy requirements.
Preparing case scenarios where governance policies must enforce location-based storage, access control separation of duties, or retention cycles based on data classification adds depth. Real-world examples of compliance frameworks, anonymization techniques, and audit log structures are often masked within the domain’s subtopics.
Creating A Learning Strategy That Mirrors Data Engineering Workflows
Rather than studying service by service, candidates benefit from building end-to-end pipelines that ingest, store, transform, and govern sample datasets. Building complete mini-projects—such as streaming sensor data ingestion through a data lake, then querying via serverless SQL with governance metadata—offers experiential learning.
This approach reinforces understanding of domain interactions and makes concept recall easier. When studying exam questions, candidates who have performed similar architecting tasks will identify traps and constraints naturally.
Mapping Exam Objectives To Career Transition Skills
DEA‑C01 preparation aligns closely with real-world responsibilities of cloud data engineers. Domain one tasks mirror job responsibilities in building ingestion pipelines, while domain two and three map to storage provisioning and production readiness. Identifying these alignments helps candidates measure their readiness and ensure confidence in both exam and job interviews.
Candidates should map experience from their roles—like configuring lifecycle rules on object storage or tuning query performance in warehouses—to exam objectives. This helps build a narrative that supports both certification success and career progression.
Understanding The Core Responsibilities Of A Certified Data Engineer
Preparing for this certification requires more than just technical memorization. It demands a mindset that revolves around system-wide data flow comprehension, trust, quality assurance, and delivery pipelines that scale under pressure. Every task, whether designing data pipelines or implementing access control, must align with security, performance, and cost efficiency.
The data engineer is expected to deliver data assets in a consumable format, ensure minimal latency, validate transformations, and meet service-level expectations. This role operates at the intersection of infrastructure and analytics.
Deconstructing Domain One: Ingestion And Transformation
This domain carries the most weight, and mastering it requires deep knowledge of ingestion methods, data formats, and transformation logic. Ingestion methods may include batch uploads, event-based streaming, API pull, or real-time sensor streaming.
Scenarios may involve ingesting millions of records per hour from edge devices or log data from distributed web applications. Choosing between pull and push models depends on source systems, latency requirements, and scalability constraints. Candidates should understand how to buffer large data bursts and handle schema evolution gracefully.
Transformation tasks demand a practical understanding of distributed compute models, especially how to optimize resource allocation and throughput. Practical use cases may include normalizing inconsistent fields from CSV files, enriching records with metadata, filtering sensitive data, or aggregating values for time series reporting.
Identifying Tradeoffs In Stream Versus Batch Processing
A common area of confusion involves selecting the correct model—streaming or batch—for a data workload. The choice is influenced by several factors, such as latency tolerance, data volume, source system capabilities, and transformation complexity.
Batch jobs offer consistency and lower compute overhead for less time-sensitive data. Stream processing, however, enables near real-time responsiveness, often at higher architectural and cost complexity. Candidates should be able to recognize when to apply micro-batching or to shift from append-only to windowed transformations based on analytics needs.
They should also be aware of out-of-order data and its implications in time-based aggregations, how watermarking can resolve late-arriving records, and how to enforce deduplication rules for idempotency.
Diving Into Domain Two: Storing Data Efficiently
This domain tests the ability to design durable, performant, and scalable storage solutions. The exam questions are rarely direct—they may reference storage use cases in relation to analytics, lifecycle management, data privacy, or disaster recovery.
Candidates should be able to assess when to use file-based object storage, columnar stores, relational engines, or search indexes. Scenarios often include storage tiering for cost optimization, structuring partitions for high-performance access, and enforcing retention policies.
They must understand how data volume, velocity, and variety influence storage decisions. For instance, storing logs for search is vastly different from storing sales transactions for reporting. Each use case introduces different schema designs, compression needs, and access models.
Planning Partitioning And File Format Selection Strategically
Partitioning is a recurring concept in this domain and is critical for read optimization. Selecting partition keys that reduce scan cost while supporting most query filters is essential. Over-partitioning can cause small file problems and increase overhead, while under-partitioning may slow down queries.
File format also matters. Formats like Parquet and ORC are ideal for analytical workloads due to columnar compression and predicate pushdown. In contrast, JSON or CSV are flexible for ingestion but inefficient for querying. The exam may ask candidates to optimize pipelines for performance and cost using correct file types and schema definitions.
Decoding Domain Three: Automating Pipeline Operations
Operational efficiency is an often overlooked part of data engineering, but in this domain, candidates are expected to show maturity in managing running pipelines.
This includes setting up job retries with exponential backoff, ensuring error isolation, and applying logging strategies that enable traceability across pipeline stages. Infrastructure should be designed for graceful failure, data replay, and alerts that are both actionable and non-intrusive.
Scenarios could involve identifying bottlenecks in scheduled ETL jobs, enabling self-healing data checks, or balancing throughput across parallel workers. Candidates must understand throughput thresholds, memory tuning, worker scaling, and backpressure control.
Building Resilience Into Pipelines
Reliability is paramount in production pipelines. This involves implementing redundancy, checkpointing, transactional consistency, and validation layers. The ability to recover from partial failures without corrupting data or rerunning entire jobs is crucial.
Examples include ensuring once-only delivery, automating rollback when schema mismatches occur, or applying quarantine patterns for records that do not meet validation rules. These designs reduce manual intervention and increase trust in the pipeline.
Candidates should understand concepts such as idempotency, distributed coordination, and orchestration. Tools for lineage tracking and dependency resolution are also relevant to this domain.
Navigating Domain Four: Data Governance And Compliance
Governance questions assess a candidate’s ability to ensure that data is secure, compliant, and traceable. This includes access control, encryption, audit logging, tagging, and classifying datasets by sensitivity or ownership.
Candidates must grasp concepts such as column-level security, row-level masking, object encryption, access boundary enforcement, and multi-tenant access separation. For example, managing data access by region or role requires understanding policy layering.
Compliance often goes beyond encryption. It includes auditability, classification, retention enforcement, and data minimization. Data engineers are expected to work with stewards and architects to ensure that business data is both usable and compliant.
Managing Metadata, Lineage, And Data Quality
Metadata plays a critical role in governance. Candidates should be able to build metadata catalogs, manage schema versions, and support data discovery processes.
Data lineage, or the ability to track how data was transformed and where it was derived from, is central to understanding pipeline behavior, debugging issues, and proving regulatory compliance. Candidates should know how to build end-to-end lineage maps that capture transformation logic, source systems, and output destinations.
Data quality enforcement can be implemented via rule engines, validation layers, or monitoring pipelines. Key metrics include completeness, uniqueness, accuracy, timeliness, and validity. Scenario questions may ask how to isolate corrupted data segments or implement policies to block distribution of inaccurate reports.
Creating A Study Blueprint That Prioritizes Experience
To be truly ready for this certification, candidates must blend reading with implementation. The most effective learning strategy is to build sample projects that mimic real-world patterns.
For ingestion, this could mean building a pipeline that collects event data from simulated sensors. For transformation, it might involve normalizing and enriching semi-structured web logs. For storage, one might compare performance between object storage and columnar database queries. For operations, configuring alerts for ingestion lag. And for governance, creating sample access control policies with traceable audit logs.
Each task solidifies understanding in a tangible way, reinforcing theoretical knowledge with applied engineering.
Avoiding Over-Reliance On Service Documentation
While reading technical documentation is important, the exam favors scenario-based problem-solving over service definitions. Candidates should avoid memorizing configuration details and instead focus on the reasoning behind choices.
For example, understanding why one would choose a stream processor over batch, or how to balance cost versus redundancy in storage, matters more than knowing default retention settings. The ability to weigh trade-offs is key.
Practice should include mock scenarios with multiple valid options and constraints. This forces critical thinking, which is essential for real exam questions.
Reviewing Sample Problems Through Reverse Design
A powerful technique is reverse engineering exam-like questions. Take a business problem—such as ensuring near real-time analytics for global sales transactions—and design the entire data pipeline from ingestion to visualization.
This forces engagement with real constraints: time zones, volume surges, latency expectations, storage cost, compliance. Designing pipelines for these edge cases builds mental agility that will be useful on exam day.
This method improves your ability to identify distractors and uncover the optimal answer in multiple-choice settings, especially when options seem close in viability.
Recognizing Patterns In Common Exam Mistakes
Many candidates fail not because of lack of knowledge, but due to predictable traps. One common mistake is ignoring context in multi-sentence questions. These questions are designed to simulate real-world decision-making where one piece of information shifts the entire solution approach.
Another issue is rushing through scenario-based questions. These require you to analyze not just the technical challenge but also business constraints such as time, budget, or compliance. Skipping or misreading one keyword, such as real-time versus near-real-time, can change the correct answer entirely.
Candidates often overthink easy questions and underthink complex ones. Time management is another common weak point. Spending too long on early questions can cause panic later. The best strategy is to mark uncertain answers for review and revisit them with a clearer head.
Deep Diving Into Advanced Partitioning Logic
Many candidates understand the basics of partitioning, but struggle when faced with real-world partitioning dilemmas. Questions may ask how to avoid small files while still enabling high-performance queries. This requires balancing cardinality, access patterns, and ingestion frequency.
For example, partitioning log files by minute may create excessive metadata and storage overhead, while partitioning by day may reduce performance. The right solution depends on the query filter column, the size of each partition, and the engine used for querying.
Candidates should also understand dynamic partitioning, late-arriving data implications, and how partition evolution affects metadata refresh. Some questions test your ability to prevent partition skew by using hashing or bucketization.
Streamlining Storage Decisions For Cost And Performance
Storage optimization questions may not always be direct. They may ask how to reduce cost while keeping data accessible for a specific use case. For example, storing data for dashboard use versus training machine learning models has vastly different access characteristics.
The exam may present a situation where multiple teams access the same dataset but require different formats. In such cases, duplicating the dataset with different transformations may be the best solution despite higher storage cost. Candidates must balance cost per GB against transformation time, compute needs, and downstream latency.
It is important to understand object lifecycle policies, storage classes, and tiered access strategies. Choosing to archive infrequently accessed data can greatly reduce costs, but if retrieval is needed unexpectedly, the delay and cost may violate business needs.
Applying Governance Models Across Cross-Functional Pipelines
As data pipelines span departments, governance complexity increases. Questions may describe multiple personas needing different levels of access—some needing row-level access, others needing full visibility with redaction.
A strong candidate will understand how to apply fine-grained access controls while maintaining performance and operational simplicity. This includes column masking, role-based access control, policy inheritance, and audit enforcement across multiple storage layers.
Candidates should be able to suggest solutions that allow developers to work on test data while masking sensitive fields like personal identifiers or financial records. Designing permission layers that evolve with organizational changes is a high-level skill often reflected in complex scenarios.
Integrating Lineage Tracking And Quality Assurance Seamlessly
While lineage and quality are often discussed separately, in real-world environments they are deeply linked. The exam may include cases where identifying the source of corrupted data or tracing a transformation error is critical.
Candidates must demonstrate understanding of tools and frameworks that support lineage capture across batch and streaming jobs. More importantly, they should know how to embed lineage metadata into their architecture without creating performance bottlenecks.
Quality checks should not be an afterthought. They must be part of the pipeline itself. This includes schema validation, null handling, threshold alerts, duplication checks, and logic for error redirection. The ability to isolate, tag, and reprocess invalid records is a key marker of pipeline maturity.
Building Idempotent And Fault-Tolerant Data Pipelines
Idempotency means a pipeline can be run multiple times without changing the result. This is crucial in production systems where retries are common due to intermittent failures. The DEA-C01 exam may ask how to enforce idempotency in data ingestion and transformation stages.
Solutions may include using unique keys to prevent duplicates, writing to staging areas before final destinations, or implementing commit markers for batch jobs. Candidates should also understand fault domains—if a worker fails mid-run, how is data restored without duplication or loss?
Error handling questions may ask about retry mechanisms, exponential backoff, and fallback options. Graceful degradation, checkpointing, and replayability are patterns that must be understood in depth.
Mastering Schema Evolution And Data Format Compatibility
Real-world data pipelines rarely deal with static schemas. Fields are added, data types change, and optionality is introduced. Candidates must be fluent in handling schema evolution during ingestion and transformation.
Some questions may involve deciding between permissive and strict schema modes. For example, when receiving third-party data feeds, a strict mode may reject records and stop processing, while a permissive mode will continue but may lead to downstream quality issues.
The exam may test format compatibility such as reading JSON with missing fields or converting nested structures into flattened tables. Understanding backward and forward compatibility rules in serialization formats like Avro or Parquet is also important.
Monitoring Pipelines For Early Warning And Capacity Trends
The ability to monitor and alert on pipeline health is essential. Candidates should understand how to track key performance indicators such as processing lag, failure rate, data volume trends, and cost spikes.
Scenarios may involve detecting unusual drops in data arrival, spotting latency buildups in windowed aggregations, or identifying memory pressure on stream processors. Effective monitoring requires metrics, logs, and traces, each providing different insights.
A robust strategy includes setting up dashboards for operational visibility and alerts that are specific enough to reduce noise but general enough to catch anomalies. Historical trend analysis also helps with capacity planning and budget forecasting.
Optimizing Jobs For Scalability And Latency
Performance tuning is not limited to choosing the right compute size. It involves understanding how data is partitioned, how shuffle operations impact throughput, how serialization affects CPU, and how input size dictates parallelism.
The exam may present symptoms such as high processing latency or intermittent job crashes. Candidates must diagnose the likely cause and suggest architectural improvements. This could involve re-partitioning datasets, increasing parallel worker count, reusing broadcast variables, or adjusting window sizes in stream jobs.
Understanding the difference between horizontal and vertical scaling, batch versus micro-batch tuning, and caching intermediate results can make a difference in complex scenarios.
Prioritizing Real-World Application Over Memorization
DEA-C01 is not a theoretical exam. It rewards candidates who demonstrate practical knowledge over rote learning. Being able to explain why a design works, and how it scales, is more valuable than memorizing limits or defaults.
Projects that simulate cross-functional collaboration—where ingestion, transformation, storage, monitoring, and governance are all implemented—provide a clearer learning path. Candidates should evaluate multiple approaches to the same problem and note tradeoffs.
Avoid falling into the trap of reading until the last day. Instead, focus on solving real data engineering problems and documenting learnings. Each hands-on experience enhances decision-making ability under pressure.
Building Confidence Through Iterative Learning
The most effective learners adopt a looped process: read, build, break, fix, reflect. Each cycle improves intuition, exposes assumptions, and builds long-term retention.
Set up personal challenges such as ingesting 1 million records per minute, implementing schema validation on semi-structured data, or designing multi-region access controls. These exercises simulate stress points you will encounter in production or the exam.
Confidence is not built from perfect performance but from recovering effectively after failure. Candidates who embrace errors as learning opportunities tend to outperform those who fear making mistakes.
Using The DEA-C01 Framework For Career Growth
This certification is not just a badge—it is a framework for data engineering maturity. Whether you are designing internal reporting systems, managing global data lakes, or building ML pipelines, the principles covered here will apply.
Employers seek engineers who can create trustworthy, scalable, and resilient systems. The knowledge gained while preparing for DEA-C01 proves your ability to think holistically, prioritize quality, and implement cost-effective designs.
Use your preparation journey to create a portfolio of solutions. Showcase your work, document your architecture choices, and share your learnings. This not only reinforces your expertise but also makes you stand out in job interviews or technical evaluations.
Understanding The Post-Certification Landscape
Once the DEA-C01 certification is achieved, it becomes a foundation rather than a final milestone. Many certified professionals face the question of what comes next. The immediate next steps usually involve applying the skills in real-world projects, mentoring others, or contributing to architectural decisions.
The certification alone does not guarantee mastery. Its true value is unlocked when applied to live scenarios involving multiple stakeholders, unknown variables, and production constraints. Candidates must evolve from task execution to solution design and impact measurement.
Another shift is in mindset. Certified professionals are expected to anticipate challenges, proactively address data issues, and align solutions with business goals. This maturity distinguishes senior data engineers from entry-level practitioners.
Reinforcing Core Concepts Through System Ownership
One of the best ways to solidify DEA-C01 knowledge is by taking ownership of a complete data system. This could be an internal ETL pipeline, a reporting layer, or a data quality framework. Ownership brings visibility into edge cases, long-term behavior, and stakeholder feedback.
Designing a system from scratch is different from maintaining one. It forces trade-offs around batch versus stream, real-time versus eventual consistency, and compliance versus performance. These decisions reflect real DEA-C01 scenarios where textbook solutions often need adaptation.
Being accountable for outcomes builds confidence and sharpens problem-solving. It also creates documentation, automation, and reusable frameworks that benefit the entire organization.
Evolving From Pipeline Builder To Data Strategist
As career progression occurs, the role shifts from building data pipelines to enabling data ecosystems. A strategist views data assets as products, with defined lifecycles, user personas, and feedback loops.
Instead of simply ingesting raw data and pushing it into storage, a strategist evaluates usability, latency, lineage, and cost. They coordinate with analytics, machine learning, governance, and security teams. This cross-functional mindset aligns with the broader competencies covered in DEA-C01.
The exam serves as an initiation into this thinking. It encourages candidates to consider data observability, policy enforcement, and reusability from day one. In practice, the strategist role involves mentoring, cross-team architecture reviews, and long-term data planning.
Navigating Emerging Trends In Data Engineering
Data engineering is evolving rapidly. Staying relevant requires awareness of changes in technology, methodology, and business expectations. One trend is the rise of real-time analytics, where stream processing is becoming the default rather than the exception.
This requires fluency in event-driven architecture, stream joins, stateful processing, and watermarking. Engineers must understand latency implications and the trade-offs between completeness and speed. DEA-C01 preparation lays the groundwork for this mindset by encouraging design thinking for both batch and stream jobs.
Another trend is the integration of machine learning into data pipelines. Data engineers are increasingly expected to prepare features, manage model versions, and monitor drift. Those who build pipelines that serve both analytics and machine learning workloads are in high demand.
Finally, there is growing emphasis on data contracts, schema enforcement, and change management. Modern platforms prioritize stability and backward compatibility, making version control and observability critical.
Embracing The Shift Toward Data-as-a-Product
The concept of treating data as a product transforms how pipelines are designed and maintained. Instead of optimizing solely for throughput, engineers now consider discoverability, documentation, reliability, and self-service usability.
This requires building interfaces that allow analysts, scientists, and business users to understand what data is available, how fresh it is, and what guarantees it provides. DEA-C01 indirectly promotes this by covering metadata, schema evolution, and access control in depth.
Ownership and accountability become more important. If a dataset breaks, users want to know who is responsible, when it will be fixed, and what the remediation plan is. These are not traditional concerns in development roles but are critical for enterprise-grade data engineering.
Designing For Scalability Beyond Volume
Scalability is often misunderstood as handling large data volumes. In reality, true scalability includes handling many datasets, many consumers, frequent schema changes, and dynamic business needs.
The DEA-C01 exam focuses on scalable architecture, but applying that knowledge means building systems that tolerate growth in complexity, not just size. Examples include:
Building modular pipelines where each stage can be updated independently
Allowing metadata-driven orchestration so new datasets can be added without code changes
Supporting backward-compatible schema changes through versioning or shims
Scaling access control to hundreds of users with varying roles
This mindset enables organizations to move faster without breaking existing systems or violating compliance.
Applying Certification Knowledge To Cross-Team Collaboration
Certified professionals are expected to bridge gaps between engineering, analytics, operations, and compliance. This involves translating business requirements into scalable pipelines, explaining technical constraints to stakeholders, and aligning with long-term data strategies.
DEA-C01 content promotes this by asking scenario-based questions that involve trade-offs, stakeholder priorities, and operational limits. In real-world teams, these skills manifest through:
Participating in data governance committees
Leading architectural reviews
Contributing to platform decisions on storage, orchestration, and cataloging
Advocating for reusability and cost efficiency in team discussions
Strong communication and documentation skills often matter more than technical depth alone at this level.
Investing In Observability And Automation As Strategic Assets
Observability and automation are no longer optional. They are foundational components of resilient and efficient data systems. Observability includes monitoring, alerting, tracing, and anomaly detection. Automation includes orchestration, testing, rollback, and recovery.
Professionals who pass the DEA-C01 should prioritize building or improving:
End-to-end data pipeline dashboards
Automated data quality checks before transformation stages
Alerting rules that balance sensitivity with signal-to-noise ratio
Automated rollback in case of schema mismatch or data loss
Over time, these tools reduce firefighting, improve team velocity, and protect data trust.
Staying Ahead Through Thoughtful Experimentation
Continuous learning does not require formal courses. Often, the best insights come from trying new ideas in sandbox environments. Certified engineers can explore:
Building synthetic datasets to test extreme scenarios
Simulating schema drift in streaming systems
Implementing zero-downtime deployments for batch pipelines
Prototyping time travel and versioning for data lakes
Creating multi-tenant access policies for shared environments
These experiments deepen understanding, reveal unexpected behavior, and prepare engineers for unusual real-world challenges.
Cultivating The Habit Of Documentation And Knowledge Sharing
Documentation is a force multiplier. Certified professionals should develop the habit of writing design documents, decision logs, architecture diagrams, and post-mortem reports. This practice ensures continuity, transparency, and alignment.
Knowledge sharing through brown-bag sessions, code walkthroughs, and pipeline audits improves team resilience. It also creates a feedback loop where assumptions are tested, and hidden dependencies are exposed.
In many cases, the documentation becomes the single source of truth that helps onboard new team members or defend architectural decisions during audits.
Expanding Impact Through Mentorship And Community Contribution
Experienced data engineers can multiply their impact by mentoring junior engineers, contributing to design reviews, or supporting open-source communities. Mentorship reinforces concepts, sharpens communication skills, and builds credibility.
Certified engineers are well-positioned to lead internal bootcamps or learning cohorts. These initiatives build a learning culture, reduce the ramp-up time for new hires, and create alignment around best practices.
Participation in broader communities—whether by writing, speaking, or contributing code—also helps engineers stay current with emerging trends, patterns, and tooling.
Measuring Progress Using Real-World Metrics
Professional growth is best tracked through real-world outcomes, not just certifications. Useful metrics include:
Reduction in pipeline failure rate
Increase in data freshness or availability
Faster time-to-insight for stakeholders
Fewer escalations related to data quality
Higher reusability of pipeline components
These outcomes prove maturity and highlight areas for further investment. A strong DEA-C01 foundation makes these improvements easier to design and track.
Designing For Flexibility, Not Just Performance
Systems that are fast but brittle rarely survive long in production. Flexibility means being able to add new use cases, change schemas, reprocess data, and recover from errors without major redesign.
DEA-C01 promotes flexible architectures that separate compute from storage, use metadata-driven transformations, and support auditability. Practicing these patterns results in systems that adapt to growth rather than collapse under change.
Engineers who prioritize flexibility build platforms that reduce technical debt and enable long-term agility.
Final Words
Achieving the AWS Certified Data Engineer – Associate certification is more than a personal milestone—it's an entry point into a complex and ever-evolving discipline. The real value lies not just in earning the credential but in applying its concepts to build resilient, scalable, and future-ready data systems. This certification cultivates a mindset rooted in design thinking, data responsibility, and cross-functional collaboration.
Data engineers today are no longer just pipeline builders. They are system architects, quality enforcers, observability advocates, and strategic contributors to business outcomes. The DEA-C01 framework introduces these themes, but it’s through real-world application, continuous learning, and reflective experimentation that professionals truly grow. Those who leverage their certification to mentor others, lead initiatives, and drive data maturity within their organizations elevate their impact far beyond technical implementation.
Long-term success comes from adaptability—embracing new tools, evolving with business needs, and navigating ambiguity with clarity and structure. Certification is the catalyst, but your ability to stay curious, document rigorously, share knowledge generously, and build with empathy defines your trajectory. As the data engineering field continues to mature, certified professionals who embody these values will be at the forefront of innovation and change.
Amazon AWS Certified Data Engineer - Associate DEA-C01 practice test questions and answers, training course, study guide are uploaded in ETE Files format by real users. Study and Pass AWS Certified Data Engineer - Associate DEA-C01 AWS Certified Data Engineer - Associate DEA-C01 certification exam dumps & practice test questions and answers are to help students.
- AWS Certified Generative AI Developer - Professional AIP-C01
- AWS Certified Solutions Architect - Associate SAA-C03
- AWS Certified Solutions Architect - Professional SAP-C02
- AWS Certified AI Practitioner AIF-C01
- AWS Certified Cloud Practitioner CLF-C02
- AWS Certified Security - Specialty SCS-C03
- AWS Certified Machine Learning Engineer - Associate MLA-C01
- AWS Certified CloudOps Engineer - Associate SOA-C03
- AWS Certified DevOps Engineer - Professional DOP-C02
- AWS Certified Advanced Networking - Specialty ANS-C01
- AWS Certified Data Engineer - Associate DEA-C01
- AWS Certified Developer - Associate DVA-C02
- AWS Certified Security - Specialty SCS-C02
- AWS Certified SysOps Administrator - Associate - AWS Certified SysOps Administrator - Associate (SOA-C02)
Purchase AWS Certified Data Engineer - Associate DEA-C01 Exam Training Products Individually
Why customers love us?
What do our customers say?
The resources provided for the Amazon certification exam were exceptional. The exam dumps and video courses offered clear and concise explanations of each topic. I felt thoroughly prepared for the AWS Certified Data Engineer - Associate DEA-C01 test and passed with ease.
Studying for the Amazon certification exam was a breeze with the comprehensive materials from this site. The detailed study guides and accurate exam dumps helped me understand every concept. I aced the AWS Certified Data Engineer - Associate DEA-C01 exam on my first try!
I was impressed with the quality of the AWS Certified Data Engineer - Associate DEA-C01 preparation materials for the Amazon certification exam. The video courses were engaging, and the study guides covered all the essential topics. These resources made a significant difference in my study routine and overall performance. I went into the exam feeling confident and well-prepared.
The AWS Certified Data Engineer - Associate DEA-C01 materials for the Amazon certification exam were invaluable. They provided detailed, concise explanations for each topic, helping me grasp the entire syllabus. After studying with these resources, I was able to tackle the final test questions confidently and successfully.
Thanks to the comprehensive study guides and video courses, I aced the AWS Certified Data Engineer - Associate DEA-C01 exam. The exam dumps were spot on and helped me understand the types of questions to expect. The certification exam was much less intimidating thanks to their excellent prep materials. So, I highly recommend their services for anyone preparing for this certification exam.
Achieving my Amazon certification was a seamless experience. The detailed study guide and practice questions ensured I was fully prepared for AWS Certified Data Engineer - Associate DEA-C01. The customer support was responsive and helpful throughout my journey. Highly recommend their services for anyone preparing for their certification test.
I couldn't be happier with my certification results! The study materials were comprehensive and easy to understand, making my preparation for the AWS Certified Data Engineer - Associate DEA-C01 stress-free. Using these resources, I was able to pass my exam on the first attempt. They are a must-have for anyone serious about advancing their career.
The practice exams were incredibly helpful in familiarizing me with the actual test format. I felt confident and well-prepared going into my AWS Certified Data Engineer - Associate DEA-C01 certification exam. The support and guidance provided were top-notch. I couldn't have obtained my Amazon certification without these amazing tools!
The materials provided for the AWS Certified Data Engineer - Associate DEA-C01 were comprehensive and very well-structured. The practice tests were particularly useful in building my confidence and understanding the exam format. After using these materials, I felt well-prepared and was able to solve all the questions on the final test with ease. Passing the certification exam was a huge relief! I feel much more competent in my role. Thank you!
The certification prep was excellent. The content was up-to-date and aligned perfectly with the exam requirements. I appreciated the clear explanations and real-world examples that made complex topics easier to grasp. I passed AWS Certified Data Engineer - Associate DEA-C01 successfully. It was a game-changer for my career in IT!


