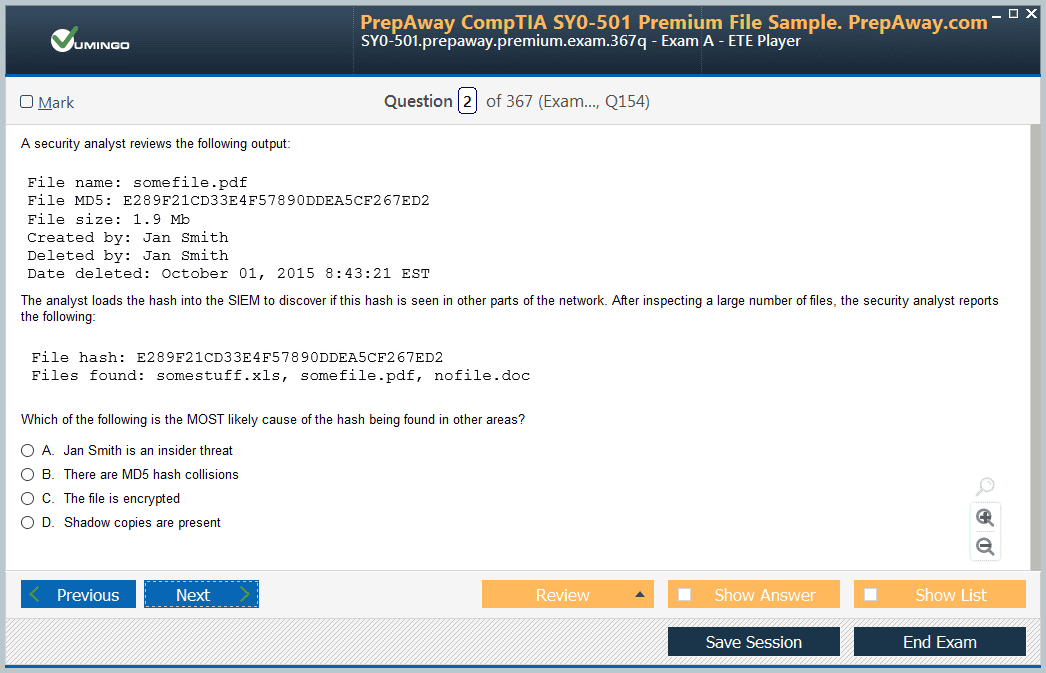
- Home
- Databricks Certifications
- Certified Data Engineer Associate Certified Data Engineer Associate Dumps
Pass Databricks Certified Data Engineer Associate Exam in First Attempt Guaranteed!
Get 100% Latest Exam Questions, Accurate & Verified Answers to Pass the Actual Exam!
30 Days Free Updates, Instant Download!


Certified Data Engineer Associate Premium Bundle
- Premium File 225 Questions & Answers. Last update: Jun 26, 2026
- Training Course 38 Video Lectures
- Study Guide 432 Pages








Last Week Results!

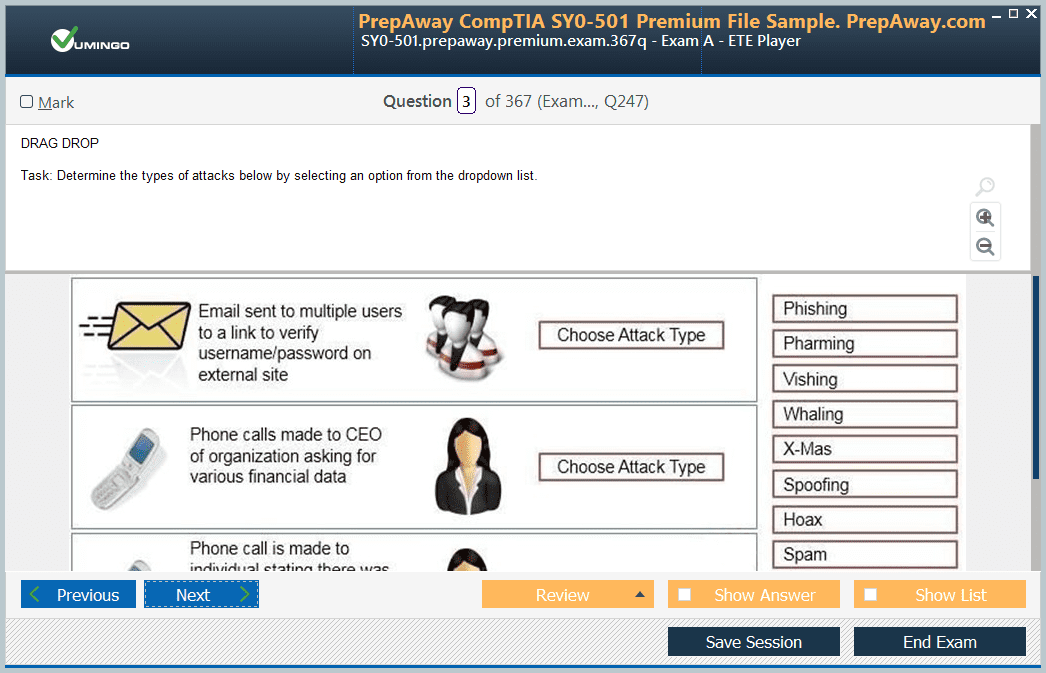
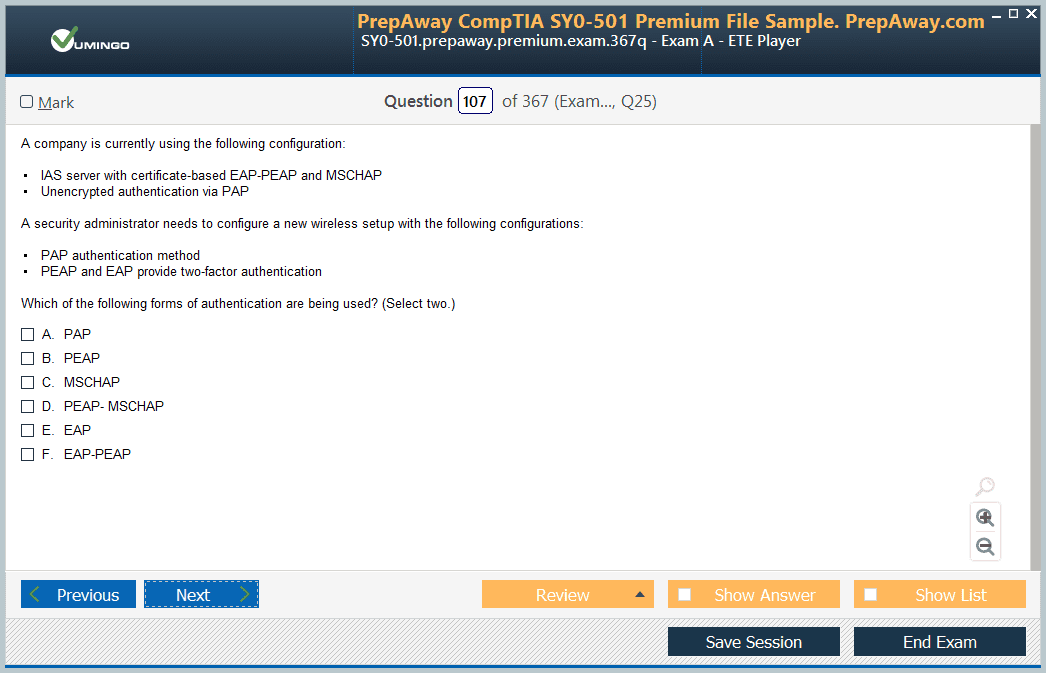
Includes question types found on the actual exam such as drag and drop, simulation, type-in and fill-in-the-blank.

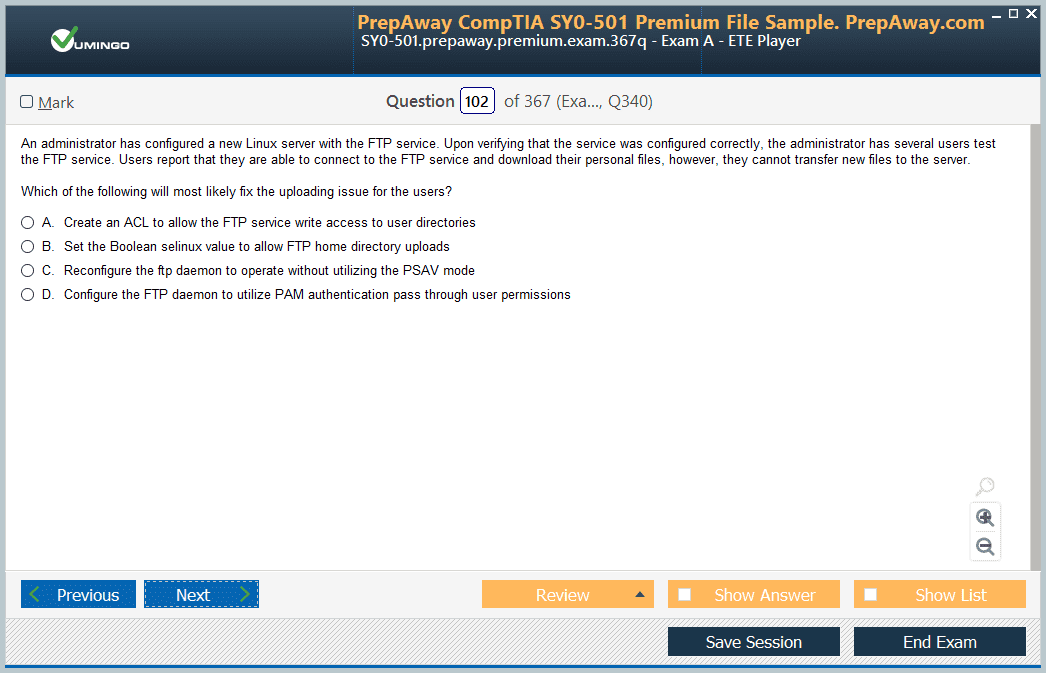
Based on real-life scenarios similar to those encountered in the exam, allowing you to learn by working with real equipment.

Developed by IT experts who have passed the exam in the past. Covers in-depth knowledge required for exam preparation.
All Databricks Certified Data Engineer Associate certification exam dumps, study guide, training courses are Prepared by industry experts. PrepAway's ETE files povide the Certified Data Engineer Associate Certified Data Engineer Associate practice test questions and answers & exam dumps, study guide and training courses help you study and pass hassle-free!
AWS Data Engineer Associate Certification: Exam Preparation Simplified
The field of data engineering is evolving rapidly, creating a surge in demand for skilled professionals. Job listings for data engineers are projected to increase by 45 percent globally, and over the next ten years, this growth is expected to continue at a rate of 28 percent. This rising demand provides an excellent opportunity for individuals to enter a field that combines analytical skills, programming expertise, and cloud technology knowledge. Among cloud platforms, AWS offers a comprehensive set of tools for data engineering, and certification as an AWS Data Engineer Associate demonstrates proficiency in these tools.
AWS Data Engineers require a strong understanding of architectural principles, the ability to implement data pipelines, and programming skills that allow them to interact with large datasets efficiently. While some professionals pursue careers in data engineering intentionally, others may find themselves transitioning into this field because of emerging opportunities in cloud computing and analytics. The AWS Data Engineer Associate certification, designated as DEA-C01, validates the capability to work with AWS data services, manage data operations, optimize costs, and apply industry best practices.
Data engineers are primarily responsible for designing, building, and maintaining cloud-based data architectures. They ensure that applications run efficiently, data pipelines are robust, and performance is optimized. The increasing complexity and volume of data in modern organizations have made this role critical. The DEA-C01 certification allows candidates to showcase their knowledge in handling various AWS services related to ingestion, transformation, storage, and processing of data while demonstrating operational skills in monitoring, troubleshooting, and optimizing workloads.
This exam is particularly valuable for those interested in converting raw data into actionable insights using AWS technologies. Being among the first to achieve this certification positions candidates competitively in the job market and provides credibility when applying for data engineering roles that involve cloud-based infrastructure. Preparation for the DEA-C01 exam requires both theoretical understanding and hands-on experience, combining knowledge of core AWS services, programming languages, and data engineering principles.
Understanding the DEA-C01 Exam Domains
The DEA-C01 exam is structured around four key domains, each representing a specific portion of the exam weight. Familiarity with these domains allows candidates to allocate study time effectively and focus on areas that carry the most significance. Understanding the structure of the exam is the first step toward a successful preparation strategy.
Data Ingestion and Transformation
Data ingestion and transformation constitute the largest portion of the exam, accounting for 34 percent of the total syllabus. This domain tests the ability to collect data from multiple sources, transform it into usable formats, and prepare it for downstream analytics. Data ingestion includes batch processing, streaming data, and integration with various AWS services. Transformation involves cleaning, structuring, and optimizing data to meet analytical requirements.
To master this domain, it is essential to understand the tools and services available for ingestion and transformation within the AWS ecosystem. Practicing real-world scenarios, such as collecting data from IoT devices, social media streams, or transactional databases, helps in applying theoretical knowledge. Hands-on experience with tools like AWS Glue, Lambda, Kinesis, and managed streaming services is critical. Candidates should dedicate significant study time, ideally 40 to 45 hours, to cover all aspects of ingestion methods, transformation pipelines, error handling, and performance optimization techniques.
Management of Data Stores
The second domain, management of data stores, represents 26 percent of the exam content. This domain assesses the ability to design and maintain efficient storage solutions in AWS, including relational databases, NoSQL stores, data lakes, and warehouses. Understanding data modeling, schema design, indexing, and query optimization iscrucial for ensuring performance and scalability.
A comprehensive preparation plan for this domain should include studying the characteristics of different storage options, understanding cost implications, and learning best practices for high availability and data durability. Using AWS services like Redshift, DynamoDB, S3, and Lake Formation in practical exercises helps reinforce concepts and provides confidence in solving real-world scenarios. Allocating approximately 30 to 35 hours to this domain ensures thorough coverage and proficiency.
Support and Data Operations
Support and data operations account for 22 percent of the exam syllabus. This domain focuses on maintaining data pipelines, monitoring performance, handling failures, and troubleshooting issues within AWS data environments. Data engineers must be proficient in identifying operational bottlenecks, automating routine tasks, and ensuring the reliability of systems.
Candidates should practice creating automated monitoring systems, setting alerts, and using logging mechanisms to detect and resolve operational issues. Understanding AWS CloudWatch, CloudTrail, and event-driven workflows is essential. Planning 20 to 25 hours of focused study time allows for an in-depth grasp of operational procedures and problem-solving strategies that are often tested in the exam.
Data Governance and Security
The final domain, data governance and security, constitutes 18 percent of the exam. This domain evaluates knowledge of data privacy, encryption, access control, and compliance requirements. AWS provides various services and features to ensure secure and compliant data handling, including IAM roles, encryption keys, audit logging, and data classification mechanisms.
Candidates should familiarize themselves with AWS security best practices, industry standards for compliance, and methods to implement data governance frameworks. Understanding concepts like encryption at rest and in transit, access policies, data lifecycle management, and audit trails is critical. Allocating 15 to 20 hours of focused study ensures that candidates are well-prepared to address security and governance scenarios in the exam.
Structured Study Approach
A structured learning plan is key to passing the AWS Data Engineer Associate exam. Candidates must balance theoretical learning, hands-on practice, and revision to achieve success. Understanding the domains, allocating study time effectively, and following a disciplined approach improveknowledge retention and exam readiness.
Exploring the official AWS Data Engineer Associate study guide is the first step. The guide provides details about the exam objectives, format, and key concepts. Familiarity with these details allows candidates to identify areas requiring greater focus and prepare efficiently. Once the theoretical understanding is established, practical exposure becomes crucial.
Planning a study schedule helps manage preparation time while balancing personal and professional commitments. Dividing the syllabus into smaller sections and allocating dedicated time for each domain ensures consistent progress. Regular study sessions, ideally spread across several weeks, allow for gradual learning, revision, and reinforcement of concepts. Adjusting the schedule based on progress and understanding is essential to maintain effectiveness and avoid burnout.
Candidates should also explore AWS services in depth. Starting from cloud computing fundamentals, gaining programming proficiency in languages such as Python and SQL, and understanding data analytics concepts provides a strong foundation. AWS-specific services such as S3, EC2, Lambda, Glue, Redshift, Kinesis, and Lake Formation should be studied thoroughly to gain hands-on expertise.
Practical exposure through real-world projects and labs helps solidify knowledge. Candidates can simulate data pipelines, process streaming and batch data, monitor workloads, and implement security measures. Engaging in hackathons or sandbox environments allows for experimentation and application of skills under realistic conditions.
Practical Preparation for AWS Data Engineer Associate Certification
Passing the AWS Data Engineer Associate exam requires a combination of theoretical understanding and practical experience. Developing hands-on expertise is essential because the exam assesses not only conceptual knowledge but also the ability to implement and manage data solutions on AWS. Candidates must engage with the platform directly, perform real-world tasks, and understand the nuances of various AWS services.
Practical preparation begins with creating a cloud environment where experiments can be conducted safely. Setting up test accounts or sandbox environments allows candidates to explore services without risking production data. Using sample datasets, candidates can practice building data pipelines, executing transformations, and monitoring workloads. Hands-on exercises reinforce theoretical knowledge and build the confidence needed to tackle scenario-based exam questions.
Understanding the architecture of AWS data services is a critical aspect of practical preparation. Candidates must learn how services interact, how data flows through pipelines, and how to optimize performance. For example, designing a pipeline that ingests raw data, transforms it using AWS Glue, stores it in Redshift, and visualizes it using QuickSight provides an end-to-end understanding of data engineering workflows. Implementing these workflows in practice ensures familiarity with service limitations, configuration options, and best practices.
Practical exercises should cover data ingestion from multiple sources. This includes batch processing from databases, real-time streaming data from IoT devices, or logs from applications. Candidates need to understand how to use AWS Kinesis for streaming data, how to configure Firehose for delivery to S3 or Redshift, and how to handle errors or retries. Mastery of ingestion techniques ensures that candidates can implement scalable and reliable pipelines under real-world conditions.
Data transformation skills are equally important. AWS Glue provides a serverless environment for extracting, transforming, and loading data. Candidates should practice writing ETL scripts, optimizing transformations, and managing job scheduling. Understanding Glue DataBrew for visual transformations and working with schema evolution enhances practical knowledge. Hands-on experience helps candidates anticipate issues such as data type mismatches, malformed records, and performance bottlenecks.
Managing data stores effectively requires hands-on practice with relational, NoSQL, and data lake solutions. Amazon Redshift allows candidates to build optimized data warehouses, practice SQL queries, and configure distribution styles. DynamoDB provides experience with NoSQL storage, indexing strategies, and throughput configuration. S3 as a data lake requires understanding bucket policies, lifecycle management, and cost optimization. Practicing with these services allows candidates to implement secure, scalable, and efficient storage solutions.
Security and governance form a critical part of practical preparation. Candidates must implement encryption at rest and in transit, configure IAM roles and policies, and ensure compliance with best practices. Practical exercises include setting up access control for different roles, enabling audit logging, and applying data masking or classification techniques. Experiencing real-world security scenarios strengthens readiness for exam questions related to governance and compliance.
Performance monitoring and operational excellence are vital aspects of preparation. AWS provides tools like CloudWatch, CloudTrail, and AWS Config to monitor pipelines, track changes, and detect anomalies. Candidates should practice creating alarms, dashboards, and automated remediation scripts. This hands-on experience enables them to respond effectively to performance degradation, resource contention, and pipeline failures. Simulating failure scenarios improves problem-solving skills and prepares candidates for scenario-based exam questions.
Leveraging Online Courses and Training Resources
While hands-on experience is critical, structured online courses can provide guidance, organization, and additional insights. Online courses are particularly useful for beginners who need to build foundational knowledge before tackling practical exercises. They often provide curated content, sample questions, labs, and project-based exercises.
Courses focusing specifically on AWS Data Engineering cover key services, best practices, and exam-specific strategies. Candidates gain access to video tutorials, practice questions, and lab environments to apply theoretical knowledge. These courses also provide tips on exam strategy, including time management, understanding question patterns, and identifying high-weighted domains.
Even experienced professionals can benefit from online courses, especially to fill gaps in knowledge. Many courses include advanced topics such as optimizing data pipelines, implementing serverless architectures, and managing large-scale data processing. Combining self-study, online courses, and practical exercises ensures comprehensive preparation.
Candidates should also consider supplementing structured courses with independent learning. AWS documentation, whitepapers, and tutorials provide detailed technical references. Engaging with blogs, webinars, and forums offers additional perspectives and real-world use cases. Continuous learning ensures familiarity with service updates, emerging technologies, and evolving best practices, which can be beneficial for the exam.
Strengthening Foundational Knowledge
Before diving deep into AWS services, candidates must strengthen their foundation in data engineering principles, programming, and cloud computing. Understanding these basics reduces confusion and enhances the ability to apply concepts effectively.
Cloud computing fundamentals form the core foundation. Candidates should understand the characteristics of cloud services, deployment models, and key AWS concepts such as regions, availability zones, VPCs, and identity management. Familiarity with storage options, computing resources, and network architecture provides the context needed for designing efficient data solutions.
Programming skills are essential for implementing pipelines, automating tasks, and transforming data. Python is widely used for scripting, interacting with AWS services, and managing ETL processes. SQL is required for querying relational databases, performing aggregations, and generating insights. Candidates should practice writing scripts that connect to AWS services, perform transformations, and handle errors gracefully.
Data analytics concepts are equally important. Understanding statistics, data modeling, and analytical workflows enables candidates to design pipelines that meet business requirements. Knowledge of data visualization, reporting, and aggregation techniques ensures that transformed data can be used effectively for decision-making. Practicing these concepts in a cloud environment enhances practical skills and prepares candidates for scenario-based questions.
Mastery of Key AWS Services
AWS provides a wide array of services tailored for data engineering. Mastery of these services is critical to passing the Data Engineer Associate exam. Candidates must understand service features, configuration options, limitations, and best practices.
S3 serves as the foundational storage service for data lakes, backups, and staging areas. Candidates should practice creating buckets, configuring policies, setting lifecycle rules, and managing access control. Understanding cost implications, versioning, and object-level permissions ensures efficient storage management.
Redshift provides a fully managed data warehouse environment. Practical exercises include creating clusters, defining schemas, loading data, writing queries, and optimizing performance through distribution and sort keys. Working with Redshift enhances skills in analytics, data modeling, and reporting.
Glue offers serverless ETL capabilities. Candidates should practice creating jobs, writing scripts, configuring triggers, and monitoring execution. Knowledge of Glue Data Catalog for metadata management, DataBrew for visual transformations, and integration with other AWS services ensures end-to-end pipeline design capability.
Kinesis enables real-time data streaming. Hands-on practice includes configuring Kinesis Data Streams, Firehose delivery, and using Lambda for processing. Managing throughput, partitioning, and error handling ensures robust streaming pipelines. Understanding Kafka integration and Flink processing further strengthens readiness for real-world scenarios.
EventBridge supports event-driven architectures. Candidates should learn to create rules, configure event buses, and trigger Lambda functions or pipelines. Event-driven approaches help optimize workflows and improve system responsiveness.
Athena allows serverless querying of data stored in S3. Practicing SQL queries, partitioning strategies, and integration with BI tools enhances analytical skills and provides insights into cost optimization for querying large datasets.
Security and governance services include IAM, KMS, and CloudTrail. Candidates should practice creating roles, policies, encryption keys, and audit trails. Understanding compliance requirements and implementing secure access control ensures readiness for exam scenarios on data governance.
Hands-On Labs and Real-World Projects
Engaging with hands-on labs and real-world projects solidifies theoretical knowledge. Labs simulate practical scenarios where candidates must design, implement, and troubleshoot pipelines under realistic conditions. These exercises improve problem-solving skills, reduce exam anxiety, and reinforce key concepts.
Real-world projects can include building pipelines to process web traffic logs, IoT sensor data, or e-commerce transaction data. Candidates practice ingestion, transformation, storage, and visualization workflows, addressing challenges such as data quality, latency, and scalability. These experiences provide context for scenario-based questions on the exam.
Participating in hackathons, coding challenges, or collaborative projects provides exposure to time-bound problem-solving, teamwork, and innovative approaches. Candidates develop the ability to make architectural decisions, optimize performance, and implement best practices under pressure.
Evaluating project outcomes, reviewing errors, and iterating on solutions cultivates a deeper understanding of AWS services. Documenting processes, explaining design decisions, and analyzing trade-offs further prepare candidates for exam questions requiring reasoning and explanation.
Practice Tests and Self-Assessment
Practice tests play a crucial role in evaluating exam readiness. They simulate the exam environment, helping candidates manage time, handle stress, and identify areas needing further study. Regular practice builds confidence and reduces uncertainty about question formats and difficulty levels.
After completing practice tests, candidates should review incorrect answers to understand misconceptions and knowledge gaps. Repetition ensures retention of concepts and improves accuracy. Tracking progress over multiple practice tests allows for focused preparation on weak areas.
Self-assessment should also include hands-on exercises. Simulating real-world data pipelines, implementing transformations, and configuring storage solutions provide practical benchmarks for readiness. Comparing results with best practices reinforces learning and ensures comprehensive exam preparation.
Advanced Preparation Strategies for AWS Data Engineer Associate Certification
Achieving success in the AWS Data Engineer Associate exam requires a combination of foundational knowledge, practical experience, and advanced strategies that optimize learning and retention. Beyond understanding core concepts and performing hands-on exercises, candidates need to approach preparation strategically, focusing on high-yield topics, exam patterns, and scenario-based problem solving. Advanced preparation strategies involve mastering complex AWS services, optimizing workflows, managing real-time pipelines, and applying best practices for performance, security, and scalability.
Strategic preparation begins with reviewing exam objectives and weightings carefully. Understanding the domains, their relative importance, and the types of tasks assessed enables candidates to allocate study time efficiently. For example, the domain of data ingestion and transformation carries the highest weight and requires significant attention to practical exercises involving batch processing, streaming data, and transformation workflows. Allocating study hours according to domain weightings ensures a balanced approach, reducing the risk of neglecting crucial topics.
Focusing on scenario-based learning is particularly effective for AWS certification exams. Candidates should practice interpreting problem statements, designing solutions, and implementing them using AWS services. Scenario-based exercises mimic real-world challenges, testing both technical knowledge and decision-making skills. For example, a scenario may require designing a streaming pipeline that ingests sensor data, applies transformations, stores results in a data lake, and triggers alerts based on thresholds. Practicing such exercises enhances problem-solving capabilities and prepares candidates for exam questions that are more complex than straightforward multiple-choice queries.
Mastering Data Ingestion and Transformation
The domain of data ingestion and transformation is central to the exam and requires a deep understanding of multiple AWS services. Data ingestion involves capturing data from various sources, including relational databases, NoSQL stores, streaming platforms, APIs, and IoT devices. Candidates should be proficient in batch ingestion methods as well as real-time streaming, understanding the trade-offs between latency, throughput, and reliability.
AWS Kinesis Data Streams and Firehose are fundamental services for streaming ingestion. Candidates should practice creating streams, configuring partition keys, managing throughput, and ensuring data delivery to destinations such as S3, Redshift, or DynamoDB. Understanding retry mechanisms, error handling, and monitoring is critical for maintaining pipeline reliability. Integrating Lambda functions with Kinesis enables serverless processing, allowing transformations to be applied in real time.
Batch ingestion often involves ETL (extract, transform, load) processes. AWS Glue provides a serverless environment to perform ETL operations efficiently. Candidates should practice writing ETL scripts, scheduling jobs, and managing dependencies. Knowledge of Glue Data Catalog for metadata management ensures that pipelines are organized, discoverable, and maintainable. AWS DataBrew offers a visual interface for transformations, which is particularly useful for quick prototyping and data cleansing tasks. Hands-on exercises covering both scripted and visual transformations prepare candidates for diverse exam scenarios.
Transforming data effectively requires understanding schema evolution, data types, partitioning, and optimization techniques. Candidates must practice designing pipelines that handle malformed records, schema changes, and large-scale datasets efficiently. Awareness of performance optimization strategies, such as parallel processing, caching, and incremental processing, ensures that data pipelines are not only functional but also performant and cost-effective.
Advanced Data Storage and Management
Efficient data storage is critical for a data engineer, and the exam tests the ability to select appropriate storage solutions based on use cases. Candidates must understand relational databases, NoSQL databases, data lakes, and data warehouses. Mastery involves both configuration and performance optimization.
Amazon Redshift is a managed data warehouse that requires knowledge of schema design, distribution styles, and query optimization. Candidates should practice loading large datasets, performing analytical queries, and tuning cluster configurations to optimize performance. Redshift Spectrum enables querying data stored in S3, allowing for cost-effective analysis without duplicating datasets. Understanding when to use Redshift versus S3-based querying is essential for designing efficient solutions.
NoSQL solutions such as DynamoDB require candidates to understand partition keys, global secondary indexes, throughput capacity, and data modeling principles. Efficient design ensures low latency and scalability. Candidates should practice integrating DynamoDB with other services for both real-time and batch processing, understanding how to handle large datasets while maintaining cost efficiency.
Data lakes on S3 provide flexibility for storing structured and unstructured data. Candidates should practice configuring bucket policies, managing object lifecycles, and implementing encryption for security. Using Lake Formation for access control and catalog management ensures governance and compliance. Understanding the interaction between data lakes, analytics tools, and processing engines such as EMR or Glue strengthens readiness for the exam.
Optimizing Data Pipelines
Optimization is a critical aspect of advanced preparation. Candidates must understand how to build pipelines that are scalable, reliable, and cost-effective. Pipeline optimization involves minimizing latency, maximizing throughput, and reducing operational costs while ensuring data integrity and consistency.
Monitoring is essential for optimization. AWS CloudWatch provides metrics, logs, and dashboards for tracking pipeline performance. Candidates should practice creating alarms for failed jobs, data delays, or resource exhaustion. CloudTrail enables auditing of changes, ensuring accountability and traceability. Effective monitoring allows engineers to anticipate issues, apply corrective measures promptly, and maintain high reliability.
Resource configuration also impacts optimization. Selecting the right instance types, configuring auto-scaling, and using serverless services where appropriate reduces cost and improves performance. Candidates should practice scenarios involving scaling pipelines to handle varying workloads, ensuring that data flows smoothly without interruption.
Cost optimization requires understanding pricing models, resource utilization, and data transfer costs. Candidates should practice designing pipelines that balance performance and cost, for example, by choosing batch processing for non-critical tasks and streaming for time-sensitive data. Knowledge of storage tiers in S3, reserved versus on-demand instances, and query costs in Redshift or Athena contributes to cost-efficient solutions.
Security, Compliance, and Governance
Security and governance are integral to data engineering on AWS. The exam evaluates the candidate’s ability to implement secure, compliant, and well-governed data architectures. Candidates must understand identity and access management, encryption, auditing, and data lifecycle management.
IAM roles and policies allow granular control over service access. Candidates should practice creating roles for different pipeline components, granting least-privilege access, and integrating cross-account access where necessary. Encryption at rest using KMS and in transit using TLS ensures that sensitive data is protected. Understanding key rotation, management, and auditing provides confidence in implementing robust security measures.
Data governance involves applying policies, standards, and controls to ensure data quality, compliance, and privacy. Candidates should practice classifying sensitive data, implementing masking or tokenization where required, and using Lake Formation or S3 policies to enforce governance rules. Knowledge of compliance standards such as GDPR, HIPAA, or SOC helps candidates design pipelines that meet regulatory requirements.
Regular auditing, logging, and monitoring are part of governance best practices. CloudTrail, Config, and S3 access logs provide comprehensive visibility into operations, allowing candidates to detect anomalies, ensure compliance, and maintain accountability. Hands-on practice in configuring these services and reviewing logs prepares candidates for exam scenarios focused on security and governance.
Time Management and Exam Strategy
Advanced preparation also involves mastering exam strategy. Candidates must manage time effectively, prioritize questions, and handle scenario-based problems efficiently. Simulating the exam environment with practice tests helps build familiarity with question types, time constraints, and difficulty levels.
Reviewing practice test results allows candidates to identify weak areas and allocate time for additional study. Repeating tests and tracking performance over time builds confidence and reduces exam anxiety. Understanding the common patterns in exam questions, such as focusing on service interactions, troubleshooting scenarios, and cost optimization, enables candidates to approach questions strategically.
Reading questions carefully, noting key requirements, and eliminating incorrect options improve accuracy. Scenario-based questions often require multiple steps, including selecting appropriate services, configuring them correctly, and ensuring security and performance. Practicing end-to-end workflows helps candidates tackle these questions with confidence.
Maintaining a balance between speed and accuracy is essential. Candidates should aim to answer easier questions quickly, allocate more time to complex scenarios, and review marked questions if time allows. Developing this strategy during preparation ensures that candidates can complete the exam efficiently while minimizing errors.
Continuous Learning and Knowledge Reinforcement
Finally, continuous learning and knowledge reinforcement are critical components of advanced preparation. AWS frequently updates its services, introduces new features, and publishes best practices. Staying updated with these changes ensures that candidates are familiar with current tools, configurations, and methodologies.
Engaging with AWS documentation, whitepapers, and technical blogs provides detailed insights into service functionality, limitations, and best practices. Following webinars, tutorials, and community forums allows candidates to learn from real-world use cases and emerging trends. Continuous practice, project implementation, and review of past exercises reinforce knowledge and improve retention.
Final Exam Readiness for AWS Data Engineer Associate Certification
Achieving success in the AWS Data Engineer Associate exam requires not only knowledge and practical skills but also a strategic approach to final preparation. Final exam readiness involves consolidating learning, reviewing critical concepts, practicing under exam-like conditions, and managing time effectively. Candidates must ensure they have a strong grasp of all exam domains, are comfortable with hands-on implementations, and are prepared to solve complex, scenario-based questions efficiently.
Reviewing exam objectives and domain weightings is a crucial step in final readiness. Understanding which topics carry the most weight allows candidates to focus their revision time on areas with the highest impact. Data ingestion and transformation, for example, account for a substantial portion of the exam and require mastery of both batch and streaming techniques. Management of data stores, support and operations, and data governance and security also demand focused attention. Prioritizing high-weight domains ensures candidates are well-prepared for questions that contribute significantly to their overall score.
Final exam readiness also requires consolidating practical knowledge. Candidates should revisit hands-on projects, practice pipelines, and review configurations of AWS services such as S3, Redshift, Glue, Kinesis, and DynamoDB. Recreating end-to-end workflows, performing transformations, and troubleshooting errors ensures familiarity with operational challenges. This approach strengthens problem-solving skills and increases confidence in handling real-world scenarios, which are often reflected in exam questions.
Reviewing Core AWS Services and Concepts
A thorough review of core AWS services is essential in the final preparation stage. Candidates should ensure they understand the features, limitations, and best practices for each service. S3 is the foundation for storage and data lakes, and candidates must be familiar with bucket policies, lifecycle management, encryption, and access control. Redshift requires understanding schema design, query optimization, and cluster management. Glue and Glue DataBrew provide ETL and transformation capabilities that candidates must practice extensively. Kinesis and EventBridge are critical for streaming and event-driven architectures.
Candidates should also review integration and interconnectivity between services. Understanding how data flows from ingestion to storage, transformation, and analysis allows candidates to answer scenario-based questions effectively. Knowledge of how to integrate AWS Lambda with Kinesis, Glue, and EventBridge ensures end-to-end comprehension. Reviewing best practices for performance optimization, cost management, and security reinforces readiness for questions that test both technical and strategic skills.
Security and compliance review areequally important. Candidates should revisit IAM roles and policies, KMS encryption, CloudTrail auditing, and access logging. Understanding governance frameworks, data classification, and compliance standards ensures that candidates can design secure and compliant data pipelines. Familiarity with these concepts reduces the risk of errors in scenario-based questions that evaluate governance and security knowledge.
Practice Tests and Simulation
Practice tests are a vital component of final exam readiness. They simulate the actual exam environment, allowing candidates to experience the pressure of time constraints and assess their knowledge under realistic conditions. Practice tests help identify weak areas, reinforce strong concepts, and build confidence.
Candidates should take multiple practice tests, reviewing incorrect answers to understand misconceptions and gaps. Repetition helps in retaining knowledge and improving accuracy. Tracking performance over multiple tests allows candidates to measure progress and adjust preparation strategies. Focused revision on weak areas ensures that all exam domains are adequately covered before the final attempt.
Simulating exam conditions also involves managing time effectively. Candidates should practice completing questions within the allotted time, ensuring that each scenario receives sufficient attention. Reviewing questions strategically, marking challenging ones for later review, and maintaining focus throughout the test are essential skills for managing the actual exam.
Troubleshooting and Problem-Solving Skills
Scenario-based questions often test the ability to troubleshoot and resolve issues. Candidates must be proficient in identifying errors, analyzing logs, and implementing corrective measures. Troubleshooting skills involve understanding pipeline failures, debugging ETL jobs, resolving data inconsistencies, and optimizing performance.
Hands-on practice in troubleshooting enhances candidates’ ability to think critically under pressure. For example, identifying a failure in a Kinesis stream or a Glue job requires reviewing configurations, checking permissions, and analyzing logs. Candidates should also practice resolving performance bottlenecks, such as slow Redshift queries or S3 read/write delays. Understanding error handling mechanisms and retry strategies ensures readiness for real-world scenarios reflected in the exam.
Problem-solving skills extend to designing solutions that balance performance, cost, and reliability. Candidates should practice selecting appropriate services, configuring resources efficiently, and implementing failover mechanisms. Scenario-based exercises reinforce the ability to make informed decisions, anticipate challenges, and apply best practices consistently.
Domain-Specific Mastery
Achieving domain-specific mastery is critical in the final stage of preparation. Candidates should review each exam domain in detail, ensuring proficiency in both theoretical and practical aspects.
Data ingestion and transformation require understanding batch and streaming techniques, ETL processes, and real-time pipelines. Candidates should practice data validation, schema evolution, and transformation optimization. Hands-on experience with Glue, Lambda, Kinesis, and DataBrew ensures familiarity with all relevant tools.
Management of data stores involves relational, NoSQL, and data lake solutions. Candidates must review schema design, indexing, throughput configuration, and query optimization. Practicing with Redshift, DynamoDB, S3, and Lake Formation ensures the ability to implement efficient and scalable storage solutions.
Support and data operations require familiarity with monitoring, troubleshooting, and automation. Candidates should practice setting up CloudWatch dashboards, configuring alarms, reviewing logs, and implementing automated remediation. Understanding operational workflows, error handling, and performance tuning is essential for scenario-based questions.
Data governance and security require knowledge of IAM roles, encryption, auditing, and compliance. Candidates should review policies, access control mechanisms, data classification, and lifecycle management. Hands-on exercises in configuring secure pipelines and reviewing audit logs reinforce comprehension and readiness for security-related exam questions.
Exam Strategy and Time Management
Developing an effective exam strategy is essential for success. Candidates must approach the exam with a clear plan, manage time efficiently, and maintain focus throughout the test. Understanding the structure, question types, and domain weightings allows for strategic allocation of time.
Candidates should read each question carefully, noting key requirements and constraints. Scenario-based questions often involve multiple steps, and attention to detail is crucial for selecting the correct combination of services, configurations, and processes. Eliminating incorrect options and prioritizing easier questions first helps manage time effectively.
Reviewing marked questions is an important part of exam strategy. Candidates should reserve time at the end to revisit challenging questions, ensuring accuracy and completeness. Maintaining calm and composure during the exam reduces errors caused by stress and fatigue. Practicing these strategies during final preparation builds familiarity and confidence.
Continuous Revision and Knowledge Reinforcement
Continuous revision is vital in the final preparation phase. Reviewing notes, revisiting key concepts, and practicing hands-on exercises ensure that knowledge is retained and readily accessible during the exam. Candidates should focus on high-weight domains, complex workflows, and frequently tested scenarios.
Knowledge reinforcement involves applying concepts in practical settings. Building and testing pipelines, transforming datasets, and managing storage solutions helpconsolidate learning. Reviewing performance optimization techniques, troubleshooting workflows, and implementing security measures reinforces understanding and prepares candidates for diverse exam scenarios.
Engaging with study groups or professional communities provides additional insights and clarifies doubts. Discussions with peers expose candidates to alternative approaches, real-world use cases, and exam tips. Sharing knowledge and reviewing practical challenges strengthens comprehension and builds confidence.
Maintaining Exam Readiness
Final exam readiness also requires maintaining physical and mental well-being. Adequate rest, proper nutrition, and stress management contribute to focus, concentration, and cognitive performance during the exam. Candidates should plan study sessions to avoid burnout, incorporating breaks and relaxation periods.
Practical exercises should continue until the exam day to keep skills sharp. Revisiting practice tests, troubleshooting pipelines, and reviewing AWS service configurations ensures familiarity with workflows. Confidence in hands-on abilities reduces exam anxiety and prepares candidates to handle complex scenario-based questions effectively.
Candidates should also prepare for unexpected challenges during the exam. Understanding AWS service limitations, troubleshooting unexpected errors, and applying logical reasoning helpmanage surprises in scenario-based questions. Simulating real-world problems during preparation enhances adaptability and decision-making skills.
Conclusion
Final exam readiness for the AWS Data Engineer Associate certification involves a comprehensive approach that combines knowledge review, hands-on practice, scenario-based learning, and strategic planning. Mastery of core AWS services, practical application of workflows, and understanding integration, security, and optimization techniques are essential.
Candidates must consolidate learning, practice extensively, and simulate exam conditions to build confidence and accuracy. Developing troubleshooting skills, mastering domain-specific knowledge, and applying best practices ensures rreadinessor complex questions and real-world scenarios. Effective time management, strategic question handling, and continuous revision enhance exam performance.
Maintaining physical and mental well-being, staying updated with AWS service developments, and engaging in continuous practice contribute to final readiness. By following these strategies, candidates maximize their chances of success and position themselves as competent AWS Data Engineers capable of handling complex data engineering tasks in cloud environments.
Databricks Certified Data Engineer Associate practice test questions and answers, training course, study guide are uploaded in ETE Files format by real users. Study and Pass Certified Data Engineer Associate Certified Data Engineer Associate certification exam dumps & practice test questions and answers are to help students.
Purchase Certified Data Engineer Associate Exam Training Products Individually
Why customers love us?
What do our customers say?
The resources provided for the Databricks certification exam were exceptional. The exam dumps and video courses offered clear and concise explanations of each topic. I felt thoroughly prepared for the Certified Data Engineer Associate test and passed with ease.
Studying for the Databricks certification exam was a breeze with the comprehensive materials from this site. The detailed study guides and accurate exam dumps helped me understand every concept. I aced the Certified Data Engineer Associate exam on my first try!
I was impressed with the quality of the Certified Data Engineer Associate preparation materials for the Databricks certification exam. The video courses were engaging, and the study guides covered all the essential topics. These resources made a significant difference in my study routine and overall performance. I went into the exam feeling confident and well-prepared.
The Certified Data Engineer Associate materials for the Databricks certification exam were invaluable. They provided detailed, concise explanations for each topic, helping me grasp the entire syllabus. After studying with these resources, I was able to tackle the final test questions confidently and successfully.
Thanks to the comprehensive study guides and video courses, I aced the Certified Data Engineer Associate exam. The exam dumps were spot on and helped me understand the types of questions to expect. The certification exam was much less intimidating thanks to their excellent prep materials. So, I highly recommend their services for anyone preparing for this certification exam.
Achieving my Databricks certification was a seamless experience. The detailed study guide and practice questions ensured I was fully prepared for Certified Data Engineer Associate. The customer support was responsive and helpful throughout my journey. Highly recommend their services for anyone preparing for their certification test.
I couldn't be happier with my certification results! The study materials were comprehensive and easy to understand, making my preparation for the Certified Data Engineer Associate stress-free. Using these resources, I was able to pass my exam on the first attempt. They are a must-have for anyone serious about advancing their career.
The practice exams were incredibly helpful in familiarizing me with the actual test format. I felt confident and well-prepared going into my Certified Data Engineer Associate certification exam. The support and guidance provided were top-notch. I couldn't have obtained my Databricks certification without these amazing tools!
The materials provided for the Certified Data Engineer Associate were comprehensive and very well-structured. The practice tests were particularly useful in building my confidence and understanding the exam format. After using these materials, I felt well-prepared and was able to solve all the questions on the final test with ease. Passing the certification exam was a huge relief! I feel much more competent in my role. Thank you!
The certification prep was excellent. The content was up-to-date and aligned perfectly with the exam requirements. I appreciated the clear explanations and real-world examples that made complex topics easier to grasp. I passed Certified Data Engineer Associate successfully. It was a game-changer for my career in IT!


