- Home
- Amazon Certifications
- AWS DevOps Engineer Professional AWS DevOps Engineer - Professional (DOP-C01) Dumps
Pass Amazon AWS DevOps Engineer Professional Exam in First Attempt Guaranteed!


AWS DevOps Engineer Professional Premium File
- Premium File 208 Questions & Answers. Last Update: Jun 15, 2026
Whats Included:
- Latest Questions
- 100% Accurate Answers
- Fast Exam Updates








Last Week Results!
All Amazon AWS DevOps Engineer Professional certification exam dumps, study guide, training courses are Prepared by industry experts. PrepAway's ETE files povide the AWS DevOps Engineer Professional AWS DevOps Engineer - Professional (DOP-C01) practice test questions and answers & exam dumps, study guide and training courses help you study and pass hassle-free!
Study Smarter for the AWS Certified DevOps Engineer Exam: Key Insights and Guidance
The AWS Certified DevOps Engineer – Professional certification represents one of the most advanced and respected credentials within the AWS certification track. It validates a professional’s ability to design, implement, automate, and manage distributed applications and systems on the AWS platform using DevOps methodologies. This certification measures a candidate’s capacity to handle complex automation tasks, ensure reliability, maintain performance, and enforce security in a cloud environment built with AWS services.
This certification is intended for individuals who possess deep technical skills in both development and operations, along with the ability to integrate automation into cloud solutions. The goal of the certification is to confirm that a professional can manage continuous integration and continuous delivery pipelines, monitor system health, and maintain security compliance while optimizing system performance. It requires hands-on experience with multiple AWS services that support DevOps practices, including AWS CodePipeline, AWS CodeBuild, AWS CodeDeploy, AWS CloudFormation, and AWS Elastic Beanstalk.
Professionals pursuing this certification should also understand the software development lifecycle and operations principles in depth. This includes the ability to design and implement automation solutions that simplify deployment, scale infrastructure efficiently, and ensure that applications meet business objectives with minimal manual intervention. The certification is not only a recognition of technical knowledge but also a reflection of practical problem-solving ability in managing real-world production systems.
Purpose and Relevance of the Certification
The AWS Certified DevOps Engineer – Professional certification serves as a benchmark for validating skills that are essential for modern DevOps practices in cloud-based environments. In organizations where AWS infrastructure forms the backbone of their technology stack, professionals who hold this certification demonstrate expertise in automating operational processes, maintaining resilient systems, and managing security with precision.
This certification emphasizes a holistic approach to cloud operations, combining automation, security, performance monitoring, and infrastructure management. It requires a strong understanding of how to create efficient and scalable pipelines that automate code deployment, infrastructure provisioning, and system updates. Candidates are expected to showcase their knowledge of event-driven architectures, monitoring systems using AWS CloudWatch, logging mechanisms, and compliance frameworks.
Beyond automation and system management, the certification also highlights skills related to reliability engineering and incident response. DevOps engineers must be capable of restoring services rapidly after failures, using AWS tools and strategies for fault tolerance and disaster recovery. This ability to minimize downtime and optimize performance directly supports business continuity and operational excellence.
Structure and Format of the Exam
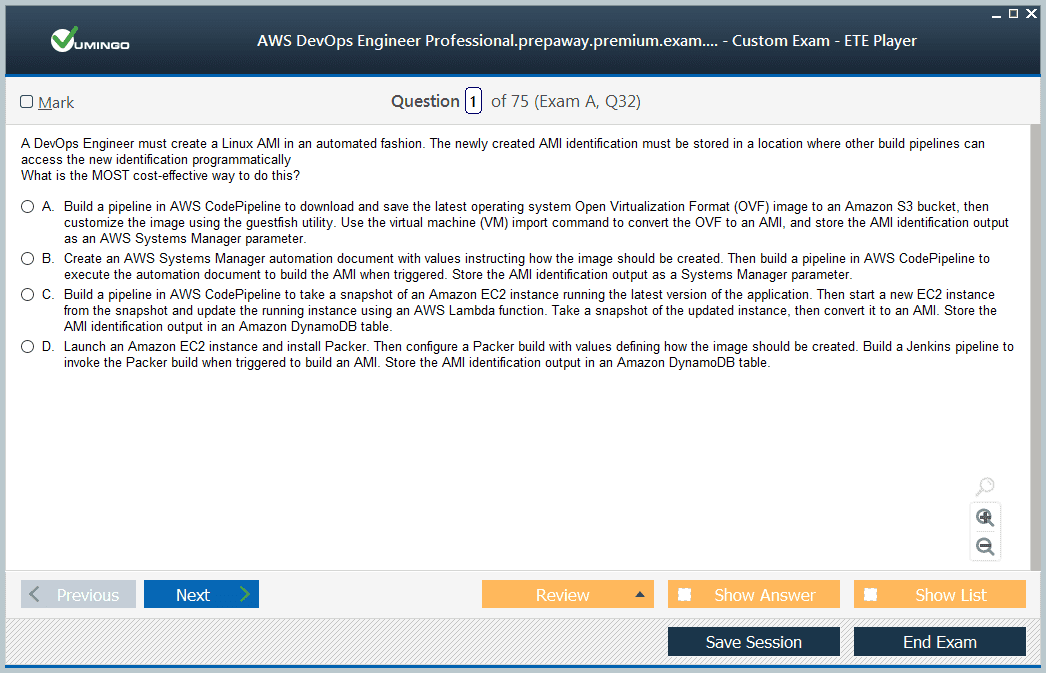
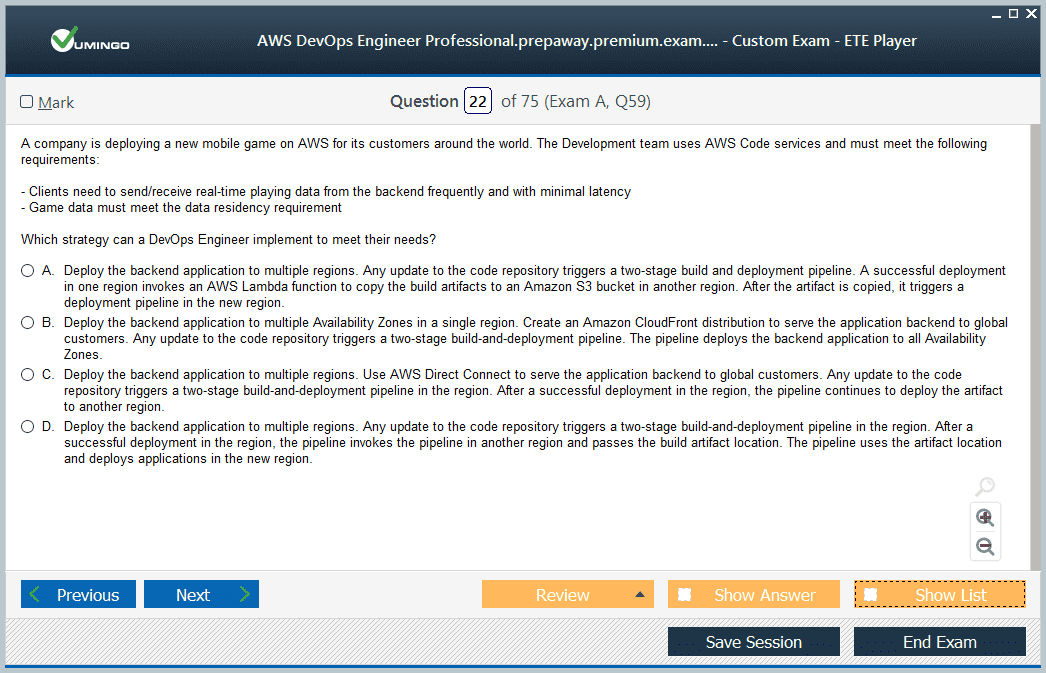
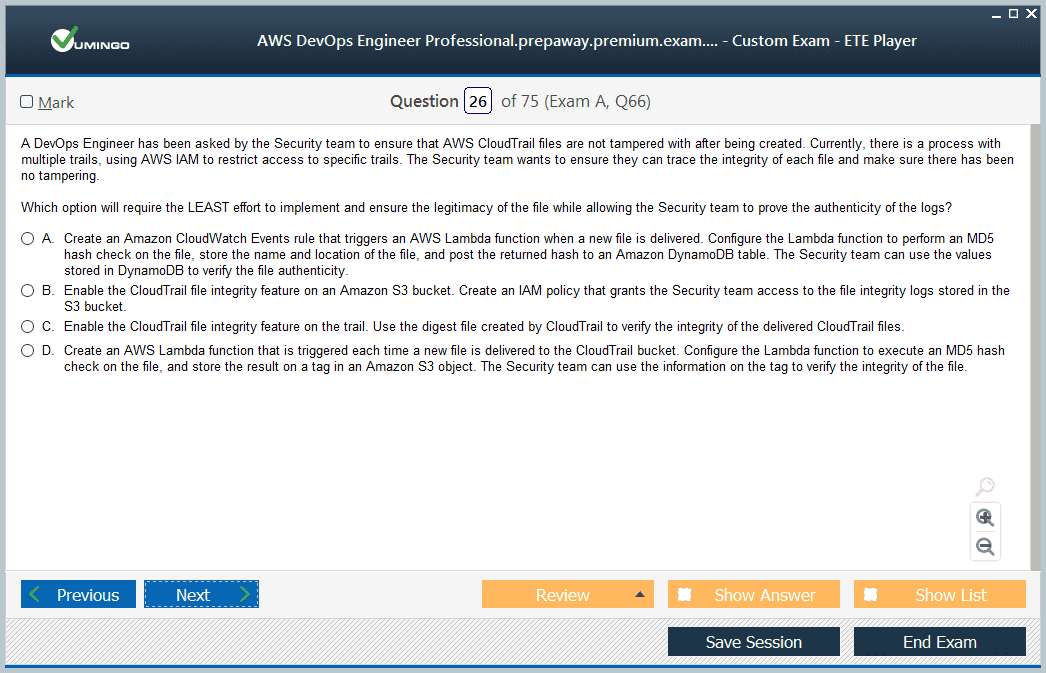
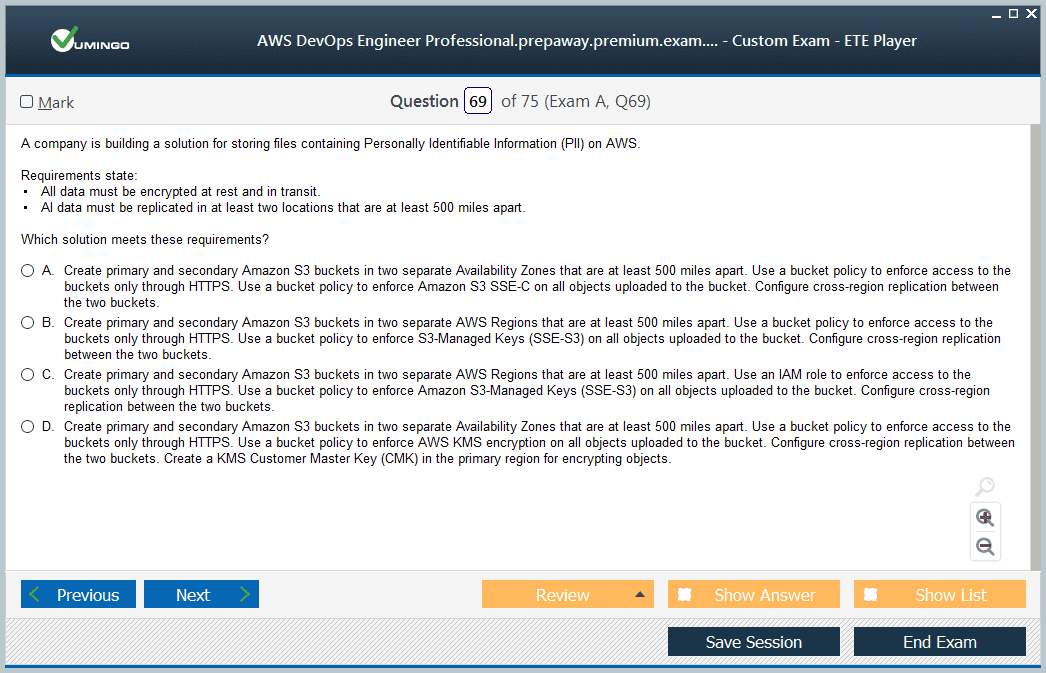
The AWS Certified DevOps Engineer – Professional exam is designed to test both theoretical knowledge and hands-on experience. It consists of 75 questions, including multiple-choice and multiple-response types. Of these, 65 questions are scored while 10 are unscored, serving as evaluation items for future exam development. The total duration of the exam is 180 minutes. The questions are scenario-based, often requiring candidates to analyze complex operational challenges and select the best combination of AWS solutions.
There is no negative marking, which allows candidates to attempt all questions without fear of losing points for incorrect answers. The scoring focuses on the ability to apply concepts in practical, real-world AWS environments. Candidates are assessed on multiple domains that reflect the key pillars of DevOps: automation, configuration management, monitoring, security, and incident handling. The exam is considered demanding due to its depth and the level of expertise expected, making thorough preparation essential.
Key Knowledge Areas Assessed
The exam content is structured around six core domains that evaluate different aspects of DevOps practices within AWS. Each domain focuses on specific skill sets that align with operational excellence and continuous improvement in cloud-based environments.
The first domain, SDLC Automation, focuses on the implementation of automation across the software development lifecycle. Candidates must demonstrate how to build and manage continuous integration and continuous delivery pipelines using AWS services. This includes automating code compilation, running automated tests, managing artifacts, and deploying applications seamlessly across environments.
The second domain, Configuration Management and Infrastructure as Code, examines the ability to define, deploy, and maintain AWS infrastructure through code. This involves using AWS CloudFormation, the AWS Cloud Development Kit, and other tools to automate provisioning, apply version control to infrastructure templates, and manage environments consistently. Candidates should also understand how to scale applications across multiple regions using automation techniques.
The third domain, Resilient Cloud Solutions, measures the ability to design and deploy fault-tolerant architectures. It includes managing container-based deployments using Amazon ECS or Amazon EKS, creating backup and recovery strategies, and implementing multi-region and multi-availability zone solutions that ensure business continuity.
The fourth domain, Monitoring and Logging, tests the understanding of monitoring tools and strategies for maintaining visibility across systems. Candidates are expected to configure Amazon CloudWatch for metrics, logs, and alarms, as well as use AWS X-Ray for tracing distributed applications. They should also understand event-driven design patterns and how to implement automation that responds dynamically to changing system states.
The fifth domain, Incident and Event Response, focuses on handling unexpected operational issues. Candidates must know how to use AWS tools like CloudTrail, EventBridge, and Systems Manager to detect, analyze, and mitigate incidents. They should also demonstrate the ability to automate responses to system events, ensuring minimal manual intervention during outages or failures.
The final domain, Security and Compliance, assesses the candidate’s understanding of data protection and security automation. This includes encrypting data at rest and in transit, managing identity and access using IAM roles and policies, and implementing automated compliance monitoring. Candidates are also tested on their ability to detect and respond to security vulnerabilities using AWS security services.
Preparation Strategy for the Exam
Preparing for the AWS Certified DevOps Engineer – Professional exam requires a structured and disciplined approach that combines theoretical study with hands-on practice. The exam demands a practical understanding of how AWS services interact to form complete automation and deployment solutions.
The first step in preparation is to study the exam guide in detail to understand the domains, objectives, and weight of each section. This helps in identifying which areas need more focus and which services require deeper exploration. Candidates should then gain significant practical experience in building CI/CD pipelines, configuring monitoring tools, and automating infrastructure deployments.
Hands-on experience is essential because the exam questions are often scenario-driven, requiring the application of concepts rather than rote memorization. Working with AWS services such as CodePipeline, CodeBuild, and CloudFormation helps solidify understanding. Building sample projects that involve automating application deployment or monitoring systems provides valuable real-world insight.
It is also beneficial to review documentation for core AWS services used in automation, monitoring, and security. Understanding how these services integrate within DevOps workflows ensures a strong conceptual foundation. Practicing troubleshooting and optimization scenarios further helps refine problem-solving abilities, which are crucial for success.
Mock exams are an important part of preparation. They provide exposure to the question format, time management practice, and insight into areas where additional study is needed. Regularly taking practice tests and reviewing explanations for incorrect answers improves comprehension and retention. Candidates should also allocate time to revise AWS architectural best practices, as many exam questions are built around optimizing architecture for reliability, performance, and cost.
Study Plan for Consistent Progress
A balanced study plan that spans several weeks can help ensure comprehensive coverage of all exam domains. Allocating time to each major domain allows for progressive mastery without overwhelming the learning process.
Begin with SDLC automation by learning to implement continuous integration and deployment using AWS DevOps tools. Next, focus on infrastructure automation through AWS CloudFormation and the AWS CDK. Once familiar with these tools, shift attention to designing resilient architectures using containers, serverless services, and backup strategies.
The following phase should involve setting up monitoring and logging systems using CloudWatch and AWS X-Ray to understand how performance metrics and alerts operate in real time. Afterward, focus on incident response practices and learn how AWS tools automate detection and mitigation. Finally, dedicate time to mastering security and compliance principles by studying identity management, data protection, and auditing strategies.
The last stage of preparation should focus on review and practice tests. Revisiting difficult topics and reinforcing weaker areas ensures thorough understanding before the exam. Maintaining consistency in study sessions is key to retaining knowledge and building confidence.
Effective Strategies for Exam Day
On the day of the exam, a calm and focused approach is essential. Start by managing time effectively; with 75 questions and limited time, it is important to pace yourself. Begin by answering questions you are confident about and mark difficult ones for review. This approach ensures that no question is left unanswered.
Reading each question carefully is critical, as many are scenario-based and contain important contextual details. Identifying keywords helps in linking the problem to specific AWS services or best practices. If uncertain about an answer, use the process of elimination to remove clearly incorrect options, increasing your chances of selecting the correct one.
Maintaining concentration and composure throughout the test helps in recalling concepts more clearly. Taking short pauses for deep breaths between sections can help reset focus. Reviewing marked questions at the end can also reveal answers that become clearer after analyzing later questions.
Preparation before the exam extends beyond studying. Ensuring that all logistics are arranged and that you are physically rested contributes to better performance. Staying hydrated and maintaining a positive mindset can enhance mental clarity during the test.
The AWS Certified DevOps Engineer – Professional certification signifies mastery in managing automated and scalable cloud solutions using AWS technologies. It validates the ability to combine development and operations principles into a cohesive workflow that promotes efficiency, reliability, and security. Achieving this certification reflects not only a deep understanding of AWS services but also the capability to apply them in practical, high-stakes environments.
Earning this credential demonstrates advanced expertise in modern cloud engineering practices, positioning professionals as key contributors to automation, system optimization, and operational excellence in the AWS ecosystem. It is a valuable achievement for anyone aiming to build a career focused on DevOps methodologies and AWS cloud infrastructure management.
Core Competencies Measured in the AWS Certified DevOps Engineer – Professional Exam
The AWS Certified DevOps Engineer – Professional exam focuses on validating a candidate’s ability to design, automate, and operate scalable systems in a dynamic AWS environment. It tests a wide range of technical and operational competencies that align with real-world cloud infrastructure challenges. The core objective of the certification is to ensure that the candidate can manage every stage of the software delivery process using automation, monitoring, and secure deployment practices.
At its foundation, the certification measures how well professionals can integrate development and operational processes through continuous delivery and continuous integration. Candidates are expected to demonstrate proficiency in setting up automated pipelines, managing configuration and deployment frameworks, and optimizing system performance. The exam also assesses knowledge of security principles, system monitoring, and incident response to ensure that applications remain resilient and compliant under varying workloads.
A key focus of the certification is automation. This includes automating infrastructure provisioning through tools like AWS CloudFormation and AWS CDK, automating deployments with AWS CodePipeline and AWS CodeDeploy, and managing complex workloads with minimal manual intervention. It also extends to monitoring automation where tools like CloudWatch, CloudTrail, and EventBridge are used to track system health, detect anomalies, and automatically trigger corrective actions.
Another important aspect of the exam is understanding the relationship between scalability and reliability. Candidates need to know how to design systems that handle fluctuations in demand without performance degradation. This involves knowledge of services such as Auto Scaling, Elastic Load Balancing, and Amazon ECS for containerized applications. The certification expects professionals to ensure that systems maintain fault tolerance and recovery strategies that meet operational goals.
Security and compliance form another crucial competency. The certification ensures that the professional understands how to apply security controls across AWS environments, including encryption methods, access management, vulnerability detection, and policy enforcement. The candidate must show the ability to balance operational efficiency with data protection by designing systems that meet both performance and compliance standards.
Deep Dive into Automation and Deployment
Automation is at the heart of the AWS DevOps Engineer Professional certification. The exam assesses how candidates build, maintain, and optimize automated processes that manage application lifecycle stages. In DevOps, automation enables faster delivery cycles, reduces human error, and improves system consistency across environments.
Candidates should understand the principles of continuous integration and continuous delivery pipelines, ensuring that code changes can be tested, validated, and deployed automatically. This requires familiarity with AWS tools designed to streamline the CI/CD process. AWS CodePipeline orchestrates the overall workflow by connecting different stages such as code building, testing, and deployment. AWS CodeBuild automates the compilation and testing of code, while AWS CodeDeploy handles application deployment to environments like EC2, Lambda, or on-premises servers.
Infrastructure automation is another key area. Professionals must be skilled in defining infrastructure as code to achieve predictable and repeatable deployments. Using AWS CloudFormation, engineers can design templates that define entire architectures including networking components, security configurations, and compute resources. The AWS Cloud Development Kit allows engineers to use familiar programming languages to define infrastructure, enabling better integration with existing development processes.
Automation extends beyond deployment to operational management. AWS Systems Manager is often used to automate patch management, configuration updates, and compliance enforcement. Event-driven automation, such as using EventBridge or CloudWatch events, ensures that operational tasks are triggered automatically based on specific system states. For instance, automated scaling actions or backup processes can be executed without human intervention, reducing response time and improving operational efficiency.
The exam also evaluates knowledge of implementing blue/green or canary deployments to reduce downtime during updates. These deployment techniques ensure that application versions can be released with minimal disruption by allowing controlled traffic routing between old and new versions. Professionals must understand how to design rollback strategies and test automation sequences that maintain application stability even during continuous changes.
Managing Monitoring and System Visibility
A fundamental skill evaluated in the AWS DevOps Engineer Professional certification is the ability to monitor system health and maintain operational visibility. Effective monitoring enables early detection of issues, performance optimization, and proactive incident management.
Candidates are expected to understand how to design comprehensive monitoring architectures that integrate logging, metrics, and tracing. Amazon CloudWatch plays a central role in this process, providing insights into resource utilization, application performance, and custom metrics. Engineers use CloudWatch Alarms to automate responses when metrics exceed defined thresholds. This could involve triggering an Auto Scaling event or sending notifications through Amazon SNS.
AWS X-Ray is another vital service for tracing requests across distributed applications. It helps identify performance bottlenecks and latency issues in microservice architectures. Understanding how to interpret trace maps and service graphs is essential for diagnosing complex operational problems.
Logging is equally important for compliance and troubleshooting. AWS CloudTrail captures all API activity, enabling engineers to track changes across AWS accounts. CloudWatch Logs centralizes logs from different sources, making it easier to analyze and correlate data for debugging. Event-driven automation can also be configured to initiate specific actions based on log patterns or operational anomalies.
The exam requires candidates to understand how to implement proactive monitoring strategies that improve performance and cost efficiency. This includes setting up anomaly detection, dashboard visualization, and capacity planning using historical performance data. Candidates must demonstrate knowledge of how to optimize alert configurations to minimize noise while ensuring critical events are detected immediately.
Monitoring is not just about observing metrics; it’s about using those insights to improve system design. The certification validates the ability to continuously enhance architectures based on operational data. This might involve adjusting scaling thresholds, modifying resource allocations, or automating recurring maintenance tasks to improve resilience and reduce costs.
Ensuring Security, Compliance, and Governance
Security is one of the most heavily emphasized components of the AWS DevOps Engineer Professional certification. The exam measures understanding of implementing robust security controls that align with DevOps principles without compromising agility.
Candidates must know how to manage user access using AWS Identity and Access Management by creating granular roles and policies that follow the principle of least privilege. Understanding multi-account strategies and role delegation is important for maintaining security across large-scale environments. Automated enforcement of security baselines using tools such as AWS Config and Systems Manager ensures compliance across all resources.
The certification also evaluates understanding of data protection mechanisms, including encryption of data both in transit and at rest. Candidates should know how to configure AWS Key Management Service to handle encryption keys securely and how to integrate encryption into automated workflows. Network security concepts such as VPC configurations, security groups, and network ACLs are also assessed as they form the foundation for secure architecture design.
Another crucial aspect is vulnerability management. Professionals must understand how to integrate automated security scanning into CI/CD pipelines to identify risks early in the development cycle. Continuous compliance monitoring is also essential, ensuring that systems remain aligned with governance policies as they evolve.
Incident response is closely tied to security. The certification expects professionals to automate detection and response to potential threats using services like AWS CloudTrail and EventBridge. Candidates must demonstrate the ability to design automated workflows that isolate compromised resources, notify stakeholders, and trigger corrective actions immediately.
Building Resilient and Scalable Architectures
A core requirement of the AWS DevOps Engineer Professional exam is demonstrating the ability to design resilient systems capable of maintaining performance under variable conditions. The certification emphasizes building fault-tolerant, self-healing architectures that can automatically recover from failures.
Resiliency starts with redundancy. Candidates should know how to design multi-availability zone deployments that distribute workloads evenly to avoid single points of failure. Auto Scaling groups are critical in maintaining consistent performance under changing loads by automatically adjusting compute resources. Elastic Load Balancing ensures efficient traffic distribution and improved fault tolerance.
In addition to resilience, scalability is key to operational efficiency. Candidates must understand how to build architectures that grow dynamically without manual intervention. This includes using serverless services such as AWS Lambda or container orchestration platforms like Amazon ECS and EKS. Each service offers scalability while maintaining automation, which aligns with DevOps principles.
Disaster recovery strategies are another major focus. The certification tests knowledge of designing backup and restore solutions that minimize downtime. Implementing cross-region replication, snapshot automation, and data archiving ensures business continuity even during large-scale failures.
The certification also expects engineers to design for performance optimization and cost management. This involves selecting appropriate instance types, implementing caching strategies using services like Amazon CloudFront, and optimizing storage tiers. The ability to balance performance, resilience, and cost efficiency is a mark of a true DevOps professional.
Exam Readiness and Mindset
Achieving success in the AWS Certified DevOps Engineer Professional exam requires more than memorizing concepts; it demands applied knowledge and strategic preparation. Candidates should approach their study plan with a mindset focused on understanding interconnections between services rather than viewing them in isolation.
Hands-on experience plays the most important role. The more a candidate experiments with real AWS environments, the better they understand practical scenarios reflected in exam questions. Building personal projects, automating deployments, setting up monitoring dashboards, and troubleshooting real configurations strengthen conceptual understanding.
Another vital component of readiness is mastering time management during the exam. The exam requires processing complex questions under time constraints, so practicing with sample exams is beneficial. Reading questions carefully, identifying key terms, and applying elimination strategies helps in making accurate choices.
It is also important to approach the exam with composure. A calm and methodical approach allows better recall of concepts and prevents misinterpretation of scenario details. Staying focused, pacing responses, and revisiting flagged questions toward the end improve overall performance.
The AWS Certified DevOps Engineer – Professional certification validates a comprehensive understanding of automation, resilience, security, and monitoring within AWS environments. It recognizes the ability to integrate development and operations seamlessly through automation while maintaining control, compliance, and performance. This certification signifies advanced expertise in managing modern cloud systems that require precision, scalability, and reliability.
Professionals who earn this credential demonstrate mastery of designing continuous delivery pipelines, implementing infrastructure as code, and maintaining resilient architectures that operate efficiently under real-world conditions. It is a recognition of both technical depth and strategic thinking, marking an individual as capable of managing complex AWS environments where automation and optimization are central to success.
Advanced Automation and Continuous Delivery in AWS DevOps Engineer Professional Exam
Automation forms the core of modern DevOps practices and is central to the AWS Certified DevOps Engineer Professional exam. This certification emphasizes the candidate’s ability to design and implement highly automated systems that handle every stage of software delivery without extensive manual intervention. The key focus is on establishing pipelines that support continuous integration and continuous delivery, ensuring code changes can flow from development to production quickly and securely.
Continuous integration is about ensuring that code from multiple developers integrates smoothly and is tested automatically. AWS CodeCommit provides a secure, scalable source control system for maintaining code repositories. Once code is committed, AWS CodeBuild compiles and tests it, creating build artifacts ready for deployment. CodePipeline automates the process by connecting these stages, orchestrating transitions from code commit to deployment. Understanding how to design, monitor, and troubleshoot these pipelines is critical for success in the exam.
Continuous delivery extends automation further by allowing applications to be deployed reliably to any environment. AWS CodeDeploy supports deployment to various compute services including EC2, Lambda, and on-premises servers. Candidates are expected to know different deployment strategies such as rolling, blue/green, and canary deployments, each minimizing risk during updates. Blue/green deployments involve running two environments simultaneously, shifting traffic gradually to the new version once validated. Canary deployments introduce updates to a small subset of users first, reducing exposure in case of errors.
Infrastructure automation is equally significant. AWS CloudFormation and the AWS Cloud Development Kit enable engineers to define infrastructure as code, allowing complex environments to be replicated consistently across accounts and regions. This ensures that infrastructure configurations are version-controlled, easily auditable, and automatically deployed as part of the CI/CD pipeline. Proficiency in managing templates, parameters, and stack policies helps ensure infrastructure changes are controlled and traceable.
Automation also extends into operations. Tools like AWS Systems Manager provide centralized control for executing operational tasks, patch management, and compliance checks. Event-driven automation using Amazon EventBridge or CloudWatch events can trigger functions or workflows automatically in response to specific system states. For example, auto-remediation workflows can detect failed health checks and replace unhealthy instances without human intervention. This ensures high availability and reduces recovery times.
Candidates must demonstrate an understanding of how to build self-healing systems through automation. This includes designing workflows that detect issues, perform diagnostics, and take corrective actions automatically. The exam may include scenarios requiring knowledge of using Lambda functions to automate custom remediation steps or integrating third-party tools for orchestration.
Operational Excellence and Observability
Operational excellence is a key domain in the AWS DevOps Engineer Professional certification. It ensures that professionals not only automate processes but also maintain visibility into systems to improve reliability and efficiency continuously. Observability involves collecting and analyzing data from multiple sources to gain insights into system behavior, detect issues early, and prevent service disruptions.
Amazon CloudWatch is the primary tool for monitoring AWS environments. It allows engineers to collect metrics, set alarms, and visualize performance through dashboards. Candidates are expected to understand how to use CloudWatch effectively for custom metrics, anomaly detection, and alert configurations. Metrics can include CPU utilization, latency, error rates, and custom application-specific parameters. By analyzing these metrics, engineers can optimize system performance and cost.
AWS X-Ray provides distributed tracing for applications running on AWS. It helps identify latency issues and pinpoint performance bottlenecks across services. Candidates must understand how to interpret trace maps and service graphs to locate dependencies and optimize service interactions. Effective tracing ensures applications remain responsive even as architectures grow more complex.
Logging is a critical part of observability. AWS CloudTrail captures all API activity, providing an audit trail of actions performed within an AWS account. CloudWatch Logs collects and centralizes logs from various sources such as Lambda functions, ECS containers, or on-premises servers. Engineers can analyze these logs to identify trends, investigate failures, and verify compliance.
Another vital aspect of operational excellence is proactive alerting and automated responses. Configuring CloudWatch Alarms to trigger notifications or initiate recovery actions ensures rapid mitigation of problems. For instance, when system performance drops, an alarm might trigger an Auto Scaling action or execute a remediation script via Systems Manager. Such automation enhances reliability and reduces operational overhead.
The certification also tests knowledge of designing fault-tolerant systems using monitoring data. Candidates should know how to integrate health checks, configure recovery mechanisms, and perform automated rollbacks in case of failure. A well-monitored system should be able to detect abnormal patterns, isolate failing components, and self-correct without manual involvement.
Operational excellence also involves cost and performance optimization. Understanding how to analyze utilization metrics, identify underused resources, and right-size instances contributes to overall system efficiency. Candidates are expected to apply data-driven insights from monitoring tools to optimize resource allocation, improve scaling policies, and enhance system resilience.
Security and Governance Automation
Security in the AWS DevOps Engineer Professional exam is not limited to configuring access control; it involves embedding security practices directly into the DevOps pipeline. This approach, often called DevSecOps, ensures that security is integrated throughout the software delivery lifecycle instead of being a separate step.
Candidates must understand how to automate security controls and governance processes across AWS environments. AWS Identity and Access Management plays a foundational role in managing permissions and roles. Engineers should be capable of implementing least privilege principles, ensuring that every user and service has only the access necessary for their tasks. Multi-account management and role-based access delegation are also important for scaling security across large organizations.
AWS Config continuously evaluates resource configurations to ensure compliance with predefined rules. It automatically detects configuration changes that drift from policy and triggers remediation workflows. Engineers can automate compliance enforcement by integrating Config with Systems Manager or Lambda functions that correct violations automatically.
Data protection is another essential area. Candidates must understand how to implement encryption for data at rest and in transit. AWS Key Management Service manages encryption keys securely, while AWS Secrets Manager and Parameter Store handle credentials and sensitive data. Automated key rotation and secret management help reduce risks associated with data exposure.
Network security also plays a major role. The certification tests understanding of securing VPCs using security groups, network ACLs, and private subnets. Engineers should also know how to automate network configuration using infrastructure-as-code templates. This ensures consistent security configurations across environments and reduces manual setup errors.
Security automation in CI/CD pipelines is another key concept. Engineers can integrate static code analysis, vulnerability scanning, and dependency checks directly into pipelines. Tools like CodePipeline and third-party integrations can automatically block deployments if security issues are detected. This proactive approach ensures security is enforced continuously.
Incident response automation is also crucial. The certification expects professionals to design workflows that detect security anomalies and respond automatically. AWS services such as GuardDuty and Security Hub provide threat detection, while EventBridge or Lambda functions can automate mitigation actions. For example, an automated workflow might isolate compromised instances, revoke credentials, or trigger alerts without delay.
Effective governance requires visibility and accountability. AWS CloudTrail and AWS Organizations provide centralized logging and control across multiple accounts. Engineers must understand how to use these services to maintain compliance and track activity across environments. The ability to design automated governance frameworks demonstrates advanced expertise in managing secure AWS systems.
High Availability, Reliability, and Disaster Recovery
Building high-availability and fault-tolerant architectures is one of the most advanced areas evaluated in the AWS DevOps Engineer Professional exam. Candidates are expected to design systems that can automatically recover from failure and maintain performance during varying load conditions.
High availability starts with distributing resources across multiple Availability Zones. This ensures that even if one zone experiences issues, the application continues to function. Load balancing using services like Elastic Load Balancer distributes traffic evenly and automatically reroutes requests if instances become unhealthy.
Auto Scaling is another critical component for maintaining reliability. Engineers must understand how to configure dynamic scaling policies based on metrics such as CPU utilization or request count. Predictive scaling can also be used to anticipate traffic patterns and prepare resources proactively.
Disaster recovery planning involves creating strategies to recover data and services quickly in case of catastrophic failure. Candidates should know different recovery strategies such as backup and restore, pilot light, warm standby, and multi-site active-active. Automating snapshots, cross-region replication, and failover processes ensures business continuity with minimal downtime.
Reliability also involves data durability and consistency. Engineers should know how to design storage systems using services like S3 with versioning, lifecycle policies, and replication. Databases can use automated backups and multi-AZ deployments to maintain availability. Understanding how to balance performance, cost, and reliability is essential.
The certification also emphasizes testing recovery strategies. Candidates should be familiar with chaos engineering principles, where controlled failures are introduced to evaluate system resilience. Regular testing ensures that automated recovery mechanisms work effectively and that systems remain stable under stress.
Exam Mastery and Strategic Preparation
Preparing for the AWS Certified DevOps Engineer Professional exam requires more than theoretical study. It demands applied understanding of AWS services, practical hands-on experience, and the ability to think architecturally.
A strong preparation strategy involves building and managing real-world projects. Setting up CI/CD pipelines, deploying multi-tier architectures, and automating infrastructure provides valuable practical insights. Each experiment enhances understanding of how different AWS components interact in real scenarios.
Another key aspect is understanding service integrations. The exam often presents complex scenarios where multiple services must work together to achieve operational goals. Knowing how to connect CodePipeline with CloudFormation, integrate monitoring tools with automation workflows, or link IAM with security automation can significantly improve performance in scenario-based questions.
Time management is also critical during the exam. The questions are complex and scenario-driven, requiring careful reading and logical deduction. Practicing with sample exams and whitepapers helps build familiarity with question patterns. Candidates should focus on identifying keywords that signal what aspect of AWS architecture is being tested.
A methodical mindset during preparation ensures better retention and understanding. Grouping services by functionality—such as automation, monitoring, security, and scaling—helps create mental frameworks that make it easier to recall relevant solutions.
Hands-on labs, AWS documentation, and architectural best practices are the most effective learning resources. Reviewing case studies of real AWS implementations helps bridge the gap between theoretical knowledge and practical problem-solving.
The AWS Certified DevOps Engineer Professional certification represents mastery in building automated, secure, and resilient AWS environments. It validates deep knowledge across automation, security, monitoring, and reliability domains. The certification demonstrates the ability to design systems that deliver software efficiently, recover quickly from failures, and maintain compliance automatically.
Professionals who earn this certification are recognized for their capability to integrate development and operations using advanced AWS tools and methodologies. They can orchestrate infrastructure as code, manage continuous delivery pipelines, and maintain visibility across complex distributed systems. This certification not only measures technical skill but also reflects strategic thinking in designing systems that evolve seamlessly with business demands. It establishes the professional as a leader in automation-driven cloud operations, capable of managing the full lifecycle of modern AWS architectures with confidence and precision.
Advanced Infrastructure as Code and Deployment Strategies
The AWS Certified DevOps Engineer Professional exam emphasizes mastering Infrastructure as Code and deployment automation as key aspects of maintaining scalability, consistency, and reliability in cloud environments. Infrastructure as Code allows engineers to define and manage entire environments through code templates instead of manual configurations. This approach ensures repeatable, version-controlled deployments and significantly reduces operational risk.
AWS CloudFormation and the AWS Cloud Development Kit are central tools for this purpose. CloudFormation uses templates written in JSON or YAML to describe resources such as VPCs, EC2 instances, IAM roles, and databases. The AWS Cloud Development Kit allows developers to define the same infrastructure using programming languages, providing flexibility and better integration with existing development workflows. Candidates preparing for the exam must understand how to design, deploy, and update CloudFormation stacks efficiently, handle stack drift detection, and manage dependencies among resources.
Infrastructure as Code also supports governance and compliance. Automated provisioning guarantees that security configurations remain consistent across multiple accounts. Engineers can embed tagging policies, encryption settings, and access control configurations within templates. This ensures compliance requirements are automatically enforced. The certification expects candidates to understand how to use StackSets to manage multiple accounts and regions simultaneously and to design pipelines that automatically apply validated infrastructure templates across environments.
Deployment strategies are equally important. The exam tests deep knowledge of different deployment methodologies and when to use them. Blue/green deployments reduce downtime by running two environments, switching traffic to the new version only after it is validated. Rolling deployments replace instances in batches, maintaining availability throughout. Canary deployments release new versions to a subset of users to minimize the impact of potential issues. Understanding these strategies and implementing them through AWS CodeDeploy, Elastic Beanstalk, or ECS is crucial.
Advanced deployment automation includes integrating AWS CodePipeline with CloudFormation or Lambda for custom workflows. This enables complex deployments such as multi-region rollouts or cross-service updates without manual oversight. Candidates must know how to configure automated rollbacks, ensuring that in case of deployment failure, systems revert to a stable state seamlessly. The ability to integrate testing and approval stages into pipelines demonstrates readiness for production-grade automation.
Continuous Monitoring, Logging, and Performance Optimization
In modern DevOps environments, monitoring and logging are the backbone of operational excellence. The AWS Certified DevOps Engineer Professional exam focuses on understanding how to implement continuous monitoring and observability for proactive system management. Effective monitoring helps detect anomalies early, optimize resource usage, and maintain reliability across distributed systems.
Amazon CloudWatch is the central service for collecting and analyzing operational metrics. Engineers must understand how to create custom dashboards, configure alarms, and analyze trends. Custom metrics can monitor application-specific data such as request latency, error rates, and transaction throughput. By visualizing key performance indicators, teams can identify patterns, plan scaling strategies, and prevent issues before they affect users.
AWS X-Ray complements CloudWatch by providing distributed tracing. It enables engineers to track requests across microservices, identify slow components, and detect performance bottlenecks. Understanding trace maps and segment details helps pinpoint where latency occurs, whether in application code, database queries, or network communication. The certification tests knowledge of integrating X-Ray with services like Lambda, ECS, and API Gateway to achieve full-stack visibility.
Centralized logging is essential for auditing and troubleshooting. AWS CloudTrail records all API actions, offering an audit trail for governance and compliance. CloudWatch Logs aggregates logs from diverse sources such as applications, containers, and system components. Candidates should know how to configure log retention, search patterns, and create metric filters to trigger alerts based on specific log events. Automating log analysis with AWS Lambda or third-party tools further enhances efficiency.
Performance optimization ties closely to monitoring insights. Engineers are expected to apply data-driven tuning by analyzing usage trends and resource utilization. This includes resizing instances, adjusting scaling thresholds, or improving caching strategies. Auto Scaling and Elastic Load Balancing ensure systems respond dynamically to load changes, maintaining performance without manual adjustments.
Cost optimization also plays a part in performance management. Candidates should know how to use AWS Cost Explorer and Trusted Advisor to identify underused resources and optimize budgets. Efficient monitoring ensures performance goals are met while keeping operational costs aligned with business objectives.
Security Integration and Automation Across DevOps Workflows
Security is deeply integrated into every domain of the AWS Certified DevOps Engineer Professional certification. It is no longer an afterthought but a continuous process embedded within development, deployment, and operational pipelines. This integration ensures that every change in code, infrastructure, or configuration adheres to security standards automatically.
Identity and Access Management is fundamental to securing AWS environments. Engineers must know how to implement fine-grained access controls using IAM roles, policies, and permission boundaries. Service-linked roles provide secure automation by granting only the necessary permissions to AWS services. Candidates should also understand the concept of temporary credentials and cross-account access to support automated deployments across multiple environments.
AWS Config plays a vital role in maintaining compliance and governance. It continuously monitors resource configurations and detects deviations from approved baselines. Automated remediation actions can be configured using Systems Manager or Lambda, ensuring immediate correction of policy violations. This capability supports continuous compliance by embedding security directly into the operational fabric.
Encryption and data protection form another key area. AWS Key Management Service enables centralized management of encryption keys, while AWS Secrets Manager and Parameter Store securely manage sensitive credentials. Automated rotation of keys and secrets ensures that security hygiene remains consistent without manual effort. Understanding how to integrate encryption with services such as S3, RDS, and EBS is essential for protecting data across all layers.
Integrating security within CI/CD pipelines strengthens overall governance. Tools such as AWS CodePipeline allow for security scans and policy checks to be inserted at every stage of deployment. If a code commit or infrastructure change violates a security rule, the pipeline automatically halts the process, preventing unsafe deployments. Candidates must know how to use static code analysis, dependency scanning, and vulnerability assessments as part of continuous delivery.
Automated threat detection and response represent advanced DevSecOps maturity. AWS services like GuardDuty, Security Hub, and Macie provide intelligent insights into potential threats. EventBridge or CloudWatch can trigger automatic remediation workflows in response to these alerts, isolating affected resources or applying stricter network rules. Designing these automated defense mechanisms showcases expertise in secure cloud operations.
The certification also evaluates understanding of incident response. Candidates must know how to create structured workflows for identifying, analyzing, and resolving security incidents. Using AWS Systems Manager Incident Manager, engineers can coordinate alerts, assign tasks, and automate escalation. This reduces response time and ensures consistent handling of critical security events.
Reliability Engineering and Fault Tolerance
Reliability ensures that systems remain operational even under unpredictable circumstances. The AWS Certified DevOps Engineer Professional exam tests knowledge of designing fault-tolerant architectures that recover quickly from failures and maintain performance during load spikes.
High availability begins with designing systems across multiple Availability Zones. This approach isolates failures, ensuring that even if one zone becomes unavailable, others continue serving requests. Load balancing using Application or Network Load Balancers distributes incoming traffic intelligently, reducing pressure on individual instances. Engineers must understand how to configure health checks, listener rules, and target groups to ensure smooth traffic management.
Auto Scaling provides elasticity by adjusting capacity dynamically based on defined metrics. Engineers should know how to configure scaling policies that respond to demand changes, ensuring applications remain responsive without overprovisioning. Predictive scaling further enhances this by forecasting traffic patterns and preparing resources in advance.
Data durability is equally vital. Storage solutions like Amazon S3 offer features such as cross-region replication and versioning, which safeguard data against accidental deletions or regional outages. Databases like Amazon RDS and DynamoDB provide multi-AZ replication and automated backups. Understanding how to configure these options ensures minimal data loss and fast recovery during disruptions.
Disaster recovery strategies must align with business continuity goals. The certification tests understanding of different recovery models, including backup and restore, pilot light, warm standby, and active-active architectures. Candidates are expected to design automation that supports these strategies using CloudFormation, Route 53 failover routing, and cross-region replication. Automated failover mechanisms ensure that when one environment fails, traffic shifts seamlessly to a standby region.
Testing reliability mechanisms is also important. Engineers should implement chaos testing and recovery drills to validate fault tolerance. Regularly testing backup restoration, failover processes, and auto-recovery scripts ensures readiness for real incidents. The ability to automate such tests demonstrates maturity in maintaining operational reliability.
Strategic Exam Preparation and Professional Growth
Preparing for the AWS Certified DevOps Engineer Professional certification requires not only understanding AWS services but also mastering how they integrate to form cohesive, automated workflows. This exam challenges professionals to think beyond technical tasks and consider system design, operational scalability, and continuous improvement.
A strategic preparation plan should combine theoretical study with practical application. Candidates should practice building complete CI/CD pipelines, automating infrastructure, and simulating real-world scenarios involving scaling, failure recovery, and security enforcement. Hands-on experimentation builds intuition for how AWS services behave under different conditions.
Studying whitepapers, service documentation, and architectural best practices deepens conceptual understanding. The exam expects candidates to justify design choices, so it is important to understand trade-offs between cost, performance, and reliability. Reviewing case studies helps illustrate how AWS tools solve complex operational challenges in real environments.
Mock exams and scenario-based questions provide valuable practice. They help identify knowledge gaps and improve time management. The questions often present complex architectures requiring multi-step reasoning. Developing a methodical approach to reading questions, identifying key objectives, and eliminating incorrect options improves accuracy and confidence.
Developing a mental framework for AWS services is another powerful technique. Grouping services by functionality—such as compute, automation, security, or monitoring—helps recall relevant tools quickly during the exam. Understanding how these services connect ensures efficient problem-solving when faced with integrated scenarios.
Beyond the exam, earning the certification enhances professional credibility. It signifies the ability to design and operate automated systems that meet enterprise-grade requirements. Professionals holding this certification are often trusted to lead DevOps transformations, design secure cloud architectures, and optimize operational processes. The skills gained extend beyond exam preparation, equipping individuals to manage complex cloud ecosystems with precision and confidence.
The AWS Certified DevOps Engineer Professional certification validates advanced expertise in automation, security, reliability, and operational efficiency. It represents a deep understanding of how to build, deploy, and manage modern AWS environments that are scalable, fault-tolerant, and secure. The exam challenges professionals to demonstrate not only technical competence but also architectural insight and strategic thinking.
Achieving this certification signifies the ability to unify development and operations under a single automated framework. It showcases mastery in building CI/CD pipelines, enforcing governance, and designing resilient architectures. It also highlights proficiency in applying continuous monitoring, automated recovery, and integrated security across all layers of AWS infrastructure.
This certification is more than a technical milestone; it reflects an engineer’s ability to think systematically and lead automation-driven initiatives that support business agility. Through disciplined preparation and practical application, candidates develop the knowledge to manage dynamic AWS environments with confidence and efficiency, paving the way for growth in advanced cloud engineering and operational leadership roles.
Advanced Automation and Continuous Delivery Practices
The AWS Certified DevOps Engineer Professional exam places significant emphasis on mastering automation, particularly in the areas of continuous integration and continuous delivery. Automation is at the heart of modern DevOps, ensuring that every stage of the development lifecycle—from code integration to deployment—happens efficiently, securely, and consistently. The exam tests an individual’s ability to implement and manage automated pipelines that allow applications to be released rapidly without sacrificing quality or stability.
Automation in the AWS environment relies heavily on services such as AWS CodePipeline, AWS CodeBuild, and AWS CodeDeploy. These tools work together to create robust CI/CD pipelines that automate build, test, and deployment processes. Understanding how to design such pipelines is fundamental to success in the exam. A typical setup includes CodePipeline orchestrating the workflow, CodeBuild compiling the application and running tests, and CodeDeploy handling deployment to different environments such as EC2, Lambda, or ECS.
Beyond simple automation, candidates must understand how to integrate validation and rollback mechanisms within these pipelines. Automated testing frameworks ensure that each code change is validated through unit, integration, and performance testing before moving to production. Rollbacks allow failed deployments to revert automatically to the last known stable version, maintaining application reliability. The ability to configure these processes demonstrates deep operational understanding, which is critical for the exam.
Infrastructure provisioning is another domain where automation plays a vital role. Using AWS CloudFormation or the AWS Cloud Development Kit, engineers define resources through code, ensuring that environments remain consistent across deployments. Automation in infrastructure ensures reproducibility and eliminates manual errors, which are common in traditional configuration management. Engineers should also understand how to integrate infrastructure provisioning within CI/CD pipelines so that infrastructure updates deploy alongside application code.
Automation also extends to system monitoring, scaling, and recovery. AWS services such as Auto Scaling, Lambda, and EventBridge can trigger automatic actions based on predefined thresholds or events. For example, an increase in application load may automatically initiate the provisioning of additional resources. Similarly, failure detection mechanisms can trigger recovery workflows or replacement of unhealthy instances. These automated responses are integral to maintaining high availability and resilience—key topics in the AWS Certified DevOps Engineer Professional exam.
Monitoring, Observability, and Continuous Improvement
Continuous monitoring and observability are essential components of operational excellence, forming another major focus area in the AWS Certified DevOps Engineer Professional exam. Monitoring ensures that applications, systems, and infrastructure perform optimally and that issues are detected early. Observability extends this by enabling engineers to understand not only that an issue exists but also why it occurred.
Amazon CloudWatch is the cornerstone of AWS monitoring. Candidates must know how to configure CloudWatch metrics, logs, and alarms to track the performance of applications and infrastructure. CloudWatch can gather data from compute instances, containers, serverless functions, and storage systems, providing a unified view of operational health. Creating dashboards and setting up anomaly detection enables proactive monitoring, allowing teams to identify irregularities before they escalate into major incidents.
AWS X-Ray is equally important for tracing application behavior. It helps developers and operations teams understand the flow of requests through distributed systems, highlighting performance bottlenecks or latency issues between services. Knowledge of integrating X-Ray with ECS, Lambda, or API Gateway allows engineers to achieve end-to-end visibility of applications. The certification expects candidates to interpret trace maps, identify problematic components, and propose optimization strategies based on performance data.
CloudTrail adds another layer by recording all API activity across AWS accounts. It is vital for audit trails, compliance verification, and security analysis. The exam evaluates a candidate’s ability to use CloudTrail alongside CloudWatch Logs to correlate events and detect anomalies. For example, unexpected configuration changes or unauthorized access patterns can trigger alerts and initiate automated responses.
Beyond basic monitoring, observability requires synthesizing data from multiple sources. Engineers must understand how to collect, analyze, and visualize operational data to identify long-term trends and areas for improvement. Integrating AWS services with external analytics tools or using Amazon OpenSearch Service for log analysis helps in uncovering root causes of performance degradation.
Continuous improvement depends on feedback loops derived from observability data. By analyzing performance metrics and operational outcomes, teams can refine their automation processes, improve deployment strategies, and optimize configurations. This cycle of measurement, analysis, and refinement lies at the core of DevOps maturity and is a fundamental concept tested in the exam.
Security Automation and Governance in AWS Environments
Security automation is a critical part of the AWS Certified DevOps Engineer Professional exam. It emphasizes embedding security controls directly into automation workflows to maintain compliance and protect infrastructure at every stage of the development lifecycle. The goal is to make security an integral part of operations rather than an afterthought.
Identity and access management forms the foundation of AWS security. Candidates should be adept at implementing IAM policies, roles, and permission boundaries that enforce the principle of least privilege. Automation ensures that access controls are consistently applied across accounts and resources. By integrating IAM roles into pipelines, only authorized processes can deploy changes or modify infrastructure configurations.
Encryption of data at rest and in transit is another important focus. Understanding how to use AWS Key Management Service for managing encryption keys, along with services such as Secrets Manager and Parameter Store, ensures that sensitive data is protected automatically. Candidates are expected to design automation that rotates credentials, rotates encryption keys, and ensures compliance with data protection policies.
Automated auditing and compliance verification are equally essential. AWS Config continuously monitors resource configurations and compares them against predefined compliance rules. When a deviation is detected, automated remediation can be triggered using AWS Systems Manager or Lambda. For example, if a storage bucket becomes publicly accessible, a rule can automatically revoke public permissions. Such automation not only improves security posture but also reduces human intervention and error.
The certification also tests understanding of proactive threat detection. AWS services like GuardDuty, Macie, and Security Hub provide continuous monitoring for malicious activity or misconfigurations. Integrating these tools with automation workflows allows immediate remediation actions. For instance, an alert from GuardDuty might automatically isolate a compromised instance or block suspicious IP addresses using security groups or network ACLs.
Incident response automation further strengthens system resilience. Candidates must demonstrate the ability to create structured workflows that handle detection, containment, and recovery automatically. Using EventBridge or Systems Manager Incident Manager, engineers can define rules that respond to specific events, ensuring consistent and timely mitigation. This approach aligns with the exam’s focus on operational excellence and reliability.
Security automation ensures that every deployment and configuration adheres to governance policies. Embedding security into pipelines guarantees that applications remain compliant by design. The certification evaluates how well candidates integrate these controls into automated environments, emphasizing preventive rather than reactive security.
Operational Resilience and Fault Tolerance
The AWS Certified DevOps Engineer Professional exam expects candidates to design architectures that maintain performance and availability despite unexpected failures or traffic surges. Operational resilience involves implementing mechanisms that anticipate disruptions and recover automatically without impacting users.
High availability begins with multi-AZ and multi-region architectures. Candidates should understand how to design redundant systems that remain functional even when an entire zone or region experiences issues. Load balancing using Application or Network Load Balancers distributes traffic evenly across instances, ensuring consistent user experiences. Engineers must configure health checks, listener rules, and target groups effectively to maintain seamless traffic routing.
Auto Scaling enables systems to adapt dynamically to changes in demand. Candidates should know how to define scaling policies that trigger based on metrics such as CPU usage or request counts. Predictive scaling can anticipate traffic patterns and adjust resources ahead of demand spikes. Understanding these mechanisms helps maintain application stability and cost efficiency.
Data durability is another critical factor in operational resilience. Storage services like Amazon S3 provide cross-region replication and versioning, ensuring that data remains protected even in catastrophic events. Databases such as RDS and DynamoDB offer automated backups, multi-AZ replication, and failover capabilities. Knowledge of these features is essential for designing resilient architectures.
Disaster recovery strategies form a key component of the exam. Candidates must understand recovery models such as backup and restore, pilot light, warm standby, and multi-site active-active. Implementing automation for these strategies using CloudFormation and Route 53 ensures fast and consistent recovery when needed. The ability to automate failover routing and recovery testing demonstrates practical resilience expertise.
Testing reliability mechanisms is equally important. Engineers must regularly validate failover processes and backup recovery to ensure readiness. Implementing chaos testing, where controlled failures are introduced to test system robustness, helps uncover weaknesses before they cause real outages. Automation of these tests ensures that reliability is continuously verified without manual effort.
Exam Strategy and Long-Term Career Value
The AWS Certified DevOps Engineer Professional certification requires both technical knowledge and strategic thinking. It challenges candidates to combine automation, security, reliability, and monitoring into cohesive systems that deliver continuous improvement and operational excellence.
A disciplined approach to exam preparation involves combining hands-on experience with conceptual study. Building CI/CD pipelines, automating infrastructure, and troubleshooting real AWS scenarios develop practical skills essential for success. Studying architectural best practices, documentation, and operational case studies deepens understanding of service interactions and trade-offs.
Mock exams and scenario-based questions help candidates build analytical skills. These questions often describe complex architectures requiring multi-step reasoning. Practicing with these scenarios enhances the ability to identify core issues quickly and apply the most effective AWS solutions. Time management is also critical during the exam; understanding how to prioritize questions and manage the clock can significantly influence results.
Earning the certification demonstrates mastery of advanced cloud operations and automation. It validates the ability to lead large-scale DevOps transformations, implement secure and resilient systems, and optimize processes for speed and efficiency. This recognition not only strengthens technical credibility but also positions professionals for leadership roles in cloud engineering and operations management.
Beyond certification, the knowledge gained empowers professionals to drive innovation within their organizations. It enhances their ability to build systems that scale effortlessly, recover quickly, and adapt to evolving business needs. The AWS Certified DevOps Engineer Professional exam encourages a mindset of continuous improvement—an essential trait for success in modern technology environments.
Advanced Deployment Strategies and Infrastructure as Code
The AWS Certified DevOps Engineer Professional exam assesses a deep understanding of deployment automation and the use of infrastructure as code to maintain consistency across environments. These are among the most critical components of an effective DevOps strategy because they enable rapid delivery of features while ensuring reliability and repeatability.
Infrastructure as code allows infrastructure to be managed through scripts or templates instead of manual provisioning. Using AWS CloudFormation or the AWS Cloud Development Kit, infrastructure components such as EC2 instances, load balancers, databases, and networking configurations can be defined in declarative templates. This approach ensures every environment is consistent, reduces configuration drift, and allows easy rollback to previous versions when needed. Automation of these templates allows developers and operations teams to create and destroy environments quickly, a key requirement for the AWS DevOps Engineer Professional exam.
Engineers must understand how to design reusable, modular templates that integrate with CI/CD pipelines. A well-structured template defines resources using parameters, mappings, and outputs, making it adaptable across environments like development, staging, and production. Nested stacks and macros help maintain large deployments efficiently. The exam expects familiarity with implementing infrastructure updates using change sets and handling stack failures using rollback configurations.
Deployment strategies form another major area of focus. Techniques like blue-green deployment, rolling deployment, and canary deployment minimize downtime and reduce risk during updates. Blue-green deployment involves maintaining two separate environments: one currently serving traffic and another with the new version. After validation, traffic is switched using load balancers or DNS updates. This approach ensures zero downtime and immediate rollback capability. Rolling deployments gradually update instances one at a time, maintaining service availability throughout the process. Canary deployments release updates to a small subset of users before expanding to the full user base, allowing early detection of issues.
Automation of these strategies using AWS CodeDeploy, CodePipeline, and Elastic Beanstalk ensures consistency and speed. For example, CodeDeploy can manage blue-green deployments with EC2 or ECS while integrating with Auto Scaling groups to handle scaling operations. Engineers must understand how to define deployment groups, lifecycle event hooks, and health check configurations to automate transitions between application versions. The certification tests how well candidates can orchestrate such deployments with minimal manual intervention.
Serverless deployment automation is equally important. AWS Lambda, when combined with services like API Gateway and Step Functions, supports event-driven architectures that scale automatically. Infrastructure as code can define and manage these serverless components, enabling rapid release cycles. Understanding how to build, package, and deploy Lambda-based applications through CodePipeline or SAM (Serverless Application Model) is crucial for exam success.
Conclusion
The AWS Certified DevOps Engineer Professional certification represents a deep understanding of how automation, monitoring, security, and resilience come together to create efficient cloud ecosystems. It validates the skills needed to manage complex AWS environments with precision and adaptability. Preparing for and achieving this certification requires not only technical expertise but also strategic insight into system design and operational excellence.
Those who earn it demonstrate proficiency in building automated pipelines, enforcing governance through code, implementing continuous monitoring, and ensuring fault-tolerant systems. It highlights an engineer’s ability to deliver stability, scalability, and performance through intelligent automation. By mastering the principles tested in this exam, professionals become capable of leading DevOps initiatives that drive reliability, efficiency, and continuous innovation in cloud infrastructure management.
Amazon AWS DevOps Engineer Professional practice test questions and answers, training course, study guide are uploaded in ETE Files format by real users. Study and Pass AWS DevOps Engineer Professional AWS DevOps Engineer - Professional (DOP-C01) certification exam dumps & practice test questions and answers are to help students.
Exam Comments * The most recent comment are on top
- AWS Certified Generative AI Developer - Professional AIP-C01
- AWS Certified Solutions Architect - Associate SAA-C03
- AWS Certified Solutions Architect - Professional SAP-C02
- AWS Certified AI Practitioner AIF-C01
- AWS Certified Cloud Practitioner CLF-C02
- AWS Certified Security - Specialty SCS-C03
- AWS Certified Machine Learning Engineer - Associate MLA-C01
- AWS Certified CloudOps Engineer - Associate SOA-C03
- AWS Certified Data Engineer - Associate DEA-C01
- AWS Certified DevOps Engineer - Professional DOP-C02
- AWS Certified Advanced Networking - Specialty ANS-C01
- AWS Certified Developer - Associate DVA-C02
- AWS Certified Security - Specialty SCS-C02
- AWS Certified SysOps Administrator - Associate - AWS Certified SysOps Administrator - Associate (SOA-C02)
- AWS Certified Machine Learning - Specialty - AWS Certified Machine Learning - Specialty (MLS-C01)
Why customers love us?
What do our customers say?
The resources provided for the Amazon certification exam were exceptional. The exam dumps and video courses offered clear and concise explanations of each topic. I felt thoroughly prepared for the AWS DevOps Engineer Professional test and passed with ease.
Studying for the Amazon certification exam was a breeze with the comprehensive materials from this site. The detailed study guides and accurate exam dumps helped me understand every concept. I aced the AWS DevOps Engineer Professional exam on my first try!
I was impressed with the quality of the AWS DevOps Engineer Professional preparation materials for the Amazon certification exam. The video courses were engaging, and the study guides covered all the essential topics. These resources made a significant difference in my study routine and overall performance. I went into the exam feeling confident and well-prepared.
The AWS DevOps Engineer Professional materials for the Amazon certification exam were invaluable. They provided detailed, concise explanations for each topic, helping me grasp the entire syllabus. After studying with these resources, I was able to tackle the final test questions confidently and successfully.
Thanks to the comprehensive study guides and video courses, I aced the AWS DevOps Engineer Professional exam. The exam dumps were spot on and helped me understand the types of questions to expect. The certification exam was much less intimidating thanks to their excellent prep materials. So, I highly recommend their services for anyone preparing for this certification exam.
Achieving my Amazon certification was a seamless experience. The detailed study guide and practice questions ensured I was fully prepared for AWS DevOps Engineer Professional. The customer support was responsive and helpful throughout my journey. Highly recommend their services for anyone preparing for their certification test.
I couldn't be happier with my certification results! The study materials were comprehensive and easy to understand, making my preparation for the AWS DevOps Engineer Professional stress-free. Using these resources, I was able to pass my exam on the first attempt. They are a must-have for anyone serious about advancing their career.
The practice exams were incredibly helpful in familiarizing me with the actual test format. I felt confident and well-prepared going into my AWS DevOps Engineer Professional certification exam. The support and guidance provided were top-notch. I couldn't have obtained my Amazon certification without these amazing tools!
The materials provided for the AWS DevOps Engineer Professional were comprehensive and very well-structured. The practice tests were particularly useful in building my confidence and understanding the exam format. After using these materials, I felt well-prepared and was able to solve all the questions on the final test with ease. Passing the certification exam was a huge relief! I feel much more competent in my role. Thank you!
The certification prep was excellent. The content was up-to-date and aligned perfectly with the exam requirements. I appreciated the clear explanations and real-world examples that made complex topics easier to grasp. I passed AWS DevOps Engineer Professional successfully. It was a game-changer for my career in IT!


