- Home
- Amazon Certifications
- AWS Certified Solutions Architect - Professional AWS Certified Solutions Architect - Professional (SAP-C01) Dumps
Pass Amazon AWS Certified Solutions Architect - Professional Exam in First Attempt Guaranteed!


AWS Certified Solutions Architect - Professional Premium File
- Premium File 1019 Questions & Answers. Last Update: Jul 07, 2026
Whats Included:
- Latest Questions
- 100% Accurate Answers
- Fast Exam Updates








Last Week Results!
All Amazon AWS Certified Solutions Architect - Professional certification exam dumps, study guide, training courses are Prepared by industry experts. PrepAway's ETE files povide the AWS Certified Solutions Architect - Professional AWS Certified Solutions Architect - Professional (SAP-C01) practice test questions and answers & exam dumps, study guide and training courses help you study and pass hassle-free!
Inside the AWS Solutions Architect Professional Exam: Key Topics and Structure
The AWS Certified Solutions Architect - Professional Exam is designed to assess a candidate’s ability to design and deploy complex systems on AWS that are scalable, resilient, secure, and cost-efficient. This certification is an advanced step for those who already have experience with cloud architecture and wish to demonstrate their expertise in handling large-scale and mission-critical AWS environments. The exam evaluates the ability to make architectural decisions that balance business, technical, and operational needs while adhering to best practices and the AWS Well-Architected Framework.
At this level, understanding AWS architecture goes beyond knowing which service to use. It involves knowing how different services integrate to form a cohesive, automated, and adaptive environment. Candidates are expected to demonstrate the capability to design hybrid and multi-account solutions, migrate large workloads to AWS, and optimize cloud environments for performance and cost.
The exam covers multiple domains, including designing for organizational complexity, cost optimization, continuous improvement, and compliance management. It tests how well an architect can transform complex business requirements into scalable and reliable cloud solutions.
Designing Complex Architectures on AWS
A core skill for success in the AWS Certified Solutions Architect - Professional Exam is the ability to design complex architectures that address diverse workloads. This includes multi-tier applications, distributed systems, and hybrid environments that integrate on-premises infrastructure with AWS. Candidates must understand how to design architectures that can handle unpredictable traffic patterns, ensure availability, and maintain consistency across distributed systems.
Designing multi-tier architectures requires familiarity with load balancing, caching, and asynchronous communication. AWS Elastic Load Balancing ensures even distribution of traffic, while Amazon CloudFront improves latency by caching content closer to users. Services like Amazon SQS and SNS decouple system components, allowing for greater fault tolerance and scalability. Together, these elements create systems that can grow or shrink based on demand without service disruption.
Architects must also focus on building architectures that support global reach and fault isolation. Using multiple Availability Zones and Regions, systems can be designed to withstand failures without affecting users. Multi-Region deployments can enhance disaster recovery strategies, providing both high availability and data durability.
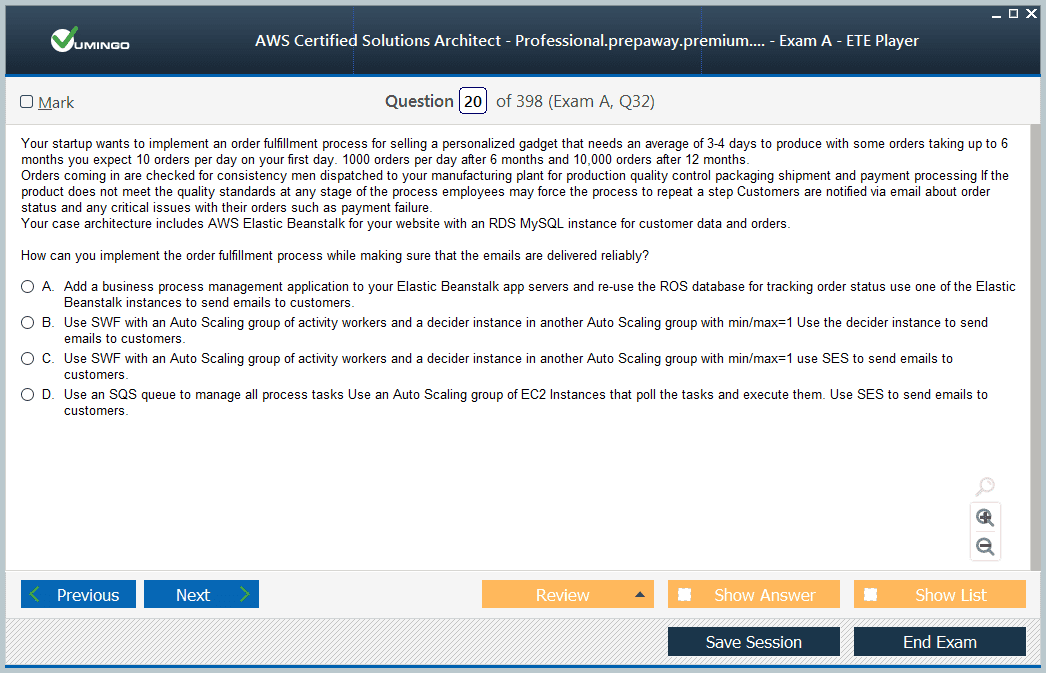
Another critical aspect is automation. Using services like AWS CloudFormation and AWS CDK enables consistent deployment and management of infrastructure as code. This approach reduces human error, enhances repeatability, and simplifies updates or rollbacks. Automation is essential for scaling architectures and maintaining compliance in dynamic environments.
Security, Governance, and Compliance
Security is a cornerstone of any AWS architecture. In the AWS Certified Solutions Architect - Professional Exam, candidates must demonstrate the ability to design secure systems that meet organizational and regulatory requirements. This involves controlling access, encrypting data, auditing activity, and implementing defense-in-depth strategies.
Identity and Access Management is foundational to AWS security. Architects must understand how to apply the principle of least privilege, implement roles and permissions correctly, and use temporary credentials to minimize risk. In large organizations, managing access across multiple accounts can be simplified with AWS Organizations and Service Control Policies, ensuring consistent governance across the environment.
Data protection is achieved through encryption and access controls. AWS Key Management Service allows centralized control of encryption keys and integrates with services like S3, RDS, and EBS for seamless encryption at rest. Data in transit should be secured using TLS, managed through AWS Certificate Manager. Compliance can be enforced through AWS Config and CloudTrail, which track resource configurations and user activities for auditing and governance.
Network security is equally important. Designing secure VPC architectures involves using Security Groups, Network ACLs, and private subnets to restrict exposure. Implementing AWS PrivateLink and Transit Gateway ensures secure communication between VPCs and on-premises systems. Advanced designs may include intrusion detection systems, web application firewalls, and DDoS protection with AWS Shield.
Monitoring and auditing complete the security framework. AWS CloudWatch, CloudTrail, and GuardDuty work together to provide continuous visibility and automated response mechanisms. These tools help detect anomalies and maintain compliance without manual intervention.
Cost-Effective Design and Optimization
A defining feature of a professional-level architect is the ability to create cost-efficient architectures without compromising performance or reliability. The AWS Certified Solutions Architect - Professional Exam emphasizes understanding pricing models, resource utilization, and cost-control mechanisms.
Cost optimization begins with selecting the right instance types and purchasing models. Reserved Instances and Savings Plans offer predictable workloads at lower costs, while Spot Instances can handle flexible or fault-tolerant tasks. Auto Scaling ensures that only necessary resources are running, preventing waste during low-demand periods.
Storage optimization also plays a major role. Architects must choose the correct storage class based on access patterns. Amazon S3 offers multiple classes like Standard, Intelligent-Tiering, and Glacier for long-term archiving. Lifecycle policies automate transitions between these classes, maintaining balance between cost and performance.
Databases are another area where optimization is crucial. Choosing the right database engine and configuration affects both cost and scalability. Amazon Aurora provides high availability and performance at a lower cost than traditional commercial databases. For unpredictable workloads, DynamoDB’s on-demand mode ensures cost-effectiveness by charging only for actual read and write operations.
Architects must also design for data transfer efficiency. Using CloudFront reduces outbound data transfer from the origin servers, while VPC endpoints allow private connectivity to AWS services without incurring public data transfer charges. Cost allocation tags and AWS Budgets provide ongoing visibility into resource usage, enabling proactive adjustments before costs escalate.
Performance and Scalability Management
High performance and scalability are integral to AWS solutions. The exam expects candidates to understand how to architect systems that maintain performance under varying loads and ensure a smooth user experience globally.
Designing for scalability involves using distributed and decoupled architectures. By leveraging services like Amazon SQS and SNS, systems can manage large-scale asynchronous communication between components. Amazon Kinesis and AWS Lambda handle real-time data processing at scale without manual intervention.
Caching is another performance enhancer. CloudFront caches content at the edge, reducing latency for end users. ElastiCache for Redis or Memcached stores frequently accessed data in memory, reducing database load. Caching at multiple layers, including application and network, ensures fast response times and reduced dependency on backend systems.
Monitoring plays a vital role in maintaining performance. CloudWatch metrics and alarms provide insights into system health, allowing dynamic scaling decisions. AWS X-Ray helps trace performance bottlenecks in distributed applications. Proper monitoring ensures that performance remains consistent even as demand fluctuates.
Designing for scalability also includes implementing elastic data storage. Amazon Aurora, DynamoDB, and S3 all scale automatically with demand. Understanding partitioning, indexing, and sharding strategies is crucial for handling large datasets efficiently.
To further enhance performance, architects can use placement groups, enhanced networking, and compute-optimized instance types for high-performance workloads. For content-heavy applications, integrating AWS Global Accelerator directs users to the nearest endpoint, improving responsiveness and reliability.
Automation and Continuous Improvement
Automation is a fundamental principle of modern cloud architecture. The AWS Certified Solutions Architect - Professional Exam evaluates how well candidates can use automation to enhance reliability, efficiency, and agility in AWS environments.
Automation begins with infrastructure deployment. CloudFormation and AWS CDK allow architects to define infrastructure in code, ensuring that every environment is consistent and version-controlled. Systems Manager automates patch management, backup scheduling, and configuration compliance. This reduces manual intervention and operational overhead.
Continuous integration and continuous deployment pipelines can be built using AWS CodePipeline, CodeBuild, and CodeDeploy. These services automate software delivery, ensuring faster and more reliable releases. Integrating monitoring and rollback strategies into pipelines further enhances resilience.
Event-driven architectures are another form of automation. Using services like AWS Lambda and EventBridge, architects can trigger actions in response to system events, creating adaptive and self-healing systems. For example, automatic scaling, resource tagging, or policy enforcement can be handled dynamically based on predefined rules.
Automation also supports continuous improvement. By analyzing CloudWatch metrics and Trusted Advisor recommendations, architects can identify opportunities for optimization. Automated cost reports, security scans, and compliance checks ensure that environments evolve in line with best practices.
Real-World Application and Exam Preparation
Mastering the AWS Certified Solutions Architect - Professional Exam requires more than memorizing facts. It demands hands-on experience with complex AWS environments. The exam scenarios often reflect real-world business challenges, requiring the application of design principles to dynamic problems.
Building practical experience is essential. Candidates should practice deploying architectures involving multiple AWS services, such as multi-tier web applications, serverless systems, and hybrid connectivity models. Creating prototypes or test environments helps solidify understanding of how components interact.
Another effective preparation method is exploring failure scenarios. Understanding how to recover from instance failures, service outages, or misconfigurations builds the intuition needed for designing resilient systems. Disaster recovery planning using S3, Glacier, and cross-region replication is a common test area.
Reviewing AWS whitepapers, best practices, and case studies provides insights into the reasoning behind AWS architectural guidelines. The Well-Architected Framework is particularly valuable, as it defines the standards by which AWS evaluates system design.
Exam success also depends on developing decision-making skills under time constraints. The scenarios presented often have multiple correct answers, but only one represents the most efficient and well-architected choice. Practicing this analytical approach helps in selecting solutions that align with AWS principles.
The AWS Certified Solutions Architect - Professional Exam validates a candidate’s ability to design robust, scalable, and secure architectures for complex AWS environments. Success in this certification requires a deep understanding of AWS services, architectural best practices, and real-world design strategies.
Candidates must demonstrate mastery over topics such as network design, security, cost optimization, performance tuning, and automation. Each decision within an architecture should contribute to overall efficiency, compliance, and business value.
By continuously refining skills, experimenting with different architectures, and understanding how AWS services interact at scale, professionals can become capable of designing advanced cloud solutions that support innovation and long-term stability. The knowledge gained while preparing for this certification not only enhances technical expertise but also strengthens the ability to make informed, strategic architectural decisions that drive success in cloud environments.
Deep Dive into Advanced AWS Architectural Design
The AWS Certified Solutions Architect - Professional Exam requires a comprehensive understanding of how to design complex, enterprise-level architectures that are secure, scalable, and optimized for performance. At this level, candidates are tested on their ability to handle multifaceted challenges that span across multiple AWS accounts, hybrid infrastructures, and distributed systems. This exam goes beyond service-level knowledge; it evaluates how well you can combine various AWS technologies to create efficient, resilient, and automated solutions that meet business and technical goals.
To perform well, candidates must be proficient in designing architectures that adapt to organizational needs while maintaining compliance and operational efficiency. It demands the ability to assess trade-offs between performance, cost, and manageability, ensuring every decision aligns with AWS best practices. Understanding the interdependencies between networking, storage, compute, and security layers is essential. This knowledge enables architects to create systems that function seamlessly under high demand and in diverse operational scenarios.
Building Enterprise-Grade Solutions on AWS
Designing enterprise-level solutions involves the integration of multiple AWS services into cohesive systems that can handle large-scale workloads. Architects must think in terms of modular components that work together without creating bottlenecks or single points of failure. The focus should be on flexibility and automation, allowing the system to evolve as business needs change.
A typical enterprise architecture might include multiple VPCs connected through AWS Transit Gateway to enable secure communication between business units. This setup allows centralized governance while maintaining resource isolation. Using AWS Organizations, architects can define policies that enforce compliance and security across multiple accounts. Service Control Policies ensure consistent permissions and prevent accidental resource misuse.
In large environments, managing network architecture effectively is critical. Implementing hybrid connectivity through AWS Direct Connect and VPNs allows seamless communication between on-premises and cloud resources. Architects must design these connections to ensure low latency, high availability, and redundancy. Route 53 can be used for intelligent routing, directing users to the most optimal endpoints based on latency or geographic location.
Architects must also focus on workload distribution and disaster recovery strategies. Deploying across multiple Availability Zones or Regions ensures high availability, while automated failover mechanisms safeguard against disruptions. Using S3 for cross-region replication and databases like Aurora Global Database provides real-time data synchronization across geographically distant locations.
Security Architecture and Identity Management
Security design is an essential component of the AWS Certified Solutions Architect - Professional Exam. Candidates must understand how to protect every layer of an architecture through identity management, encryption, network segmentation, and compliance monitoring. A well-architected security model ensures that data and applications remain protected even as the system scales.
Identity and Access Management is central to securing AWS environments. Instead of assigning permissions directly to users, architects should design role-based access control using IAM roles and groups. Temporary credentials issued by Security Token Service reduce long-term risk exposure. For large-scale deployments, AWS Single Sign-On simplifies identity federation across accounts and applications.
Data security begins with encryption. AWS Key Management Service handles key creation, rotation, and lifecycle management, while integrated services like S3, EBS, and RDS automatically encrypt data at rest. Data in transit must be secured using TLS, managed through AWS Certificate Manager. Sensitive workloads may require client-side encryption or hardware-based key management for additional control.
Network security extends beyond firewall rules. Designing isolated subnets for critical workloads, using private endpoints for service access, and implementing intrusion detection with GuardDuty are key practices. AWS WAF and Shield protect against external attacks, while Network Firewall enables advanced traffic inspection and segmentation.
Monitoring and logging provide visibility into operations. CloudTrail records all API activity, enabling audits and forensic analysis. Config continuously evaluates configurations against compliance standards. Combining these services with CloudWatch metrics ensures that any anomalies trigger alerts and automated responses.
Optimizing for Scalability and Resilience
Scalability and resilience are defining characteristics of well-architected AWS systems. The AWS Certified Solutions Architect - Professional Exam evaluates how effectively candidates design for changing workloads while maintaining performance and fault tolerance.
Scalability begins with decoupling. Breaking down monolithic applications into microservices allows each component to scale independently. Using services like Amazon SQS, SNS, and EventBridge, architects can create asynchronous communication between components, reducing dependencies and improving reliability.
For compute scalability, EC2 Auto Scaling groups automatically add or remove instances based on demand. When paired with Elastic Load Balancing, this ensures consistent performance even during traffic spikes. Serverless technologies like Lambda and Fargate further simplify scaling by eliminating infrastructure management altogether.
Storage solutions must also scale efficiently. S3 provides virtually unlimited capacity for object storage, while EFS supports shared file access across multiple instances. Database scaling is handled through mechanisms like Aurora replicas and DynamoDB partitioning. Understanding how to design read and write scaling strategies, caching layers, and data replication models is crucial.
Resilience focuses on preventing and recovering from failures. Multi-AZ deployments ensure that critical resources remain available during outages. Automated backup and recovery strategies, cross-region replication, and disaster recovery drills ensure business continuity. Building self-healing systems through automation, where failed components are automatically replaced, is a hallmark of professional-level architecture.
Cost and Performance Optimization Strategies
Balancing cost and performance is one of the most challenging aspects of cloud architecture. The AWS Certified Solutions Architect - Professional Exam emphasizes the ability to design systems that meet performance objectives while minimizing operational expenses.
Cost efficiency begins with selecting the right pricing models. Reserved Instances and Savings Plans work best for predictable workloads, while Spot Instances offer savings for flexible or batch processing tasks. Architects should design workloads that can gracefully handle interruptions when using Spot Instances.
Storage cost management involves matching data to the appropriate storage class. S3 Intelligent-Tiering automatically moves data between classes based on usage patterns. Using lifecycle policies ensures that infrequently accessed data transitions to Glacier or Deep Archive for long-term retention. EBS volumes should be right-sized, and snapshots should be automated and cleaned up regularly to prevent waste.
For performance, architects must identify and eliminate bottlenecks. Load balancing, caching, and data partitioning help distribute workloads efficiently. Using ElastiCache reduces latency for frequently accessed data, while CloudFront accelerates global content delivery. Databases can be optimized through query tuning, indexing, and sharding.
Monitoring cost and performance continuously is key to optimization. AWS Trusted Advisor and Compute Optimizer offer recommendations for improving resource utilization. CloudWatch dashboards provide visibility into metrics that affect performance, allowing adjustments in real time. Well-structured tagging and cost allocation reports help organizations understand where spending occurs and identify opportunities for improvement.
Automation and Operational Excellence
Automation forms the backbone of scalable, reliable, and consistent AWS operations. The AWS Certified Solutions Architect - Professional Exam requires candidates to understand how to automate infrastructure, deployment, monitoring, and recovery processes to reduce human error and enhance system efficiency.
Infrastructure as Code is the foundation of automation in AWS. CloudFormation and AWS CDK allow architects to define entire environments in reusable templates. This ensures consistency across deployments and simplifies rollback in case of errors. Using version control with infrastructure templates enhances traceability and compliance.
Automation extends into operations through Systems Manager, which handles routine administrative tasks such as patching, configuration updates, and compliance checks. EventBridge can trigger automated responses to system changes or security findings, reducing the need for manual intervention.
Continuous integration and delivery pipelines improve development agility. AWS CodePipeline, CodeBuild, and CodeDeploy work together to automate software testing and deployment, ensuring that updates are delivered quickly and reliably. These pipelines can integrate with CloudWatch and Lambda for post-deployment validation and rollback mechanisms.
Automated recovery is another key aspect of operational excellence. By combining health checks with Route 53 failover routing and Auto Scaling policies, systems can detect failures and restore functionality automatically. Implementing chaos engineering practices helps test system resilience and validate recovery processes.
Designing for Hybrid and Multi-Account Environments
As organizations grow, their AWS presence often spans multiple accounts and environments. The AWS Certified Solutions Architect - Professional Exam expects candidates to understand how to design architectures that operate seamlessly across these boundaries.
Multi-account strategies enhance security and resource management. Using AWS Organizations, architects can create account hierarchies that separate workloads, environments, and teams. Centralized billing and Service Control Policies provide governance while allowing autonomy within accounts.
For hybrid architectures, connectivity between on-premises systems and AWS must be secure and efficient. AWS Direct Connect provides a dedicated link for high-performance data transfer, while VPN connections offer encrypted communication over the internet. Transit Gateway and PrivateLink simplify network connectivity between accounts and VPCs, creating a unified network fabric.
Data synchronization between environments is achieved using AWS DataSync, Storage Gateway, or database replication services. These tools ensure that applications operate consistently regardless of where the data resides. Hybrid designs often combine on-premises storage or compute with AWS-based analytics and automation.
Centralized logging and monitoring across accounts are essential for governance. Aggregating CloudTrail logs and CloudWatch metrics enables visibility and compliance tracking. AWS Control Tower provides a framework for setting up and managing secure multi-account environments efficiently.
Continuous Learning and Real-World Application
Achieving mastery in AWS architecture requires continuous learning and practical application. The AWS Certified Solutions Architect - Professional Exam tests not only theoretical understanding but also the ability to translate knowledge into real-world solutions.
Hands-on experience is the most effective way to build confidence. Setting up test environments with complex use cases, such as multi-tier web applications, data analytics pipelines, and serverless integrations, helps reinforce architectural principles. Experimenting with automation tools, scaling configurations, and network designs ensures deeper understanding.
Studying AWS whitepapers, architectural best practices, and service documentation provides valuable insights into how AWS expects systems to be designed. The Well-Architected Framework remains a key resource for assessing and improving architecture quality.
Simulating real-world scenarios enhances problem-solving skills. Testing failure recovery, performance scaling, and security audits under controlled conditions ensures readiness for both the exam and practical deployments. Developing architectural diagrams and justifying design choices also improves analytical thinking.
Collaboration and discussion further solidify knowledge. Engaging with peers to review solutions or share experiences offers diverse perspectives that expand understanding. Reviewing architectural trade-offs and comparing multiple design options helps refine decision-making skills essential for the exam.
The AWS Certified Solutions Architect - Professional Exam represents a high level of cloud architecture expertise. It measures the ability to design secure, scalable, and cost-optimized solutions that align with business and technical objectives. Success in this exam demonstrates mastery of AWS architecture and the capacity to manage complex, distributed systems effectively.
Preparing for this certification involves developing an in-depth understanding of AWS services, practicing with real-world environments, and applying architectural principles to diverse scenarios. It requires analytical thinking, strategic design, and the ability to balance performance, security, and cost.
By combining theory with practical experience and continuously improving design skills, architects can build systems that not only meet certification standards but also deliver lasting value in real-world environments. This level of expertise transforms professionals into leaders capable of guiding organizations toward innovation, efficiency, and operational excellence in the cloud.
Deep Dive into the AWS Certified Solutions Architect - Professional Exam
The AWS Certified Solutions Architect - Professional exam is one of the most advanced and challenging certifications in the AWS ecosystem. It validates the ability to design complex, scalable, secure, and cost-optimized architectures on AWS. This certification is not only about knowing AWS services but also about applying architectural best practices, understanding trade-offs, and making decisions that align with business and technical requirements. The exam tests a candidate’s capability to analyze problems from multiple perspectives, integrating knowledge across networking, compute, storage, databases, and security domains. To excel, one must think like an architect, not just a technician.
Core Domains and Exam Structure
The exam focuses on four main domains: design for organizational complexity, design for new solutions, migration planning, and cost control. Each domain covers advanced topics that require in-depth understanding of AWS services, their integration, and their operational impact. It is designed for individuals who already have hands-on experience designing distributed systems on AWS at a professional level. The ability to connect multiple AWS components into a unified, high-performing, and secure architecture is essential. Unlike associate-level exams that test foundational knowledge, this exam challenges you to reason through scenarios involving hybrid environments, multi-account setups, and governance considerations.
Understanding the structure of the exam is crucial for effective preparation. It includes multiple-choice and multiple-response questions that often present real-world architectural scenarios. Each question tests not just technical knowledge but also judgment and reasoning ability. You must interpret requirements, constraints, and priorities, then select the optimal design decision. Reading comprehension and critical analysis play as much of a role as technical proficiency, so practicing scenario-based questions is vital.
Designing for Organizational Complexity
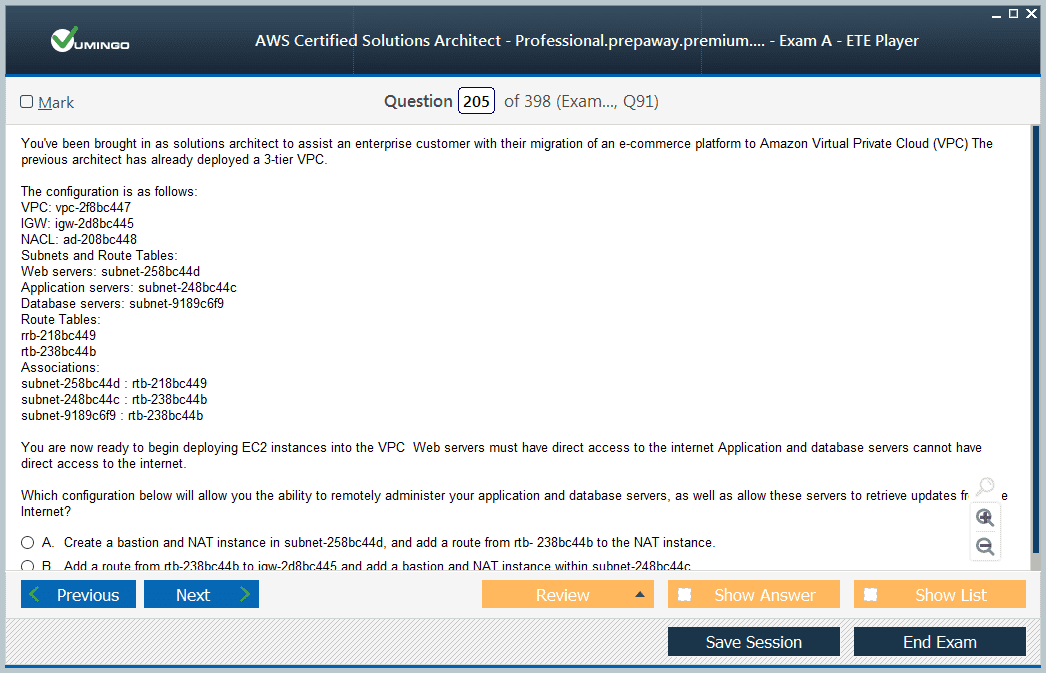
A major theme of the AWS Certified Solutions Architect - Professional exam is managing complexity in large, multi-account environments. Many organizations operate with multiple AWS accounts connected through AWS Organizations. Candidates must understand how to design account hierarchies, manage permissions with Service Control Policies, and maintain secure boundaries between business units while allowing centralized governance.
Networking complexity also arises when designing solutions that span multiple VPCs or regions. Knowing how to use AWS Transit Gateway, VPC peering, and PrivateLink to ensure secure, efficient connectivity is key. You must be able to evaluate different networking architectures based on scalability, security, and cost considerations. The exam expects familiarity with advanced networking topics like hybrid DNS resolution, centralized ingress and egress control, and cross-region replication.
Another important concept in this domain is centralized identity and access management. The ability to design IAM policies, roles, and permission boundaries that scale across hundreds of accounts is a core skill. You may also encounter questions about integrating AWS with external identity providers using SAML or OpenID Connect. Understanding how to design federated access across complex infrastructures is critical for success.
Designing for New Solutions
This domain tests the candidate’s ability to create architectures that meet new business requirements. You need to evaluate functional and non-functional needs, design for scalability, performance, reliability, and security, and select appropriate AWS services. Each decision should demonstrate a balance between agility, resilience, and cost-effectiveness.
For compute services, you must know how to choose between EC2, ECS, EKS, Lambda, and other compute models. Understanding auto-scaling strategies, container orchestration, and serverless design patterns helps ensure that architectures adapt dynamically to workload demands. Similarly, storage design questions may involve combining multiple services like S3, EFS, and FSx for different access patterns and durability needs.
Database architecture plays a significant role as well. Candidates must be able to differentiate between Amazon RDS, DynamoDB, Aurora, Redshift, and other database offerings, and know how to design architectures that integrate transactional and analytical workloads efficiently. High availability, read scaling, and data consistency strategies are common focus areas.
Another key aspect of this domain involves designing for application integration using services like Amazon SQS, SNS, EventBridge, and Step Functions. Understanding decoupled architectures, asynchronous communication, and event-driven design is essential for building scalable, fault-tolerant systems. You may also be asked to design solutions that integrate with third-party APIs or legacy systems, demonstrating flexibility and architectural depth.
Migration Planning and Execution
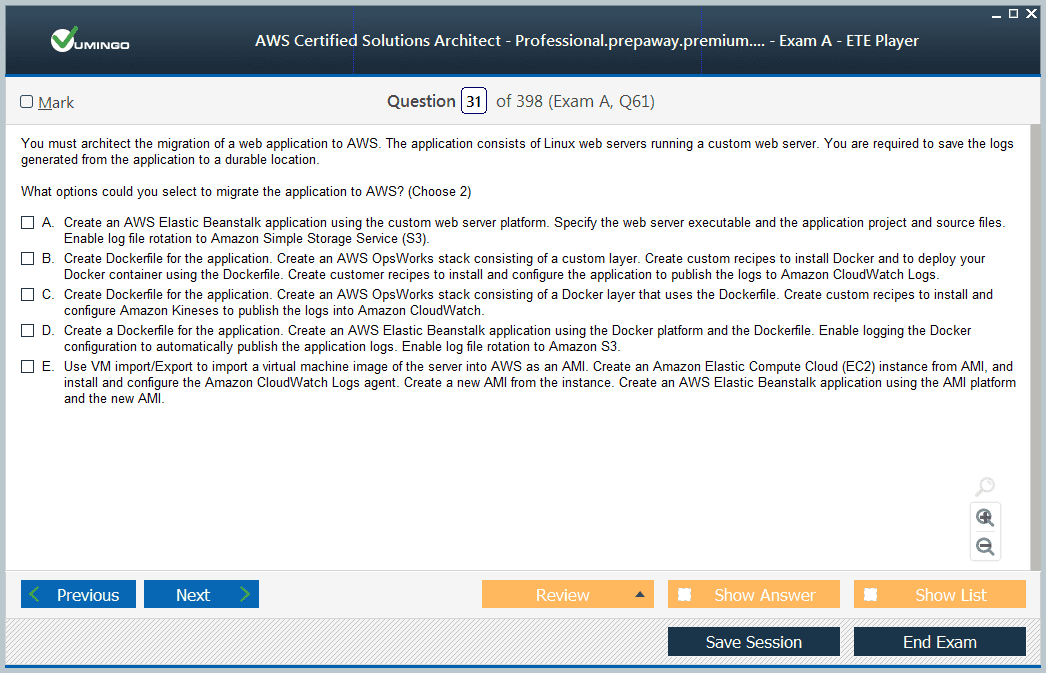
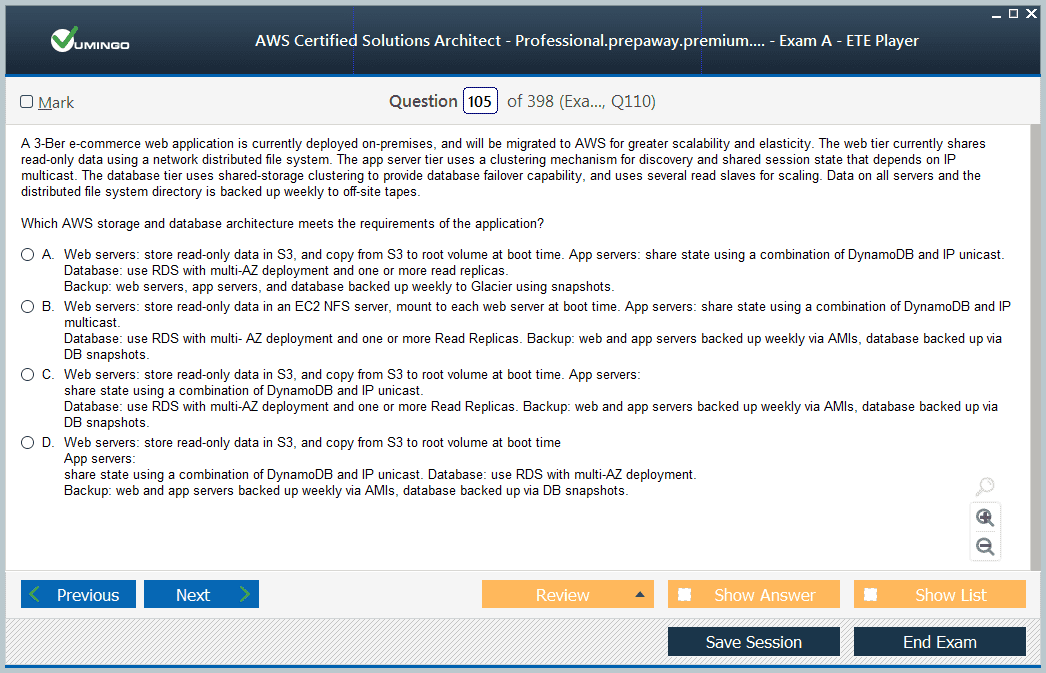
The professional-level exam often includes scenarios that involve migrating large-scale workloads to AWS. You must understand different migration strategies, such as rehost, replatform, refactor, and rearchitect, and know how to apply them based on business constraints and objectives. AWS Migration Hub, Application Discovery Service, and Database Migration Service are essential tools for this domain.
Candidates must also understand how to plan phased migrations and design hybrid architectures that maintain connectivity between on-premises data centers and AWS during transition. You might encounter questions involving Direct Connect, VPN connections, and hybrid DNS configurations. The ability to ensure minimal downtime and data integrity during migration is crucial.
Security during migration is another critical concern. Knowing how to implement encryption, IAM roles, and VPC security measures while transferring workloads ensures compliance and protection of data in transit. The exam also expects candidates to understand rollback and recovery strategies, especially for mission-critical systems.
Cost Optimization and Governance
Cost optimization is not just about minimizing expenses but also about aligning spending with business value. The exam tests your ability to design architectures that use AWS resources efficiently while maintaining performance and reliability. Candidates must be familiar with pricing models for compute, storage, and networking services, as well as tools like AWS Cost Explorer, Budgets, and Trusted Advisor.
Governance plays a large part in this domain. You must design frameworks that allow centralized visibility, control, and auditing across multiple accounts. AWS Control Tower, Config, and CloudTrail are key tools for implementing governance at scale. The exam often presents scenarios where cost control and governance intersect, such as enforcing tagging strategies or isolating development and production environments through account boundaries.
Another important concept is designing architectures for elasticity and right-sizing. Using auto-scaling, spot instances, and serverless services like Lambda can help achieve cost efficiency while maintaining flexibility. Candidates must demonstrate understanding of architectural trade-offs, such as when to use managed services versus self-managed ones, or how to choose between single-region and multi-region architectures based on cost and performance.
Security, Reliability, and Performance Considerations
Security is embedded throughout every domain of the exam. You must know how to design architectures that comply with AWS security best practices, including encryption at rest and in transit, least privilege access, and network isolation. Familiarity with AWS KMS, CloudHSM, and WAF is valuable, as is understanding secure patterns for cross-account data sharing and key management.
Reliability is equally important. Candidates need to know how to design systems that automatically recover from failures, maintain data integrity, and meet availability targets. Multi-AZ and multi-region designs are commonly tested. Understanding how to use Route 53, Global Accelerator, and CloudFront for high availability and global performance optimization is essential.
Performance optimization focuses on designing solutions that scale seamlessly with user demand while maintaining efficiency. You must understand caching strategies using CloudFront, ElastiCache, or DynamoDB Accelerator, and design architectures that minimize latency through intelligent data placement and networking choices.
Advanced Architectural Scenarios
The AWS Certified Solutions Architect - Professional exam often presents complex, layered scenarios that combine multiple architectural considerations. You may need to design systems that handle millions of users globally, comply with strict security requirements, and maintain operational resilience under varying loads.
Candidates must demonstrate understanding of distributed design patterns such as microservices, event-driven architectures, and data lakes. Knowledge of automation tools like CloudFormation and AWS CDK is also important, as infrastructure as code enables consistent, repeatable deployments. Designing CI/CD pipelines using CodePipeline, CodeBuild, and CodeDeploy helps ensure operational excellence and maintainability.
You may also encounter questions involving edge computing, IoT solutions, or data analytics pipelines. These scenarios test your ability to integrate different AWS services into cohesive, efficient architectures. The key is to approach each problem methodically: understand requirements, identify constraints, evaluate service options, and select the most appropriate solution.
Preparation Strategy and Study Approach
Preparing for the AWS Certified Solutions Architect - Professional exam requires both theoretical understanding and extensive hands-on experience. Reviewing the AWS Well-Architected Framework helps build a solid foundation in best practices. Focus particularly on the five pillars: operational excellence, security, reliability, performance efficiency, and cost optimization.
Hands-on practice is indispensable. Experimenting with real AWS environments allows you to understand service interactions and limitations that are difficult to grasp from documentation alone. Building sample architectures, deploying workloads, and troubleshooting configurations can strengthen conceptual understanding.
Reviewing whitepapers and AWS documentation deepens your insight into design principles. Key documents include the AWS Well-Architected Framework, security best practices, and cost optimization strategies. Online labs and practice exams are also valuable tools to identify weak areas and improve test-taking skills.
Time management during the exam is crucial. The questions are lengthy and scenario-based, requiring analytical reading. It’s best to flag uncertain questions and revisit them later rather than spending too much time on one.
The Path to Mastery
Achieving the AWS Certified Solutions Architect - Professional certification demonstrates more than technical skill. It shows the ability to think strategically, make sound architectural decisions, and design solutions that balance performance, cost, and security. It distinguishes professionals who understand how to translate business goals into robust cloud architectures that scale with growth and adapt to change.
Success in this certification requires discipline, persistence, and curiosity. Each domain interconnects, forming a holistic view of cloud architecture. The ability to evaluate trade-offs, apply best practices, and justify design decisions based on context is what defines an AWS Professional-level architect. The exam is a reflection not only of what you know but also of how you approach complex architectural challenges.
By mastering these concepts and applying them through hands-on experience, candidates position themselves as trusted cloud architects capable of leading large-scale AWS transformations. The AWS Certified Solutions Architect - Professional exam is not just an assessment but a comprehensive validation of your ability to design for the future of the cloud.
Mastering Advanced Design Strategies for the AWS Certified Solutions Architect - Professional Exam
The AWS Certified Solutions Architect - Professional exam evaluates a candidate’s ability to design, deploy, and manage sophisticated cloud architectures that meet complex business needs. Success in this exam depends on a deep understanding of AWS services, the ability to analyze architectural trade-offs, and the skill to align technology with business goals. To excel, you must be able to integrate scalability, performance, security, and cost efficiency into a unified design framework. This level of certification demands a mindset shift from implementation to architectural strategy, requiring you to think beyond individual services and focus on holistic system design.
Advanced Architecture Design and Integration
At the professional level, architecture design extends beyond the boundaries of single applications or environments. The exam challenges you to design solutions that function across multiple accounts, regions, and services. You must understand how to structure architectures that are resilient and adaptive to changing requirements.
One of the most critical aspects of advanced design is cross-region architecture. Designing systems that can tolerate regional failures while maintaining data consistency and availability is a frequent test scenario. You must be proficient in concepts such as active-active and active-passive designs, failover mechanisms using Route 53, and cross-region replication with services like S3, RDS, or DynamoDB. Knowing when to replicate data synchronously or asynchronously and understanding the trade-offs between consistency and latency are vital.
Another important area is hybrid architecture design. Many enterprises maintain workloads on-premises while extending functionality to AWS. This requires expertise in integrating on-premises infrastructure with cloud resources through VPN or Direct Connect, maintaining hybrid DNS configurations, and managing identity across hybrid environments. You must design for seamless interoperability while maintaining consistent security and governance policies.
Application Architecture and Performance Optimization
In the AWS Certified Solutions Architect - Professional exam, designing for performance is more than scaling up resources. It involves optimizing at every layer of the application architecture. You should be able to analyze workload characteristics and apply the right mix of compute, storage, and networking options to ensure responsiveness and efficiency.
For compute-intensive applications, you must understand when to use EC2 Auto Scaling groups, containerized workloads on ECS or EKS, and serverless architectures with Lambda. Each approach has its own cost, performance, and management considerations. For instance, choosing between Fargate and EC2 launch types depends on workload predictability, operational overhead, and scaling patterns. Similarly, performance optimization for EC2 includes selecting appropriate instance families, using Elastic Load Balancing, and distributing workloads across multiple Availability Zones.
Storage optimization also plays a significant role. You need to know how to balance performance and cost using various storage tiers, such as S3 Standard, S3 Intelligent-Tiering, and S3 Glacier. For applications requiring low-latency access, using EBS-optimized instances or employing caching mechanisms with ElastiCache can significantly improve throughput. File-based workloads might benefit from EFS or FSx, depending on performance and compatibility needs.
Performance architecture also includes database design. The exam frequently tests your ability to select appropriate database engines and scaling models. You may be asked to design architectures involving Aurora Global Database, DynamoDB with on-demand scaling, or Amazon Redshift for analytical processing. Mastery of caching strategies, read replicas, and partitioning techniques ensures that your database layer scales efficiently under heavy load.
Security Architecture and Compliance Design
Security remains central to every AWS design principle, and the professional-level exam expects you to demonstrate an expert understanding of how to integrate security across all layers of your architecture. It is not limited to setting up IAM policies or encrypting data; it involves designing security as an intrinsic part of your overall system.
You must be able to design for least privilege access at scale. This includes managing cross-account access using roles, designing permission boundaries, and integrating identity federation with external directories. IAM best practices become more complex when managing hundreds of users and resources across multiple accounts.
Data protection is another key focus area. You need to understand how to implement encryption both at rest and in transit using services like AWS KMS and CloudHSM. Knowing when to use customer-managed keys versus AWS-managed keys can affect compliance and operational overhead. Multi-layered encryption strategies that involve application-level and network-level encryption are also tested.
Network security architecture is equally vital. Candidates must design secure network perimeters using private subnets, security groups, and Network ACLs. Implementing centralized inspection and traffic control through Transit Gateway or Firewall Manager ensures consistent security enforcement. You may also encounter questions about designing secure API gateways, WAF rules, and load balancer configurations that prevent data exposure or unauthorized access.
In addition, compliance and governance considerations are integrated into security design. You must know how to use services such as AWS Config, CloudTrail, and Control Tower to enforce compliance and monitor policy violations. Architectures should also include centralized logging, automated alerting, and auditing mechanisms to ensure traceability and accountability.
Reliability and Resilience Design
A defining feature of professional-level architecture is reliability—the ability of systems to recover gracefully from failures and continue operating with minimal disruption. Designing for fault tolerance, redundancy, and disaster recovery is fundamental for this certification.
You must be able to build architectures that automatically detect and respond to failures. This involves designing self-healing systems using Auto Scaling, health checks, and automation workflows through CloudWatch alarms and Lambda functions. Resilient architecture also relies on distributing workloads across multiple Availability Zones and regions. Knowing how to design multi-region failover strategies, replicate data asynchronously, and perform automated failback operations is crucial.
High availability design also extends to databases and storage systems. You should understand how to design RDS Multi-AZ deployments, DynamoDB global tables, and EFS replication across regions. For critical applications, leveraging Amazon Route 53’s health-based routing ensures users are always directed to the nearest healthy endpoint.
Disaster recovery planning is a key component. You may be asked to design recovery architectures using strategies such as backup and restore, pilot light, warm standby, and multi-site active-active models. Each strategy has cost, complexity, and recovery time trade-offs that you must evaluate. Familiarity with services like AWS Backup, S3 Cross-Region Replication, and CloudEndure Disaster Recovery strengthens your ability to make informed decisions.
Cost Optimization and Operational Excellence
The AWS Certified Solutions Architect - Professional exam places strong emphasis on optimizing cost while maintaining performance and reliability. Cost optimization is not simply about reducing expenses but about designing architectures that maximize value.
One key aspect is using the right pricing models for compute and storage. You should understand when to use On-Demand, Reserved, and Spot Instances and how to combine them for balanced performance and savings. Architectures that dynamically scale down during low demand periods or use serverless services like Lambda can minimize idle resource costs.
Storage optimization also requires understanding data lifecycle management. Using S3 lifecycle policies to automatically transition objects between storage classes or archive data to Glacier helps control long-term storage costs. Additionally, designing data retention and deletion policies ensures compliance while avoiding unnecessary storage expenses.
Operational excellence is closely tied to cost and efficiency. You must be able to automate operational tasks using CloudFormation, AWS CDK, or OpsWorks. Infrastructure as code not only improves deployment consistency but also reduces operational errors. The exam also tests your ability to design monitoring and alerting frameworks using CloudWatch, X-Ray, and CloudTrail. These tools provide visibility into system performance and enable proactive response to potential issues.
A well-architected solution must also include governance controls that track and manage spending. You should be familiar with AWS Budgets, Cost Explorer, and tagging strategies for resource accountability. Implementing budget alerts and using consolidated billing under AWS Organizations can further optimize costs across accounts.
Migration and Transformation Strategies
Another advanced concept in the AWS Certified Solutions Architect - Professional exam is large-scale migration planning. Candidates must demonstrate the ability to design migration frameworks that ensure minimal disruption, data integrity, and consistent performance during transitions.
Migration planning starts with assessment and discovery. You must know how to analyze workloads, identify dependencies, and determine migration priorities. Using AWS Migration Hub, Application Discovery Service, and Database Migration Service helps streamline these processes. The exam also tests your ability to choose appropriate migration strategies, whether rehosting, replatforming, refactoring, or rebuilding.
Designing hybrid and transitional architectures is an important skill. During migration, workloads often operate in a hybrid state where on-premises and cloud systems coexist. You must ensure secure connectivity, consistent identity management, and unified monitoring across environments.
Once workloads are migrated, optimization becomes the next step. Post-migration tuning involves modernizing applications to leverage managed services, improving performance, and implementing automation. Continuous improvement is part of maintaining operational excellence in AWS.
Managing Multi-Account and Multi-Region Environments
Large-scale AWS environments often consist of multiple accounts and regions. The exam assesses your ability to design architectures that simplify management and maintain governance across such distributed systems.
Using AWS Organizations, you can structure accounts based on function or environment, applying Service Control Policies to enforce boundaries. Designing for centralized logging, security monitoring, and cost management across accounts is a key focus area. AWS Control Tower simplifies governance, but understanding manual multi-account setups remains critical.
In multi-region architectures, candidates must design for data sovereignty, latency optimization, and resilience. You should understand how to use global services like Route 53, CloudFront, and Global Accelerator to deliver low-latency experiences. Designing globally distributed databases and handling cross-region synchronization ensures both availability and data consistency.
Practical Exam Strategies
Mastering the AWS Certified Solutions Architect - Professional exam requires both conceptual understanding and strategic exam execution. Time management is essential because questions are complex and lengthy. Practice reading and summarizing long scenarios quickly to extract the key requirements, constraints, and success factors.
Focus on eliminating incorrect answers rather than immediately selecting the correct one. Many questions present multiple viable options, but only one aligns perfectly with AWS best practices. Understanding trade-offs between cost, performance, and reliability helps narrow your choices effectively.
Hands-on experience is irreplaceable. Theoretical knowledge is useful, but real-world practice deepens your understanding of service behavior and limitations. Building, testing, and troubleshooting multi-service architectures enhances your problem-solving ability.
Achieving Mastery as a Solutions Architect
Earning the AWS Certified Solutions Architect - Professional certification signifies mastery in designing advanced cloud solutions. It reflects not only deep technical expertise but also strategic thinking and business alignment. Certified professionals are trusted to design architectures that evolve with business needs, ensuring scalability, resilience, and efficiency.
The journey to achieving this certification develops an architect’s capacity to approach complex problems holistically. It trains you to evaluate technical possibilities, consider operational realities, and deliver solutions that drive business outcomes. Mastering the concepts in this exam transforms your approach to cloud architecture from implementation-level thinking to strategic leadership.
In the end, this certification represents more than technical validation—it signifies the ability to shape enterprise-level cloud solutions that deliver value, innovation, and growth. The AWS Certified Solutions Architect - Professional exam is not just a test of knowledge; it is a milestone in the evolution of an architect who designs for the future of cloud computing.
Designing Scalable and Adaptive Cloud Architectures for the AWS Certified Solutions Architect - Professional Exam
The AWS Certified Solutions Architect - Professional exam assesses your ability to design, implement, and manage complex cloud environments that meet demanding business objectives. To succeed, you must demonstrate deep understanding of scalability, elasticity, security, and resilience within large and interconnected systems. This certification measures not only your grasp of AWS services but also your capability to architect solutions that are optimized, fault-tolerant, and adaptable to change. Passing this exam requires you to think like an architect who anticipates growth, designs for evolution, and ensures that systems perform efficiently even under unpredictable workloads.
Advanced System Design and Integration Principles
At the professional level, the exam challenges candidates to think beyond single-service implementations and instead focus on designing ecosystems where multiple AWS services interact seamlessly. Advanced system design is about identifying dependencies, managing complexity, and ensuring that every component contributes to the system’s stability and performance.
Architects must know how to integrate compute, networking, storage, and database services effectively. Designing multi-tier architectures involves using services such as EC2, Elastic Load Balancing, and Auto Scaling in coordination with RDS or DynamoDB for data management. For microservices and containerized applications, knowledge of ECS, EKS, and Fargate becomes essential. Each of these services introduces different operational and performance characteristics, and an architect’s role is to select the optimal combination based on workload type and business constraints.
Another key element of integration is the use of decoupling patterns. Systems that rely on asynchronous communication through services like Amazon SQS, SNS, and EventBridge are more resilient and scalable. Decoupled architectures allow independent scaling of components, reducing the risk of cascading failures. The professional exam often evaluates your understanding of such distributed system patterns and your ability to design for minimal interdependence.
Service integration also involves the use of API Gateway and Lambda to build event-driven and serverless systems that minimize operational overhead. In these architectures, the focus shifts from managing infrastructure to designing event flows, concurrency management, and error handling. You must be able to design solutions that automatically recover from transient failures while maintaining consistency and responsiveness.
Designing for Reliability and Fault Tolerance
Reliability is a critical dimension of every architecture assessed in the AWS Certified Solutions Architect - Professional exam. Candidates must understand how to design systems that continue operating during component or service failures. This requires mastering redundancy, failover, and recovery strategies across all architectural layers.
Redundancy can be achieved by distributing workloads across multiple Availability Zones or even across regions. Architectures must be designed to withstand localized failures without affecting the user experience. Services like Amazon Route 53 enable intelligent traffic routing based on latency, health checks, or geographic location, ensuring high availability even during disruptions. For storage and database layers, using S3 Cross-Region Replication or RDS Multi-AZ configurations enhances durability and uptime.
A well-architected system must also implement fault detection and automated recovery. CloudWatch Alarms combined with Lambda functions can trigger automated healing processes, such as restarting failed instances or replacing unhealthy nodes in an Auto Scaling group. The exam often presents scenarios where you must identify the right balance between automation and manual intervention.
Disaster recovery design is another major topic. You must evaluate and choose appropriate strategies such as backup and restore, pilot light, warm standby, or multi-site active-active. Each approach has different recovery time objectives (RTO) and recovery point objectives (RPO), and part of the architect’s skill is aligning these metrics with business requirements while maintaining cost efficiency.
Building Secure and Compliant Architectures
Security design in AWS requires a deep understanding of layered defense strategies. In the professional exam, you are expected to design security solutions that integrate identity management, data protection, and network security without hindering system performance or scalability.
Identity and Access Management (IAM) forms the foundation of AWS security. Architects must be able to design role-based access controls that follow the principle of least privilege. Advanced scenarios may involve designing cross-account access using resource-based policies, role chaining, or identity federation with external directories. For large organizations, permission boundaries and service control policies under AWS Organizations provide centralized governance.
Data security extends beyond access control. Encryption at rest and in transit must be part of every design. AWS Key Management Service (KMS) and CloudHSM are essential tools for managing cryptographic operations. You should know when to use customer-managed keys versus AWS-managed keys, and how to integrate encryption seamlessly into data storage, database, and application layers.
Network security design involves securing traffic flow through multiple layers. Designing private subnets for sensitive workloads, configuring Network ACLs and Security Groups, and using VPC endpoints for private connectivity to AWS services are standard practices. Advanced architectures often include centralized inspection using AWS Network Firewall or third-party security appliances.
Monitoring and compliance are integral to security. AWS CloudTrail records all API actions for auditing, while Config continuously evaluates resource configurations. CloudWatch Logs and GuardDuty provide real-time threat detection and operational visibility. The exam tests your ability to combine these tools into an integrated monitoring framework that supports both proactive defense and reactive analysis.
Performance and Scalability Optimization
Architecting for performance and scalability requires designing systems that respond dynamically to varying workloads while maintaining consistent performance. The AWS Certified Solutions Architect - Professional exam evaluates how well you understand scaling mechanisms, caching strategies, and data flow optimization.
Compute scalability starts with the ability to automate provisioning. Auto Scaling groups ensure that workloads adjust capacity automatically based on demand. For containerized workloads, ECS and EKS provide service-level scaling, while Lambda manages scaling implicitly in serverless architectures. The challenge lies in configuring scaling thresholds, cooldowns, and policies that balance responsiveness with cost control.
Caching plays a major role in enhancing performance. Implementing CloudFront for edge caching reduces latency for global users, while ElastiCache accelerates data retrieval by storing frequently accessed information in memory. Knowing when and how to apply these caching strategies can drastically improve both performance and cost efficiency.
Database scalability involves designing architectures that handle high read or write volumes efficiently. Amazon Aurora and DynamoDB offer advanced scaling mechanisms such as read replicas, partitioning, and on-demand capacity modes. For analytics and reporting workloads, integrating data warehouses like Redshift or using data lakes on S3 can offload heavy queries from transactional databases.
Network performance optimization involves designing efficient routing and minimizing latency. Using Global Accelerator or Route 53 latency-based routing directs users to the nearest endpoint. Content delivery through CloudFront, combined with regional edge caches, ensures that applications maintain consistent speed even under high load.
Automation and Operational Excellence
Automation is a defining principle of modern cloud architecture. The AWS Certified Solutions Architect - Professional exam emphasizes automation as a tool for ensuring consistency, reducing human error, and enhancing scalability. You must understand how to leverage automation across deployment, monitoring, and maintenance processes.
Infrastructure as Code (IaC) forms the foundation of automation. Tools like AWS CloudFormation and the AWS Cloud Development Kit (CDK) allow architects to define infrastructure declaratively. This approach ensures reproducibility and simplifies complex deployments across multiple accounts and regions. The exam may test your ability to identify when to use nested stacks, stack sets, or parameterized templates to support organizational scalability.
Automating monitoring and maintenance tasks is equally important. AWS Systems Manager provides capabilities such as patch management, configuration compliance, and operational insights. Lambda functions can automate backup schedules, cleanup tasks, or failure recovery actions. Using automation for operational management enhances reliability and frees teams to focus on innovation.
Event-driven automation is another advanced concept. Combining CloudWatch Events, EventBridge, and Lambda enables architectures that respond automatically to changes in the environment. For instance, when a new EC2 instance is launched, automation can enforce security group policies or attach necessary IAM roles instantly.
Multi-Account and Multi-Region Governance
In large enterprise environments, managing multiple accounts and regions requires structured governance and coordination. The AWS Certified Solutions Architect - Professional exam includes scenarios where you must design governance frameworks that ensure security, compliance, and operational consistency at scale.
Using AWS Organizations, architects can group accounts based on business units or environments and apply Service Control Policies to regulate resource usage. Centralized billing and consolidated reports simplify financial management. Implementing tagging standards and resource naming conventions ensures traceability and facilitates cost tracking.
Multi-region architectures require balancing data locality, latency, and redundancy. Data replication across regions supports disaster recovery, while read replicas improve performance for geographically distributed users. You must understand how to design architectures that maintain data consistency while minimizing cross-region latency.
Centralized monitoring and management are crucial in such environments. Centralized logging using CloudWatch Logs or S3 allows unified visibility. Security monitoring tools like GuardDuty and Security Hub aggregate findings from multiple accounts, enabling faster detection and response to potential threats.
Data Management and Analytics Integration
The professional exam also evaluates your understanding of data management strategies that support both transactional and analytical workloads. Architects must design solutions that efficiently collect, store, and process data across different AWS services.
For structured data, Amazon RDS and Aurora remain primary choices. You must know how to design for scalability and availability using read replicas, Multi-AZ deployments, and automated backups. For unstructured or semi-structured data, Amazon S3 and DynamoDB provide flexible and scalable storage options.
Data analytics integration involves designing pipelines that extract, transform, and load data efficiently. Services like AWS Glue, Kinesis, and Data Pipeline automate data flow between operational systems and analytical platforms. Integrating data lakes on S3 with Redshift or Athena allows large-scale analysis without managing infrastructure directly.
Security and compliance in data management are also critical. Architects must ensure encryption, proper IAM access, and auditing. Data lifecycle management using S3 policies and Glacier archives ensures that data remains cost-efficient throughout its retention period.
Exam Strategy and Mindset
The AWS Certified Solutions Architect - Professional exam requires a strategic mindset and the ability to think through complex scenarios. It is not enough to know individual services; you must be able to connect them logically to achieve a desired business outcome.
Start by focusing on the question requirements and identifying key constraints such as performance, security, cost, or compliance. Eliminate answers that fail to meet mandatory requirements, then analyze trade-offs among the remaining choices. This analytical approach helps identify the most balanced solution based on AWS best practices.
Hands-on experience remains the best preparation. Building multi-service architectures in a real AWS environment helps reinforce theoretical concepts. Experiment with automation, disaster recovery, and multi-region replication to understand the operational behavior of systems.
Building Expertise and Confidence
Achieving success in the AWS Certified Solutions Architect - Professional exam represents more than mastering technical knowledge—it signifies the ability to design cloud solutions that are strategic, scalable, and sustainable. The process of preparing for this certification builds critical thinking, system-level understanding, and a problem-solving mindset that extends beyond AWS.
As you refine your expertise, focus on continuous learning and practical application. The AWS ecosystem evolves rapidly, and staying current with architectural best practices ensures long-term relevance. Real-world projects and continuous experimentation strengthen your ability to translate theoretical design principles into practical, high-impact solutions.
Mastering this certification demonstrates your ability to lead complex cloud initiatives and design architectures that drive innovation, reliability, and performance. It validates not only your technical depth but also your strategic understanding of how to use AWS to shape efficient and resilient digital infrastructures.
Building Enterprise-Grade Architectures
At the professional level, architecture design shifts from single-application considerations to multi-application ecosystems that span regions and business domains. Candidates must demonstrate how to design architectures that maintain consistency, performance, and security at scale. Enterprise-grade systems are characterized by their ability to handle unpredictable workloads, meet compliance requirements, and maintain operational visibility.
A well-architected solution at this level often integrates multiple compute environments such as EC2 instances, serverless functions, and containerized workloads. The ability to mix these computing models appropriately is critical. For example, architects must know when to use EC2 for stateful or highly customizable workloads, when to adopt Lambda for event-driven automation, and when to use EKS for orchestrating containerized microservices. Each of these options offers different scaling patterns, cost structures, and operational complexities. The professional exam evaluates your ability to select the right model for each use case while ensuring consistency across the entire system.
Another essential aspect of enterprise architecture is service isolation and separation of duties. Architectures must minimize interdependencies between components to reduce cascading failures. Using services like SQS, SNS, and EventBridge allows for asynchronous communication and decoupling, ensuring that system failures in one module do not disrupt others. Designing architectures around loosely coupled principles enables independent scaling, simplified maintenance, and better fault isolation.
Data management also plays a pivotal role in enterprise design. An effective architecture must balance performance, consistency, and cost. Amazon S3 is often used for object storage, but integrating it with services like Glacier for archival or CloudFront for content delivery requires strategic planning. In multi-tier applications, databases such as RDS, Aurora, and DynamoDB must be chosen based on access patterns and data consistency requirements. The exam tests your ability to design data flows that remain optimized across layers, ensuring minimal latency and high availability.
Designing for Business Continuity and Availability
One of the hallmarks of the AWS Certified Solutions Architect - Professional exam is its emphasis on designing resilient architectures that continue to function during disruptions. Candidates must understand how to design for both high availability and disaster recovery while minimizing downtime and data loss.
High availability begins with designing systems across multiple Availability Zones. For critical applications, redundancy at every layer is essential. Load balancers distribute traffic across healthy targets, while Auto Scaling automatically replaces unhealthy instances. Architectures must use multiple subnets and ensure that no single point of failure exists. The professional exam frequently evaluates your ability to detect and eliminate such vulnerabilities.
Disaster recovery strategies extend the concept of high availability by preparing for larger-scale failures, such as regional outages. Designing cross-region replication, using Route 53 for failover routing, and leveraging data replication technologies across services like S3, DynamoDB Global Tables, or RDS cross-region read replicas are essential skills. You must be able to identify the appropriate recovery strategy—backup and restore, pilot light, warm standby, or active-active—based on business priorities, cost constraints, and acceptable recovery times.
Automation enhances resilience by ensuring that recovery processes happen quickly and accurately. Using CloudFormation StackSets or AWS Systems Manager automation documents, recovery procedures can be codified and executed without human intervention. The ability to automate failover and restoration workflows is a key differentiator in demonstrating architectural maturity at the professional level.
Managing Cost Efficiency in Large-Scale Architectures
Cost optimization is a continuous concern in large-scale AWS environments. The professional exam tests your ability to design cost-efficient architectures that do not compromise on performance or reliability. Effective cost management requires a deep understanding of how AWS pricing models interact with architecture choices.
An architect must evaluate whether workloads should run on-demand, use reserved capacity, or leverage spot instances. Workloads with steady demand patterns often benefit from reserved instances or savings plans, while burstable or fault-tolerant workloads can utilize spot instances for significant cost reductions. For compute resources, the choice between EC2, ECS, and Lambda can also influence overall cost efficiency depending on workload characteristics and scaling behavior.
Storage optimization is equally critical. Choosing between storage classes in Amazon S3, such as Standard, Intelligent-Tiering, or Glacier, can significantly impact long-term costs. Similarly, designing efficient data lifecycle policies ensures that infrequently accessed data is automatically transitioned to cheaper storage tiers. For databases, selecting the right instance size, using read replicas, and leveraging Aurora Serverless can help align costs with usage patterns.
Networking costs can escalate quickly in distributed systems. Architects must understand how to minimize data transfer charges by using VPC endpoints, private connectivity, and caching mechanisms. Designing architectures that limit cross-region data movement and leverage CloudFront for content distribution ensures predictable and controlled costs.
Monitoring and optimization tools like AWS Cost Explorer and Trusted Advisor provide insights into spending patterns. Integrating these tools with operational workflows helps architects make informed decisions and continuously refine architecture for efficiency. The exam assesses how well you can balance these economic considerations with technical requirements to achieve an optimal outcome.
Final Words
Achieving the AWS Certified Solutions Architect - Professional certification signifies a deep mastery of designing, implementing, and managing advanced cloud systems on AWS. It validates not just technical knowledge but the ability to think strategically, applying architectural principles to complex, multi-layered environments. A certified architect demonstrates the capacity to design for scalability, resilience, and cost efficiency while maintaining strict security and governance standards. This certification also reflects a professional’s ability to balance innovation with reliability, ensuring that each architectural decision aligns with long-term business goals. Beyond the exam, it represents readiness to lead enterprise-level solutions, optimize performance, and guide organizations through successful cloud transformations with confidence and expertise.
Amazon AWS Certified Solutions Architect - Professional practice test questions and answers, training course, study guide are uploaded in ETE Files format by real users. Study and Pass AWS Certified Solutions Architect - Professional AWS Certified Solutions Architect - Professional (SAP-C01) certification exam dumps & practice test questions and answers are to help students.
Exam Comments * The most recent comment are on top
- AWS Certified Generative AI Developer - Professional AIP-C01
- AWS Certified Solutions Architect - Associate SAA-C03
- AWS Certified Solutions Architect - Professional SAP-C02
- AWS Certified AI Practitioner AIF-C01
- AWS Certified Cloud Practitioner CLF-C02
- AWS Certified Security - Specialty SCS-C03
- AWS Certified CloudOps Engineer - Associate SOA-C03
- AWS Certified Machine Learning Engineer - Associate MLA-C01
- AWS Certified DevOps Engineer - Professional DOP-C02
- AWS Certified Advanced Networking - Specialty ANS-C01
- AWS Certified Data Engineer - Associate DEA-C01
- AWS Certified Developer - Associate DVA-C02
- AWS Certified Security - Specialty SCS-C02
- AWS Certified SysOps Administrator - Associate - AWS Certified SysOps Administrator - Associate (SOA-C02)
Why customers love us?
What do our customers say?
The resources provided for the Amazon certification exam were exceptional. The exam dumps and video courses offered clear and concise explanations of each topic. I felt thoroughly prepared for the AWS Certified Solutions Architect - Professional test and passed with ease.
Studying for the Amazon certification exam was a breeze with the comprehensive materials from this site. The detailed study guides and accurate exam dumps helped me understand every concept. I aced the AWS Certified Solutions Architect - Professional exam on my first try!
I was impressed with the quality of the AWS Certified Solutions Architect - Professional preparation materials for the Amazon certification exam. The video courses were engaging, and the study guides covered all the essential topics. These resources made a significant difference in my study routine and overall performance. I went into the exam feeling confident and well-prepared.
The AWS Certified Solutions Architect - Professional materials for the Amazon certification exam were invaluable. They provided detailed, concise explanations for each topic, helping me grasp the entire syllabus. After studying with these resources, I was able to tackle the final test questions confidently and successfully.
Thanks to the comprehensive study guides and video courses, I aced the AWS Certified Solutions Architect - Professional exam. The exam dumps were spot on and helped me understand the types of questions to expect. The certification exam was much less intimidating thanks to their excellent prep materials. So, I highly recommend their services for anyone preparing for this certification exam.
Achieving my Amazon certification was a seamless experience. The detailed study guide and practice questions ensured I was fully prepared for AWS Certified Solutions Architect - Professional. The customer support was responsive and helpful throughout my journey. Highly recommend their services for anyone preparing for their certification test.
I couldn't be happier with my certification results! The study materials were comprehensive and easy to understand, making my preparation for the AWS Certified Solutions Architect - Professional stress-free. Using these resources, I was able to pass my exam on the first attempt. They are a must-have for anyone serious about advancing their career.
The practice exams were incredibly helpful in familiarizing me with the actual test format. I felt confident and well-prepared going into my AWS Certified Solutions Architect - Professional certification exam. The support and guidance provided were top-notch. I couldn't have obtained my Amazon certification without these amazing tools!
The materials provided for the AWS Certified Solutions Architect - Professional were comprehensive and very well-structured. The practice tests were particularly useful in building my confidence and understanding the exam format. After using these materials, I felt well-prepared and was able to solve all the questions on the final test with ease. Passing the certification exam was a huge relief! I feel much more competent in my role. Thank you!
The certification prep was excellent. The content was up-to-date and aligned perfectly with the exam requirements. I appreciated the clear explanations and real-world examples that made complex topics easier to grasp. I passed AWS Certified Solutions Architect - Professional successfully. It was a game-changer for my career in IT!


